
Intelligibility evaluation of enhanced whisper in joint time-frequency domain
2014-09-06 10:49:45ZhouJianWeiXinLiangRuiyuZhaoLi
Zhou Jian Wei Xin Liang Ruiyu Zhao Li
(1Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education, Anhui University, Hefei 230601, China)(2Key Laboratory of Underwater Acoustic Signal Processing of Ministry of Education, Southeast University, Nanjing 210096, China)(3College of Telecommunications and Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China)(4College of Computer and Information, Hohai University, Nanjing 210098, China)
?
Intelligibility evaluation of enhanced whisper in joint time-frequency domain
Zhou Jian1,2Wei Xin3Liang Ruiyu4Zhao Li2
(1Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education, Anhui University, Hefei 230601, China)(2Key Laboratory of Underwater Acoustic Signal Processing of Ministry of Education, Southeast University, Nanjing 210096, China)(3College of Telecommunications and Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China)(4College of Computer and Information, Hohai University, Nanjing 210098, China)
Some factors influencing the intelligibility of the enhanced whisper in the joint time-frequency domain are evaluated. Specifically, both the spectrum density and different regions of the enhanced spectrum are analyzed. Experimental results show that for a spectrum of some density, the joint time-frequency gain-modification based speech enhancement algorithm achieves significant improvement in intelligibility. Additionally, the spectrum region where the estimated spectrum is smaller than the clean spectrum, is the most important region contributing to intelligibility improvement for the enhanced whisper. The spectrum region where the estimated spectrum is larger than twice the size of the clean spectrum is detrimental to speech intelligibility perception within the whisper context.
whispered speech enhancement; intelligibility evaluation; real-valued discrete Gabor transform; joint time-frequency analysis
Recently, processing of whispered speech has received much attention[1-3]. Whisper is often used in public places where normal speech is not allowed or the speaker wants to avoid being overheard. Particularly, whisper is the only path to communication for aphonic individuals who cannot produce normal speech. An earlier study on whispers focused on phonetics and medical needs. With the rapid development of mobile communication technology, more attention has been paid to whisper applications such as whispers to normal speech transformation, whisper recognition, and whisper emotion analysis, etc.
A whisper is produced by a turbulent like excitation airflow from the lungs with no vocal cord vibration. The energy of whispered speech is much lower than that of normal speech. As a consequence, whispered speech is more susceptible to interference and canceling noise from whisper is a considerable challenge for whisper based applications in the noisy environment.
The aim of speech enhancement is to improve quality and/or intelligibility. Much progress has been made in improving speech quality in the past decade. However, there has been little progress in improving speech intelligibility[4]. Powerful speech enhancement algorithms such as the power subtraction method, the minimum mean-square error spectrum amplitude estimator method, and the Wiener method cannot improve speech intelligibility but even reduce it slightly[5-6].
The reasons why existing speech enhancement algorithms do not improve speech intelligibility is partially known. Loizou et al.[7]suggested that an over-estimation of speech in enhancement stage is a key factor in that the enhanced speech has no improvement in the aspect of intelligibility. Wang et al.[8]also found that the enhanced speech obtains greater intelligibility when the spectrum component where speech energy is larger than that of the noise spectrum is used to synthesize the enhanced speech[8]. However, these studies focused on voiced speech, and it is not clear whether these results follow in the context of whispers. Additionally, the effect of the density of spectrum used in speech algorithms on speech intelligibility is not considered in previous studies.
In this paper, we evaluate some factors affecting intelligibility of the enhanced whisper in the joint time-frequency domain. We first propose a joint time-frequency gain modification based speech enhancement algorithm where the real-valued discrete Gabor transform (RDGT) is used to obtain the time-frequency spectrum of different densities. The inspiration for using the RDGT rather than the short time Fourier transform is that the former has the ability to extract different levels of the speech spectrum density in the joint time-frequency domain with a simple parameter. Different levels of spectrum and speech over-estimation are evaluated and analyzed for their effect on speech intelligibility, respectively.
The evaluation system is described in Fig.1. The noisy whisper is first transformed into a joint time-frequency domain via the RDGT, where the noise spectrum is estimated. The sample rate parameter is used to control the spectrum density. The larger the over-sample rate, the more dense is the spectrum. The region control parameter is used to extract different parts of the enhanced spectrum, which reflects the over-estimation and under-estimation of speech spectrum after processing by the proposed speech enhancement algorithm. Both the spectrum density and speech over-estimation/under-estimation are evaluated for their effect on whispered speech intelligibility.
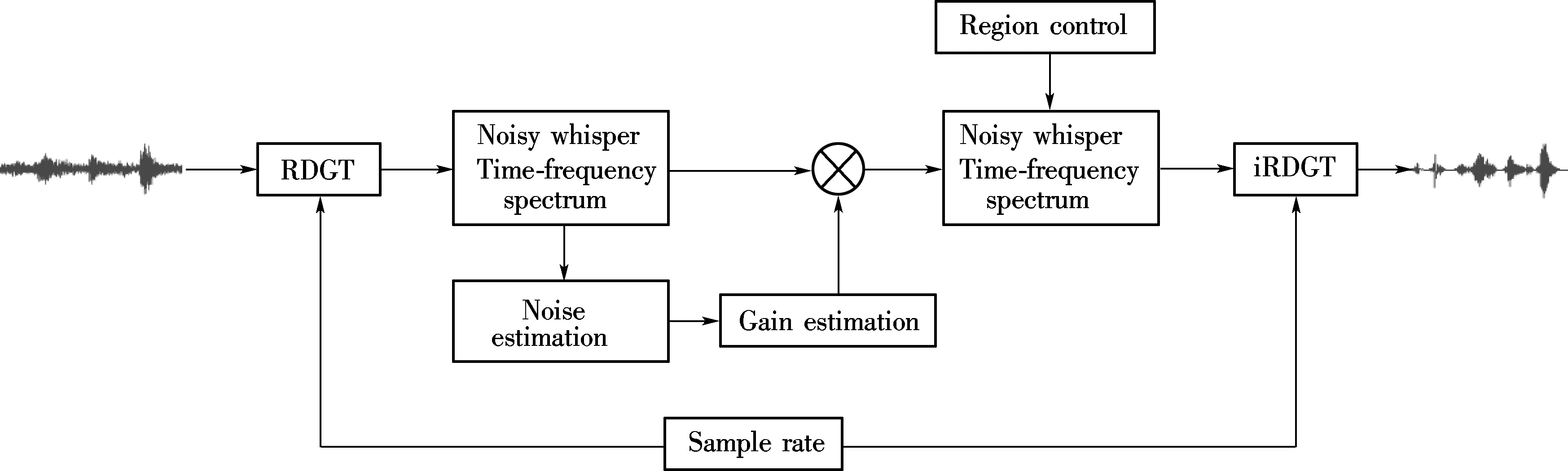
Fig.1 Diagram of the whisper intelligibility enhancement evaluation system
1 Deriving Logarithmic based Whisper Spectrum by RDGT
The RDGT[9]is defined as
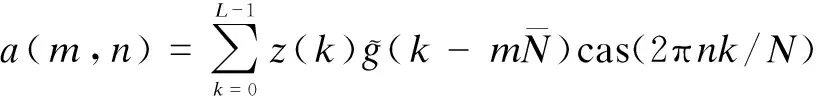
(1)
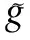
Letx(n) andd(n) be the sampled uncorrelated clean speech and the noise signal, respectively. The noisy whispery(n)=x(n)+d(n). The RDGT coefficients ofy(n),x(n) andd(n) are denoted asYr(k,l),Xr(k,l),Dr(k,l), respectively. The joint time-frequency spectrum ofy(n) is defined as
(2)
X(k,l) is always estimated fromY(k,l) by minimizing a non-negative error functiond()(k,l)) at frequency binkand time indexlwhen only one microphone source is provided. The Bayesian risk ofd() is given by
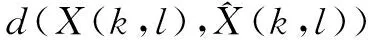
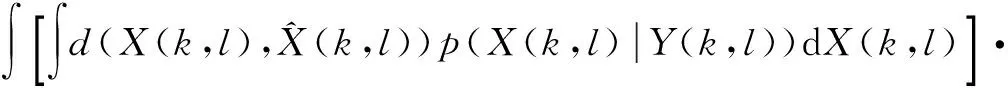
p(Y(k,l))dY(k,l)
(3)
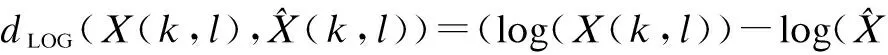
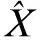
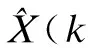
(4)
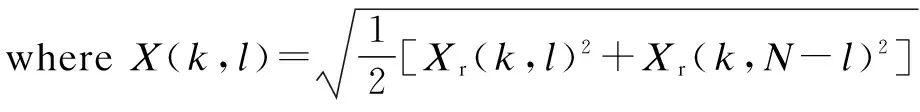
Assume that the spectrum of the clean whisper and noise are complex Gaussian variables respectively. Given two hypotheses, H0and H1, which indicate speech absence and presence at the time-frequency point (k,l) in the joint time-frequency plane, respectively, and assuming a complex Gaussian distribution of the spectrum for both speech and noise; the spectral gain for the logarithmic spectrum amplitude estimator is derived similarly to Ref.[10] as follows:
G(k,)=GH1(k,
(5)
whereGminis a threshold which is determined by a subjective criteria for the noise naturalness when speech is absent. Also,p(k,) is computed by the Bayesian rule,
p(k,)=
(6)
In Eq.(6),q(k,)=P(H0(k,,R. The gain functionGH1(k,) is derived as
GH1(k,
(7)
Once the estimated speech spectrum is obtained, the enhanced whisper is synthesized using the inverse RDGT as
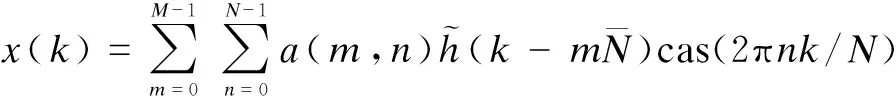
(8)
(9)
The advantage of using the RDGT to conduct a spectrum analysis is that it can compute spectrums of different densities with the sample rate defined asβ=MN/L.β=1 denotes critical sampling.β<1 denotes under sampling andβ>1 denotes over sampling. An example is illustrated in Fig.2, where spectrograms of three levels of densities for a whisper are plotted. As can be seen from Fig.2, the more dense the spectrum, the more speech components which are retained in the spectrum domain. In this paper, the spectra of different densities are derived usingβof different values.

(a)
(b)

(c)
2 Intelligibility Evaluation for Enhanced Whisper
2.1 Corpus and evaluation measurement
20 sentences were used to produce the whisper corpus. Three male and three female speakers uttered each sentence once in a soundproof environment. Four types of noise, i.e., Gaussian white noise, F16 cockpit noise, Babble noise and M109 tank noise, were used to synthesize the noisy whispers with prescribed SNRs. Noise-free speech signal and noise signal were both down-sampled to 16 kHz. Clean whispers were contaminated by noise signals at SNRs of -9,-6,-3, 0 and 3 dB, respectively.
A listening test can lead to an evaluation as observed by the intended group of users. However, such tests are costly and time consuming. Other objective intelligibility measures such as the articulation index (AI) and the speech transmission index (STI) are also less appropriate for methods where noisy speech is processed by the time-frequency gain function. Recently, Taal et al.[11]proposed a short-time objective intelligibility measure (STOI) which shows a high correlation with the intelligibility of noisy and time-frequency weighted noisy speech. The STOI is a function of a time-frequency dependent intermediate intelligibility measure, which compares the temporal envelopes of clean and degraded speech in short-time regions by means of a correlation coefficient. The average of the intermediate intelligibility measure over all bands and frames is calculated as
(10)
wherexj,mandyj,mare the frame based envelope spectrum of the clean speech and the enhanced speech, respectively.μ(·) refers to the sample average of the corresponding vector.Mrepresents the total number of frames andJthe number of one-third octave bands. In this paper, the STOI is used to evaluate the performance of enhanced whispers in the aspect of intelligibility.
2.2 Effect of spectrum density on speech intelligibility
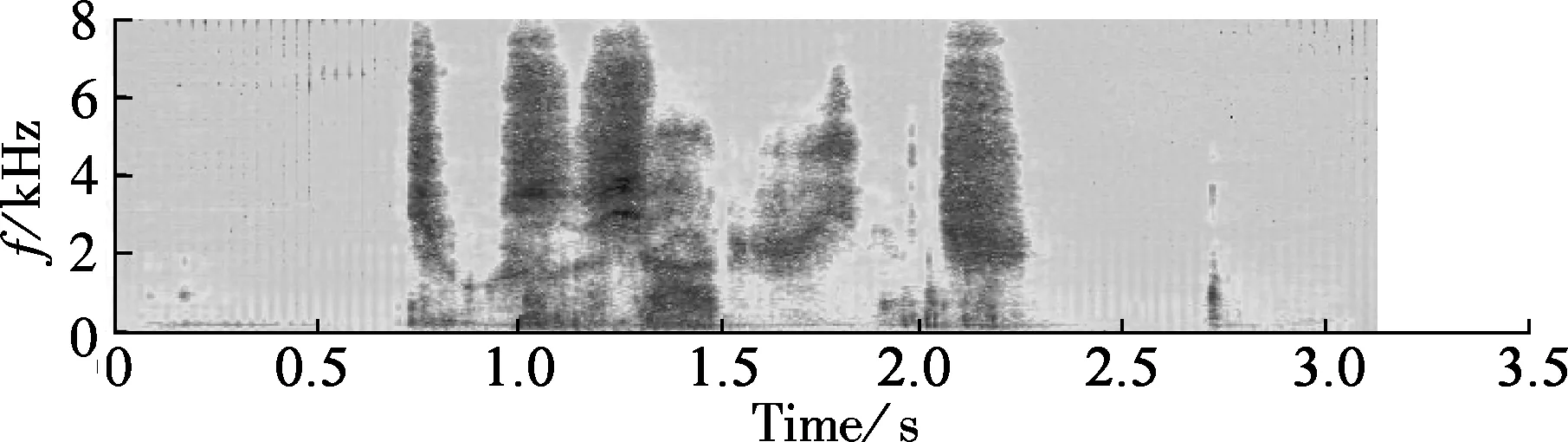
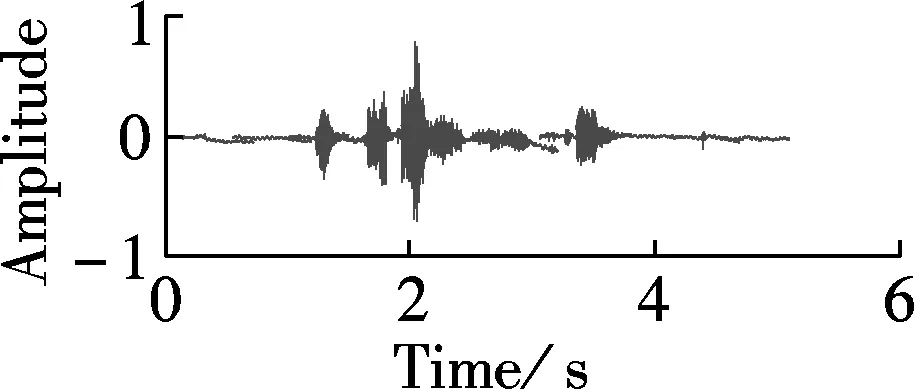
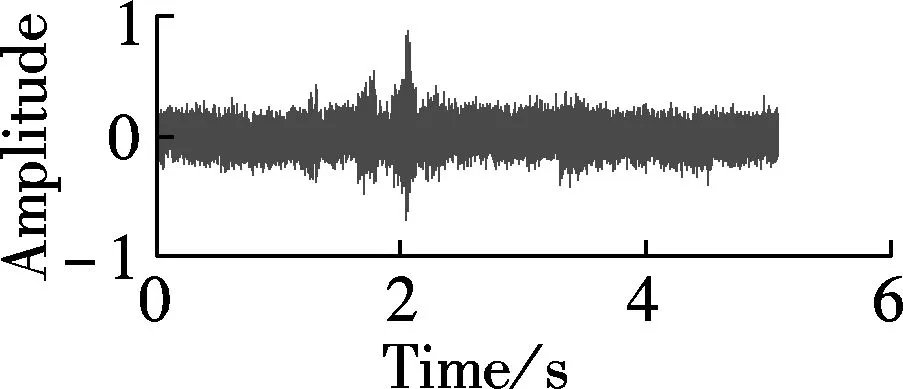
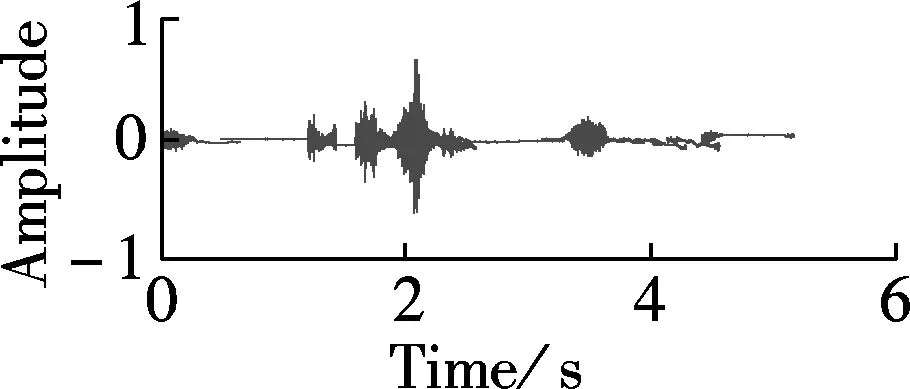
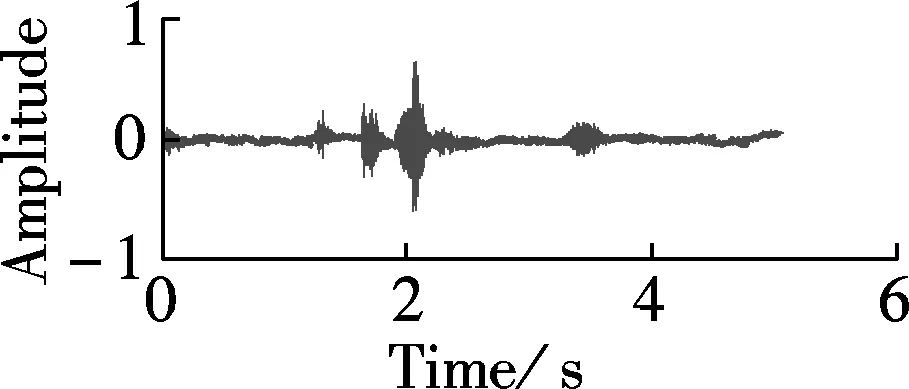
Fig.3 plots time domain waves of enhanced whispers with different algorithms in the context of Gaussian noise at SNR of -6 dB. Fig.3(a) plots a clean whisper. Fig.3(b) plots the noisy whisper contaminated by Gaussian noise at SNR of -6 dB. Figs.3(c) to (f) plot the enhanced whisper using the Gabor based spectrum, MMSE-STSA[12], OMLSA[10], and the Wiener algorithm[13], respectively. The sampling rate of the RDGT is set to be 4. In addition, the spectrograms of the enhanced whispers in Fig.3 are plotted in Fig.4. As can be seen from Fig.3 and Fig.4, the enhanced whisper using RDGT retains more speech components than that with MMSE-STSA and more noise is cancelled than that with OMLSA and Wiener.
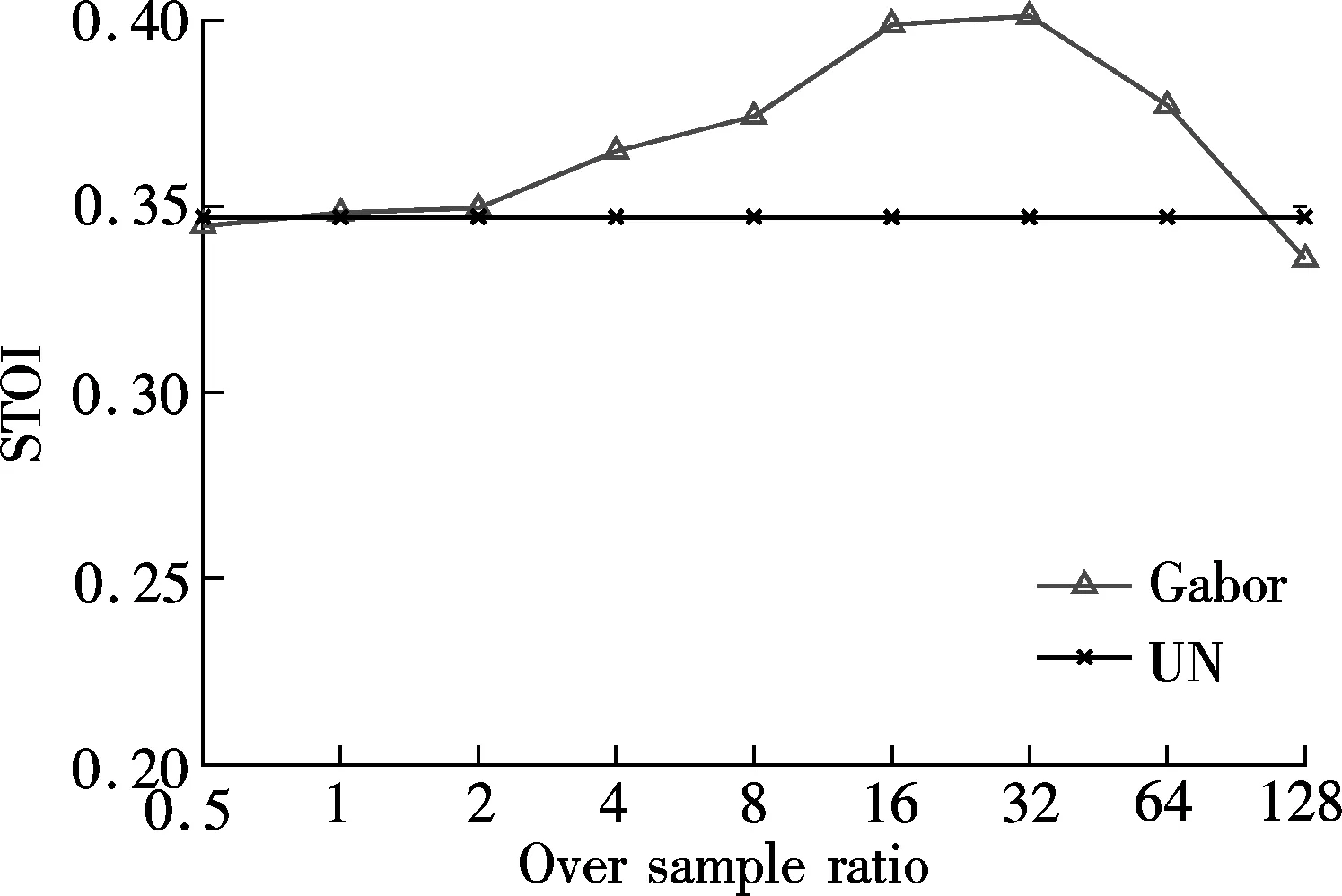
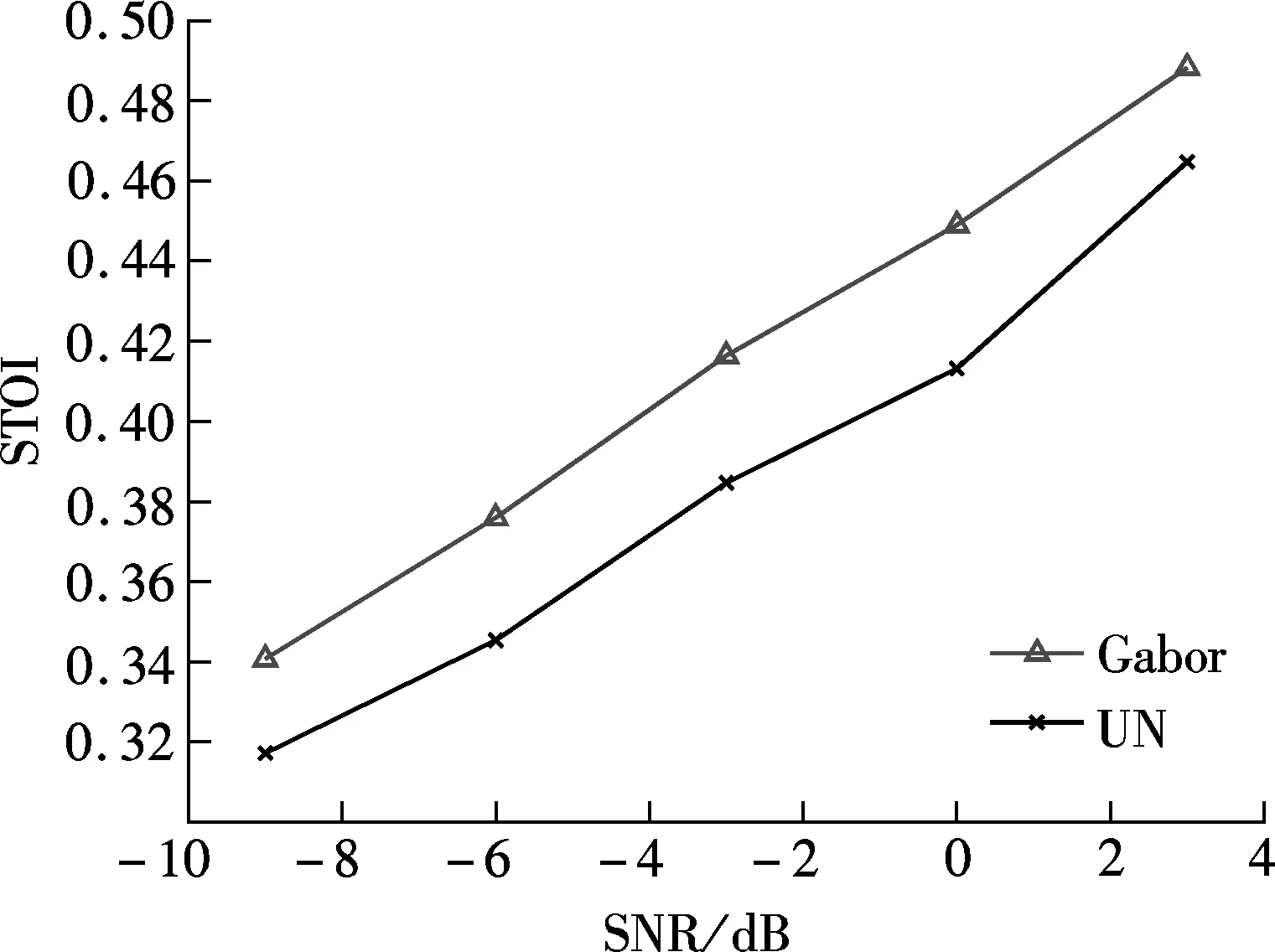
Fig.5(a) plots the mean STOI value of enhanced whispers as a function of sample rateβ. The mean STOI value of the unprocessed noisy whispers is also plotted for comparison. As can be seen from Fig.5(a), large gains in intelligibility are achieved with the spectrum derived by the RDGT withβ=32. This implies that the conventional speech enhancement algorithms maybe improve both the quality and intelligibility at the same time when using a more dense spectrum. Fig.5(b) plots mean STOI value of the enhanced whispers as the function of SNR. The noisy whispers are contaminated by Gaussian white noise. The estimated whispers are obtained using the RDGT withβ=32. The mean STOI value of the unprocessed whispers is also plotted for comparison. As can be seen from Fig.5(b), the conventional speech enhancement algorithms can improve speech intelligibility when the spectrum of some appropriate density is used.
(a)
(b)
(c)
(d)
(e)
(f)
Fig.3 Time domain waves of enhanced whispers using different algorithms in context of Gaussian noise at SNR of -6 dB. (a) Clean whisper; (b) Noisy whisper contaminated by Gaussian noise at SNR of -6 dB; (c) Enhanced whisper using Gabor based spectrum; (d) MMSE-STSA[12]; (e) OMLSA[10]; (f) Wiener algorithm[13]

(a)

(b)

(c)

(d)

(e)

(f)
Fig.4 Spectrograms of enhanced whispers using different algorithms in context of Gaussian noise at SNR of -6 dB. (a) Clean whisper; (b) Noisy whisper contaminated by Gaussian noise at SNR of -6 dB; (c) Enhanced whisper using Gabor based spectrum; (d) MMSE-STSA[12]; (e) OMLSA[10]; (f) Wiener algorithm[13]
(a)
(b)
2.3 Effect of over-estimation/underestimation on speech intelligibility
In order to evaluate the effect of spectrum components of different regions on speech intelligibility, we divide the enhanced spectrum into three disjoint regions:
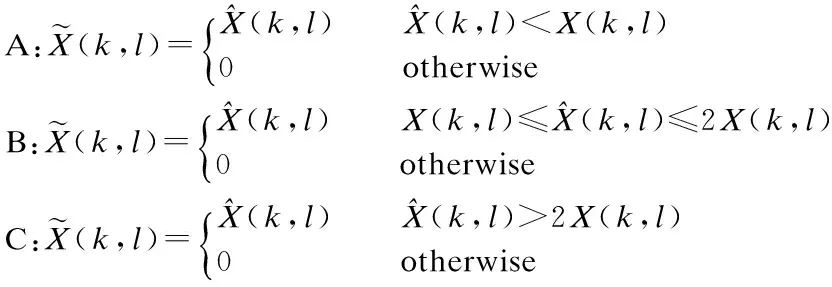
(11)
The regions of A, B, C and A+B are then used to synthesize the enhanced whisper, respectively, and the intelligibility of which is then evaluated using the STOI.
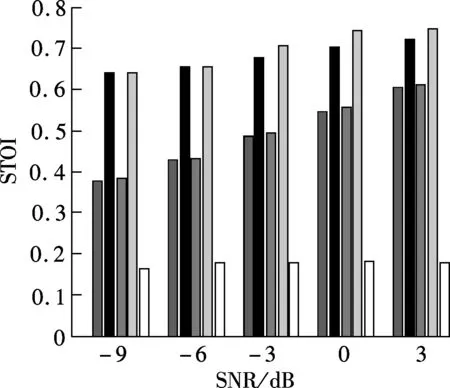
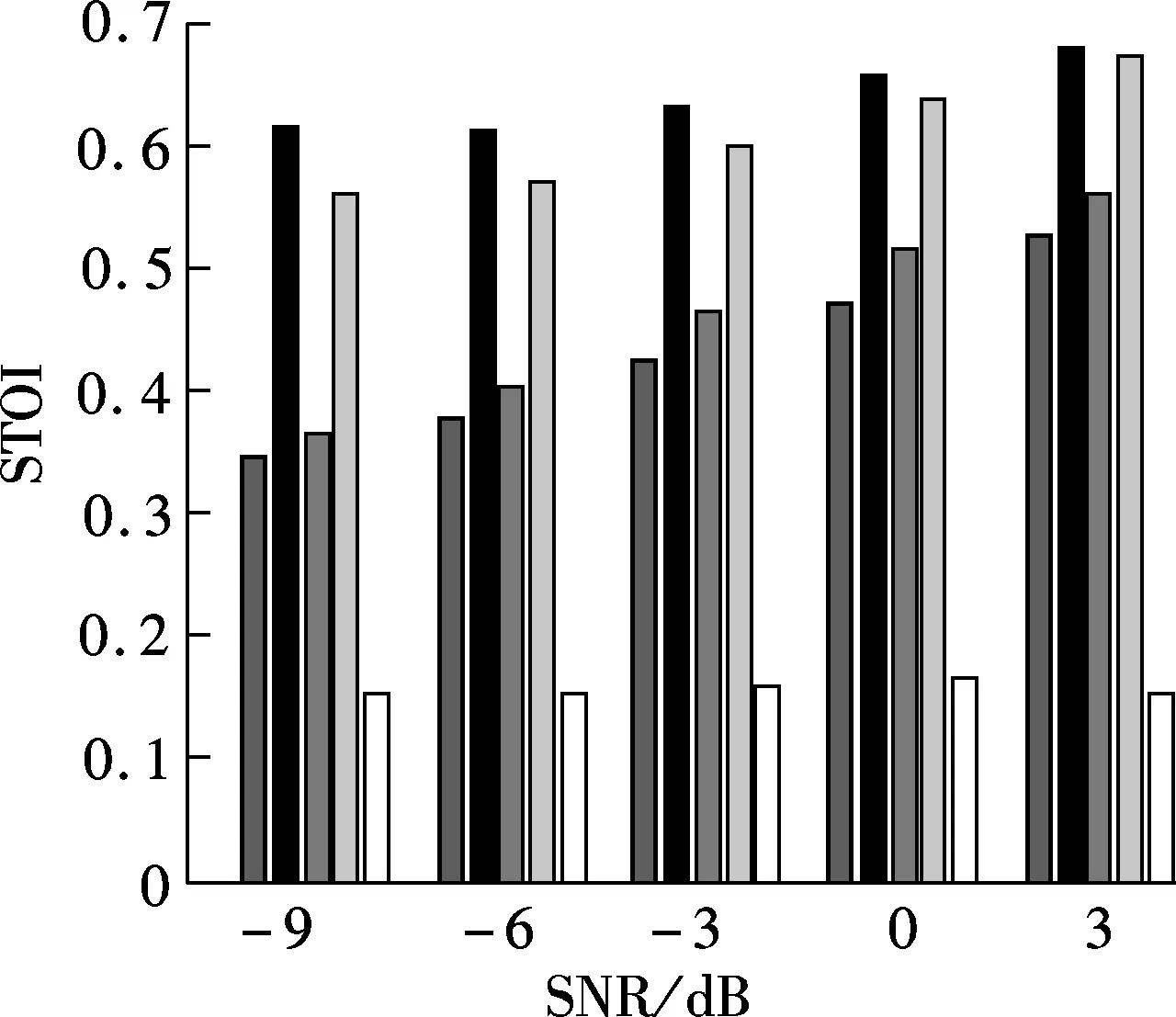
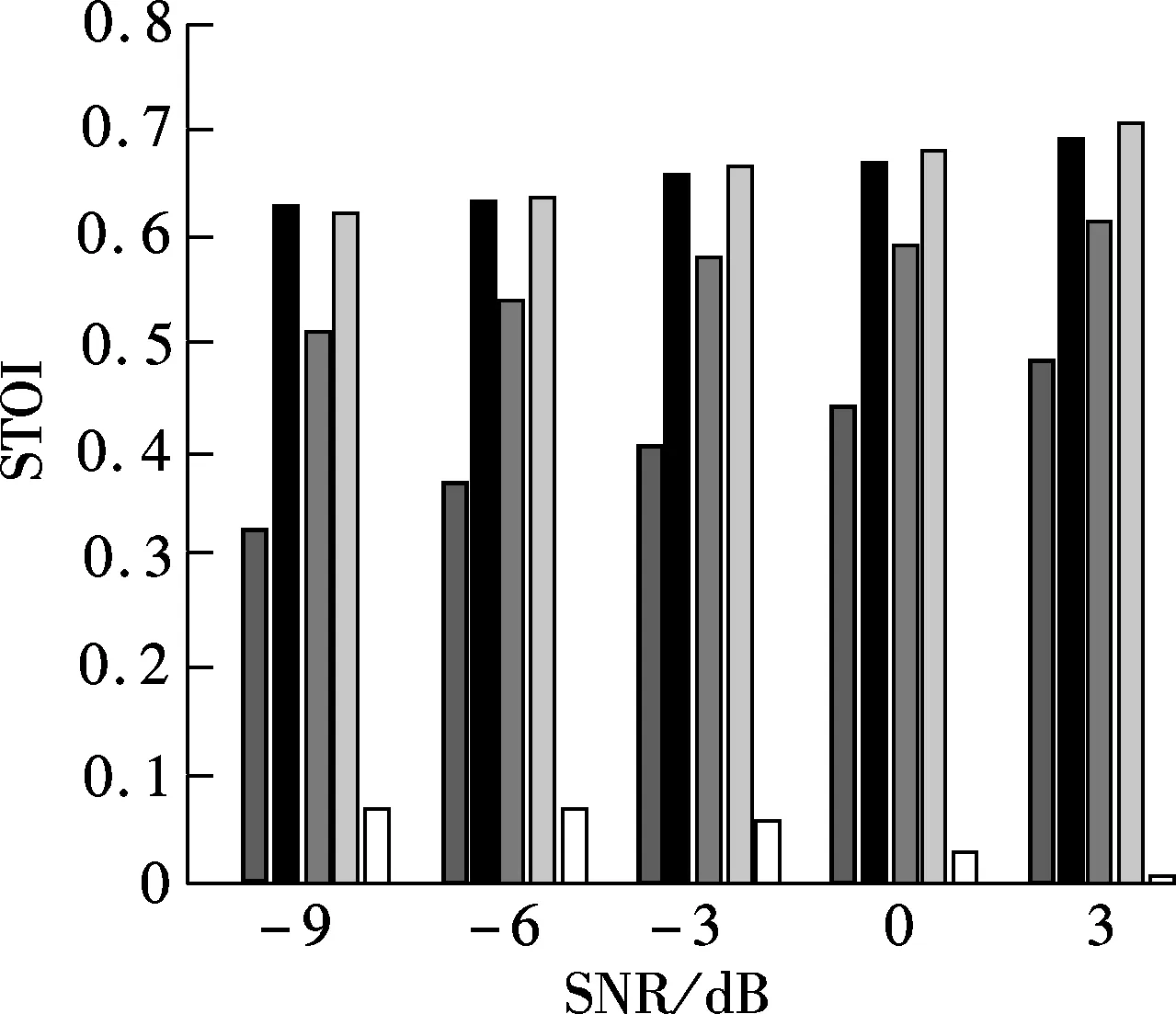
Fig.6 plots the mean STOI value of enhanced whispers using different regions of the enhanced spectrum which are derived using the proposed method in different noise environments. For comparison, the mean STOI of unprocessed whispers (denoted as UN) is also plotted in Fig.6. As can be seen from Fig.6, the enhanced whisper reconstructed by region A gains large intelligibility improvement under different test conditions. The region A+B has similar intelligibility performance to region A. Region C, however, has a detrimental effect on intelligibility improvement.
(a)
(b)
(c)
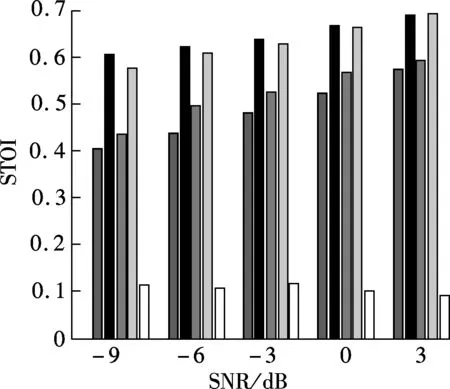
(d)

(e)
Fig.7 plots parametric gain curves under differentaposterioriSNRs. As can be seen from Fig.7, theaprioriSNR becomes lower with the decrease inGH1, no matter what theaposterioriSNRγis. It implies that speech distortion (i.e., under-estimation) occurs easily in low SNR and noise distortion (i.e., over-estimation) occurs easily in high SNR. As a consequence, in a low SNR environment, the time-frequency unit with high local SNR (>0 dB) will be underestimated. This is confirmed in Tab.1. As can be seen from Tab.1, 74.03% of the speech-dominated time-frequency units fall into region A after processing. Most noise dominated time-frequency units also fall into this area after processing. This may be another factor which improves speech intelligibility in the whisper context.
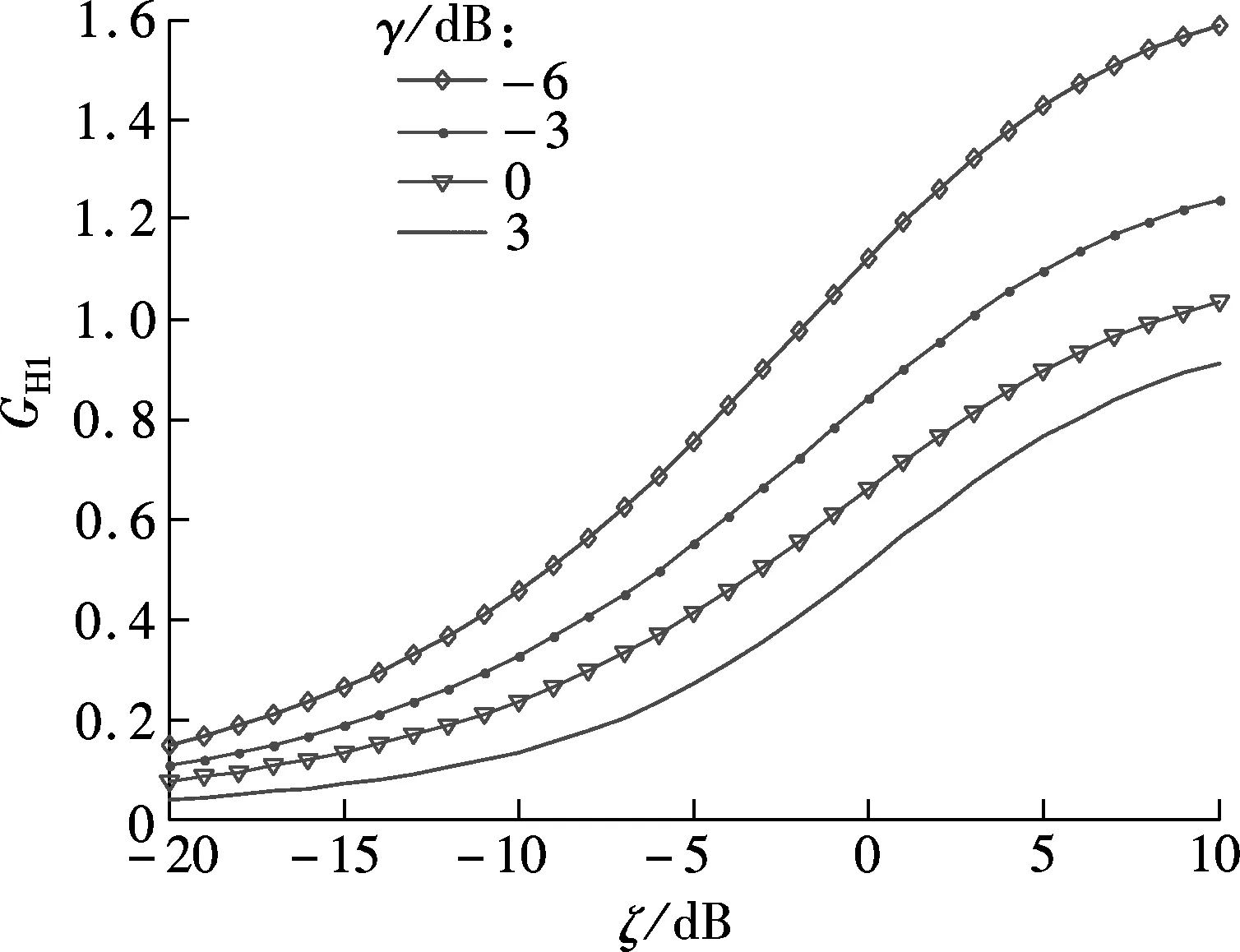
Fig.7 Parametric gain curves of Eq.(7) as a function of the a priori SNR

Tab.1 Spectrum components falling into three regions after processing %
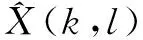
The intelligibility of the enhanced whisper reconstructed by the spectrum of region A+B does not have distinct improvement when comparing with that of region A. This is because region A represents an under-estimation and region B represents an over-estimation. When the spectrum of region A+B is used to reconstruct the enhanced whisper, speech distortion and residual noise coexist in the enhanced whisper, resulting in no distinct intelligibility improvement.
3 Conclusion
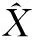
[1]Remijn G, Kikuchi M, Yoshimura Y, et al. Cortical hemodynamic response patterns to normal and whispered speech [J].TheJournaloftheAcousticalSocietyofAmerica, 2013, 133(5):3606-3606.
[2]Ruggles D, Riddell A, Freyman R L, et al. Intelligibility of voiced and whispered speech in noise in listeners with and without musical training [C]//ProceedingsofMeetingsonAcoustic. Montreal, Canada, 2013: 50-64.
[3]Sarria-Paja M, Falk T H. Whispered speech detection in noise using auditory-inspired modulation spectrum features [J].IEEESignalProcessingLetters, 2013, 20(8):783-786.
[4]Loizou P.Speechenhancement:theoryandpractice[M]. New York: CRC, 2007.
[5]Hu Y, Loizou P. A comparative intelligibility study of single-microphone noise reduction algorithms [J].TheJournaloftheAcousticalSocietyofAmerica, 2007, 122(3):1777-1786.
[6]Li J, Yang L, Zhang J, et al. Comparative intelligibility investigation of single-channel noise-reduction algorithms for Chinese, Japanese, and English [J].TheJournaloftheAcousticalSocietyofAmerica, 2011, 129(5):3291-3301.
[7]Loizou P, Kim G. Reasons why current speech-enhancement algorithms do not improve speech intelligibility and suggested solutions[J].IEEETransactionsonAudio,Speech,andLanguageProcessing, 2011, 19(1):47-56.
[8]Wang D, Kjems U, Pedersen M, et al. Speech intelligibility in background noise with ideal binary time-frequency masking[J].TheJournaloftheAcousticalSocietyofAmerica, 2009, 125(4): 2336-2347.
[9]Tao L, Kwan H. Multirate-based fast parallel algorithms for 2-D DHT-based real-valued discrete Gabor transform [J].IEEETransactionsonImageProcessing, 2012, 21(7):3306-3311.
[10]Cohen I, Berdugo B. Speech enhancement for non-stationary noise environments [J].SignalProcessing, 2001, 81(11):2403-2418.
[11] Taal C, Hendriks R, Heusdens R, et al. An algorithm for intelligibility prediction of time-frequency weighted noisy speech [J].IEEETransactionsonAudio,Speech,andLanguageProcessing, 2011, 19(7):2125-2136.
[12]Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator [J].IEEETransactionsonAcoustics,SpeechandSignalProcessing, 1984, 32(6):1109-1121.
[13]Scalart P. Speech enhancement based on a priori signal to noise estimation [C]//ProceedingsofAcoustics,Speech,andSignalProcessing. Atlanta, USA, 1996: 629-632.
聯(lián)合時(shí)頻域中增強(qiáng)后耳語音的可懂度評(píng)估
周 健1,2魏 昕3梁瑞宇4趙 力2
(1安徽大學(xué)智能計(jì)算與信號(hào)處理教育部重點(diǎn)實(shí)驗(yàn)室,合肥 230601)(2東南大學(xué)水聲信號(hào)處理教育部重點(diǎn)實(shí)驗(yàn)室,南京 210096)(3南京郵電大學(xué)通信與信息工程學(xué)院,南京 210003)(4河海大學(xué)計(jì)算機(jī)與信息學(xué)院,南京210098)
對(duì)在聯(lián)合時(shí)頻域影響增強(qiáng)后耳語音可懂度的因素進(jìn)行了評(píng)估.分析了耳語音時(shí)頻譜密度和增強(qiáng)后耳語音時(shí)頻譜中不同區(qū)域?qū)ΧZ音可懂度的影響.實(shí)驗(yàn)結(jié)果表明,在基于增益修正的時(shí)頻域語音增強(qiáng)算法中,采用密度較高的耳語音譜可提高增強(qiáng)后耳語音可懂度.此外,在增強(qiáng)后的耳語音的時(shí)頻譜中,頻譜幅度小于干凈耳語音時(shí)頻譜的頻譜區(qū)域?qū)υ鰪?qiáng)后的耳語音的可懂度提高最為重要,而那些頻譜幅度大于2倍干凈耳語音頻譜的頻譜區(qū)域?qū)υ鰪?qiáng)后的耳語音的可懂度具有消極作用.
耳語音增強(qiáng);可懂度評(píng)價(jià);實(shí)值離散Gabor變換;聯(lián)合時(shí)頻分析
TN912.35
s:The National Natural Science Foundation of China (No.61301295, 61273266, 61301219, 61201326, 61003131), the Natural Science Foundation of Anhui Province (No.1308085QF100, 1408085MF113), the Natural Science Foundation of Jiangsu Province (No.BK20130241), the Natural Science Foundation of Higher Education Institutions of Jiangsu Province (No.12KJB510021),the Doctoral Fund of Anhui University.
:Zhou Jian, Wei Xin, Liang Ruiyu, et al. Intelligibility evaluation of enhanced whisper in joint time-frequency domain[J].Journal of Southeast University (English Edition),2014,30(3):261-266.
10.3969/j.issn.1003-7985.2014.03.001
10.3969/j.issn.1003-7985.2014.03.001
Received 2014-03-11.
Biographies:Zhou Jian(1981—), male, doctor, lecturer; Zhao Li (corresponding author), male, doctor, professor, zhaoli@seu.edu.cn.
猜你喜歡
信號(hào)處理(2018年5期)2018-08-20 06:16:02
信號(hào)處理(2018年5期)2018-08-20 06:16:00
信號(hào)處理(2018年8期)2018-07-25 12:25:42
信號(hào)處理(2018年8期)2018-07-25 12:24:56
雷達(dá)學(xué)報(bào)(2018年3期)2018-07-18 02:41:34
新課程研究(2016年1期)2016-12-01 05:52:14
火控雷達(dá)技術(shù)(2016年1期)2016-02-06 02:17:55
無線電通信技術(shù)(2015年3期)2015-12-23 11:37:02
陜西教育·綜合版(2015年12期)2015-04-10 09:59:41
電測(cè)與儀表(2015年3期)2015-04-09 11:37:24
 Journal of Southeast University(English Edition)2014年3期
Journal of Southeast University(English Edition)2014年3期
- Journal of Southeast University(English Edition)的其它文章
- Observation and characterization of asphalt microstructure by atomic force microscopy
- Research on asphalt concrete pavement deicing technology
- Influence of different curing regimes on the microstructure and macro performance of UHPFRCC
- Evil-hunter: a novel web shell detection system based on scoring scheme
- Islamic traditional architecture environment overlapping the modern architecture design
- Hom-dimodules and FRT theorem of Hom type