
Fault Attribute Reduction of Oil Immersed Transformer Based on Improved Imperialist Competitive Algorithm
2021-01-09 02:54:28LiBianHuiHeHongnaSunandWenjingLiu
Li Bian, Hui He, Hongna Sun and Wenjing Liu
(1. College of Electronic and Information Engineering, Guangdong Ocean University, Zhanjiang 524088,Guangdong, China;2. College of Electrical and Control Engineering, Heilongjiang University of Science andTechnology, Harbin 150022, China;3. Handan Power Supply Company, Handan 056002, Hebei,China)
Abstract: The original fault data of oil immersed transformer often contains a large number of unnecessary attributes, which greatly increases the elapsed time of the algorithm and reduces the classification accuracy, leading to the rise of the diagnosis error rate. Therefore, in order to obtain high quality oil immersed transformer fault attribute data sets, an improved imperialist competitive algorithm was proposed to optimize the rough set to discretize the original fault data set and the attribute reduction. The feasibility of the proposed algorithm was verified by experiments and compared with other intelligent algorithms. Results show that the algorithm was stable at the 27th iteration with a reduction rate of 56.25% and a reduction accuracy of 98%. By using BP neural network to classify the reduction results, the accuracy was 86.25%, and the overall effect was better than those of the original data and other algorithms. Hence, the proposed method is effective for fault attribute reduction of oil immersed transformer.
Keywords: transformer fault; improved imperialist competitive algorithm; rough set; attribute reduction; BP neural network
1 Introduction
Nowadays, the demand for electric power is gradually rising, which makes the voltage and capacity of the power system increased. The normal operation of a transformer can effectively ensure the safe, reliable, and stable operation of the whole power system. There are many types of fault diagnosis methods for oil immersed transformer, among which dissolved gas analysis method is more accurate and reliable for early latent faults and can effectively prevent major accidents caused by transformer faults.
Sixteen kinds of conditional attributes are commonly used in the dissolved gas method in oil. However, not all of them are meaningful, and unnecessary attributes will bring inconvenience to fault diagnosis. Therefore, in order to improve fault diagnosis performance, redundant attributes should be reduced. Since the traditional methods such as expert experience method and mathematical analysis method are subjective and require high experience, they are not suitable for transformer fault diagnosis.
Rough set theory[1-4]is a new data mining technology, which can explore the implicit relationship between data on the basis of guaranteeing the invariable classification effect. By extracting features, eliminating redundant information, and replacing original attributes with more concise attributes, it can effectively improve the data analysis ability and simplify the processing process. At present, the theory has been applied to fault diagnosis[5-7], data mining[8-10], and so on. Attribute reduction is the key content of rough set. The reduced data is a subset of the original data, whose classification ability is the same as that before reduction. Attribute reduction includes compound system reduction, mutual information reduction, Johnson algorithm, and heuristic algorithm, while they have high complexity and cannot be optimized globally. Therefore, the trend of current development is to use artificial intelligence algorithm to solve attribute reduction problems. In Ref. [11], genetic algorithm was used to reduce attributes. According to the data collection extraction criterion of genetic algorithm, the high-importance attributes set is regarded as the optimal reduction result. However, the genetic algorithm itself has the disadvantages of large amounts of computation, low efficiency, and susceptibility to local optimum, so the final effect is not satisfactory. Ant colony algorithm[12]was used to reduce attributes, but it also has shortcomings such as slow convergence speed, susceptibility to local optimum, large amounts of computation, and long solving time.
In information systems, the fewer the attributes need to be considered, the simpler the processing of information is. Hence, an improved imperialist competitive algorithm (IICA)[13-15]was used to solve the fault attribute reduction problem of oil immersed transformer, and was compared with genetic algorithm attribute reduction (GAAR), simulated annealing attribute reduction (SAAR), and particle swarm optimization attribute reduction (PSOAR).
2 Dissolved Gas Analysis
While using oil immersed transformer, many kinds of gases are produced, which are generally divided into normal gases and abnormal gases. Only the gas generated by the aging of the transformer is classified as normal gas. When the transformer fails and abnormal conditions occur, the gas generated by the internal material of the transformer under the combined action of electricity and heat is called fault gas[16].
The main sources of dissolved gases in transformer oil can be divided into three categories: decomposition of solid insulating materials, decomposition of insulating oil, and other sources. In addition, some operations can lead to the occurrence of some gases in the oil. For example, in the use of on-load tap-changer transformer, switching switches may cause oil leakage into the main tank of the transformer. When there is oil in the tank during welding, excessive local temperature and pollutants will also result in the production of other gases in the oil. Sometimes the original injected insulating oil contains certain gases.
For dissolved gases in transformer oil, the analyses of types, contents, and compositions, as well as the processing of related data usually conform to the thermodynamic law that the energy of fault is closely related to the chemical unsaturation of gases. Generally, the dissolved gases in oil are mainly N2and O2, and the combustible gases only account for about one thousandth of the total dissolved gases. The aging of the transformer insulation materials will cause the generation of CO2and CO, so if the transformer runs for a long time, the gas contents CO2and CO will be very high. When transformer internal faults occur, gases such as CH4and C2H6are usually generated[17]. Different relative proportions of these gases will reflect different types of faults. Therefore, through the laboratory simulation test and the field observation experience of transformer faults, combined with the measured dissolved gas content, a certain amount of data processing and analysis can be carried out to distinguish different types of faults. However, the initial fault data are often large and complex, so the dimensionality reduction of the original data is the first step.
3 Rough Set
3.1 Discretization Theory
Attribute discretization is an important step in data preprocessing. A large number of rules need to be discretized to improve the performance of the algorithm. Therefore, before attribute reduction, it is necessary to discretize the fault data. Rough set discretization is to divide attributes into regions according to breakpoints in the data, and then classify the regions into more intervals, under the condition that the correlation between decision attributes and conditional attributes does not change before and after reduction[18].
The main methods of discretization include equal frequency discretization method, equal distance discretization method, and discretization method according to attribute importance[19].
3.2 Attribute Reduction
Attribute reduction is another crucial aspect of rough set theory[20-21]. For a given system, letP(P≠φ) be a reduction ofC, thenPshould satisfy two conditions: ① The discriminant relation before and after reduction remains unchanged; ② The redundant information is not included inPas far as possible, and the reduction set obtained byCis defined as RED(C).
RED(C)={P?C|γP(D)=γC(D),?B?P,γB(D)≠γC(D)}
(1)
If any subsetC′ ofCis regarded as an approximate reduction ofC, then the approximate accuracy of the reduction is defined as
(2)
Construct reduction model of attribute dependence degree into
(3)
where Card(C) is the number of conditional attributes,Card(C′) is the number of conditional attributes in reduction,γC′(D) is the degree of dependence of attributes, andαandβare the weight factors.
WhenγC′(D)=1, the decision attribute is completely determined by the conditional attribute. Therefore, this function guarantees that minimal reduction can be achieved without changing the dependency of the attributes.
After this step, the data will reduce some conditional attributes. At this time, the neural network needs to be used in the next step to verify whether the reduced data set has better effects.
3.3 BP Neural Network
BP neural network is a multi-layer feedforward neural network, which consists of input layer, hidden layer, and output layer[22-23], as shown in Fig.1.
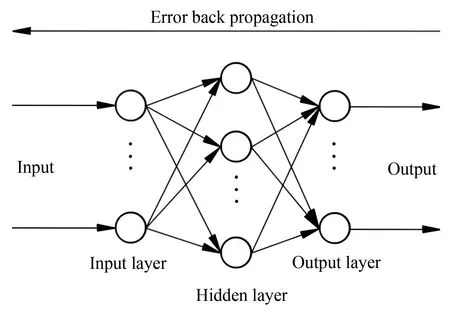
Fig.1 Structural chart of BP neural network
When the input layer signal is given, the output value can be obtained by combining the weights and thresholds of the neural network, and then compared with the actual value to calculate the error. Next, the neural network will reduce the error by adjusting the weights and thresholds in the process of reverse propagation. By repeating the forward and backward propagation processes continuously, the error will be smaller and smaller until the required range is reached. With the advantages of simple structure and strong learning ability, the BP neural network has been widely used in the field of fault diagnosis recently.
Combining data with neural network, the effect of the attribute reduction can be verified by comparing the results.
4 Improved Imperialist Competitive Algorithm (IICA)
4.1 Imperialist Competitive Algorithm (ICA)
ICA is an optimization algorithm inspired by imperialist competition, whose initial population is divided into two types: imperialists and colonies, which together shape several empires. ICA mainly consists of the competition between empires, i.e., the disintegration of small and weak empires, and the occupation of colonies by powerful empires. In this algorithm, fitness value is called cost, and the state power is judged by calculating the cost. The smaller the cost is, the greater the power is. When there is only one empire at last, the colonies will have the same status and the same cost as the imperialists.
After the imperialists have allocated all the colonies and established the initial empire, the colonies begin to move towards their countries. The movement is called assimilation policy. If the cost of a colony is found to be lower than that of an imperialist in the course of its movement, the colony will become an imperialist, and the former position of the imperialist will become a new colony. Fig.2 shows the movement of the colonies towards the imperialists, in whichαandxare evenly distributed random numbers, anddis the distance between colonies and imperialists.
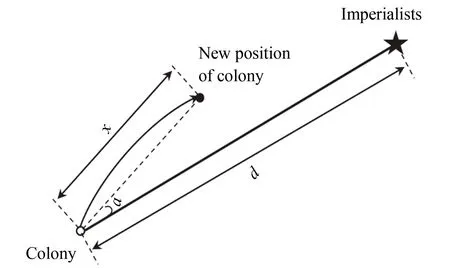
Fig.2 Movement process of the colony
The power of the empire is consisted of two parts, i.e., imperialists and colonies. In ICA, the total power of the empire is defined by the power of the imperialist state plus the average power of the colonies. When an empire is unable to compete among the empires or increase its power, it will be destroyed. The imperialist competition will lead to the strengthening of the powerful empire and the weakening of the weak empire until the weak empire collapses. These movements will bring all countries together. Then there will be only one empire in the world, and all the other countries will be its colonies. The position of the empire is the best solution[24].
4.2 Improved Imperialist Competitive Algorithm (IICA)
1) In the initial stage of the empire, the following forms were proposed to avoid the weakest imperial power being 0, which could lead to the number of colonies become 0.
(4)
(5)
whereci,pi, and NCirepresent the cost, power, and number of colonies of theith empire, respectively.
2) In the basic ICA assimilation mechanism, the movement of colonies needs to determine the direction and distance of the movement. IICA adopts Eq. (6) to realize the assimilation process.
pc=pc+β×δ.*(pi-pc)
(6)
wherepcandpidenote the position of colonies and imperialists, respectively.δis anN-dimensional vector, whose elements are random numbers between[0,1]. .*denotes the multiplication of twoN-dimensional vectors with the elements of the same location. Once the cost of the colony is lower than that of an imperialist in the course of its movement, the colony will become an imperialist country, and the old imperialist country will become a colony.
3) Colonial reform operations were added to IICA. For each iteration, a certain number of colonies were selected. According to the probability of reform, the same number of colonies was randomly generated to replace the original colonies, and the cost of new colonies was calculated.
(7)
where impnandT.C.nare the imperialist countries and the total cost of thenth empire, respectively.ζis the influence factor, 0<ζ<1. The operation increased the diversity of the samples.
4)When the distance between the two empires was less than the set search range, merging the two empires could improve the convergence speed of the algorithm to a certain extent.
5)In the original ICA algorithm, imperial competition is performed in each iteration, while IICA determines whether imperial competition is conducted by setting a probability parameter,ρ(0<ρ<1).
The weakest colony in the weakest empire will be chosen as the object of the competition among the empires. The stronger the empire is, the more likely it is to occupy the colony. The probability of each empire occupying the colony is expressed as follows:
(8)
(9)
whereN.T.C.nis the total cost of standardization for then-th empire, andpnindicates the probability that then-th empire will occupy the colony.
6) When an empire has only imperialist countries but no colonies, it means that the empire is overthrown and can be deleted. With the competition between empires, the gap between the empires will become wider and wider. When there is only one empire left, stop iterating. The position of the empire is the best solution.
Through the competition between empires and the movement of colonies, the algorithm avoids the problem of easily falling into local optimum. Meanwhile, the excellent optimization efficiency makes the algorithm receive rational results in fewer iterations, which is feasible and effective to solve the problem of transformer fault attribute reduction.
Fig.3 shows the whole verification process of the effectiveness of the algorithm.
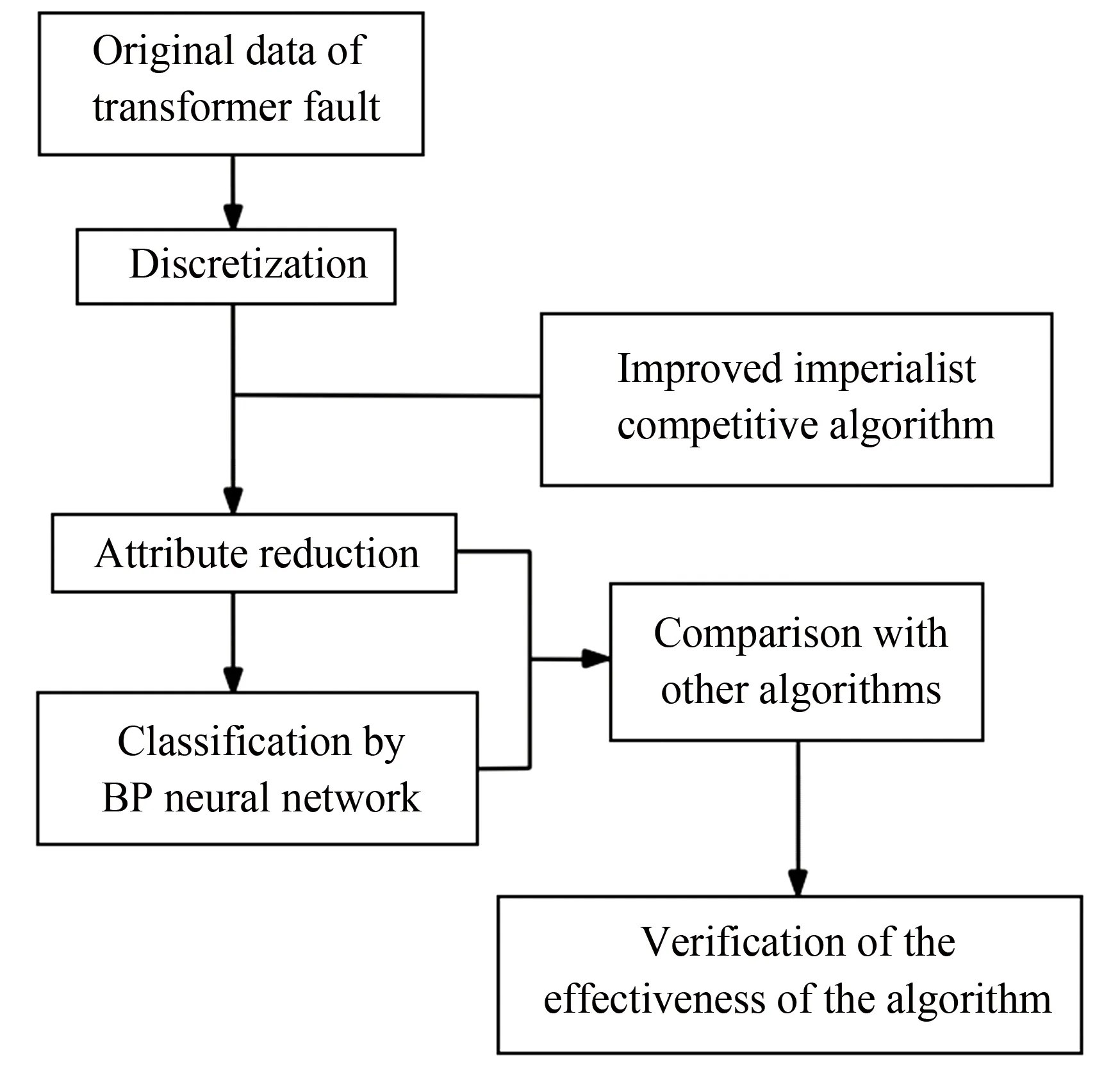
Fig.3 Verification process of the effectiveness of the algorithm
5 Fault Attribute Reduction of Oil Immersed Transformer
The contents and important ratios of the dissolved gases produced by oil immersed transformer operation were taken as the original data. There are 16 conditional attributes in the data set, including C3H6, CO2, H2, C2H2, CH4, C3H8, C3H4, C2H4, CO, C2H6, C2H4/C2H6, C2H2/C2H4, C2H6/C2H2, C2H6/CH4, C2H2/CH4, and CH4/H2[25]. Some of the data are listed in Table 1. After discretization, the set of breakpoints is shown in Table 2.
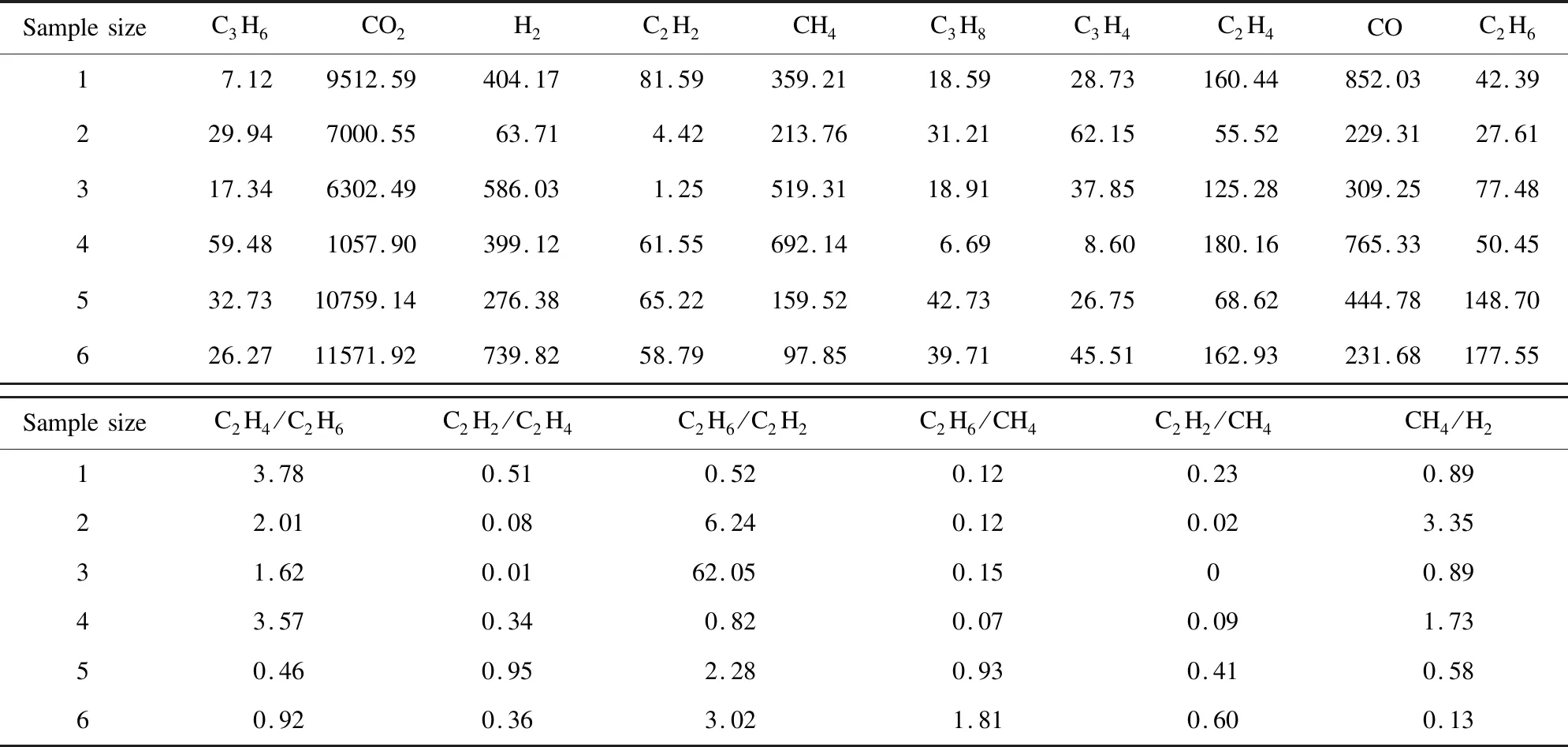
Table 1 Partial fault attribute data set of oil immersed transformer

Table 2 Set of breakpoints
The improved imperialist competitive algorithm attribute reduction (IICAAR) model was used to reduce the discretized transformer fault data. The parameters were set as follows: Initial number of countriesM=200, number of imperialist countriesMI=8, cost coefficientω=0.02, weight factorsα=0.5,β=2, influence factorζ=0.3, and imperial merger search spaceσ=0.02.
Figs.4-7 demonstrate the operation diagrams of GAAR, SAAR, PSOAR, and IICAAR, respectively. It can be seen that when IICAAR iterated to nine times, the power of the optimal imperialist state was stabilized, and the position of the imperialist state was the optimal solution. The iteration stabilization speed of IICAAR was better than those of the other three algorithms. The fitness value was lower, and the results were stable after many tests.
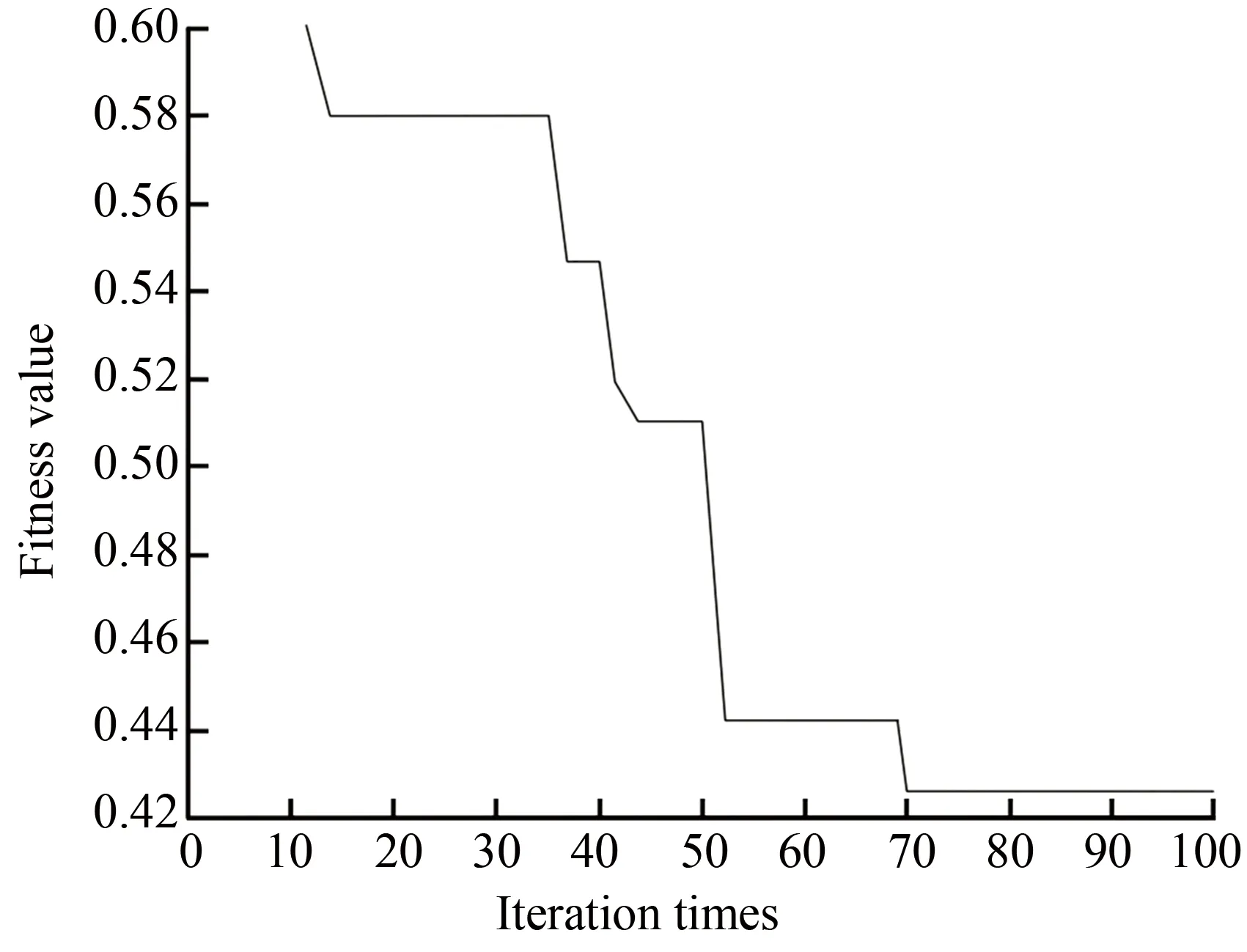
Fig.4 Operation diagram of GAAR
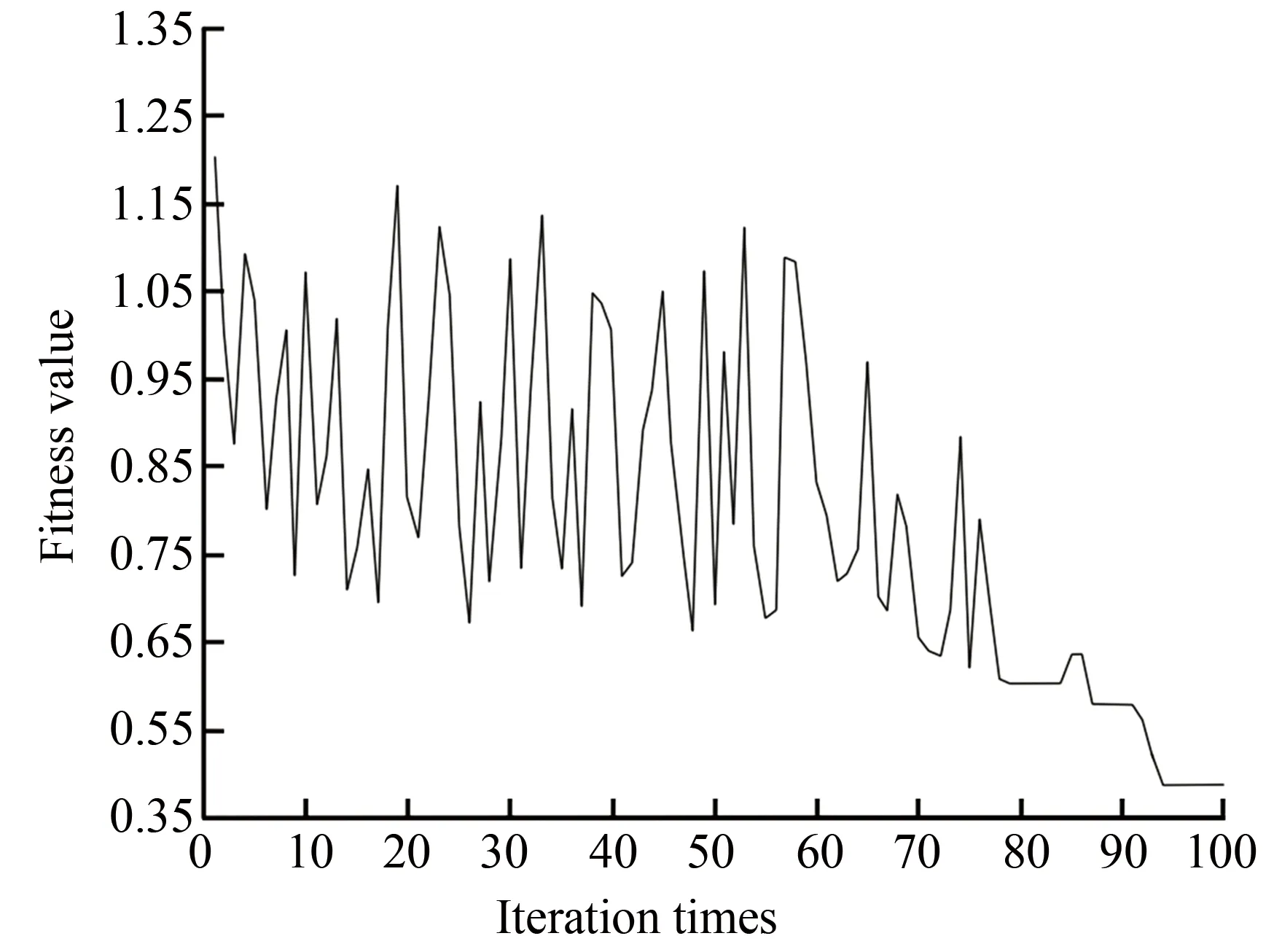
Fig.5 Operation diagram of SAAR
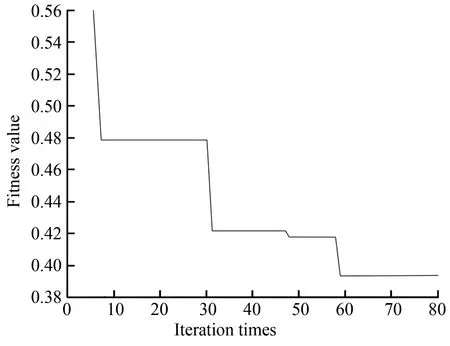
Fig.6 Operation diagram of PSOAR
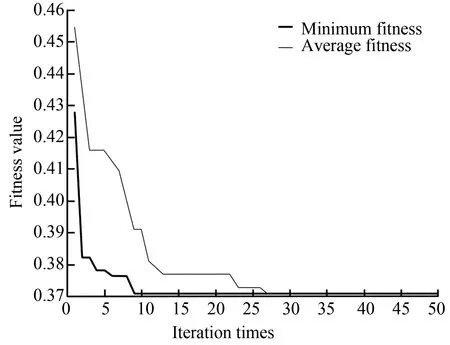
Fig.7 Operation diagram of IICAAR
Tables 3-5 show the data set after reduction, including the comparison table of reduction effect and the comparison of classification results under BP neural network. The four algorithms made a lot of reduction on conditional attributes. IICAAR reduced the original data to seven conditional attributes, and the reduction rate was as high as 56.25%. In addition, its reduction accuracy and minimum fitness value were better than those of the other three algorithms. In terms of classification accuracy, IICAAR and PSOAR had the same accuracy, and the overall effect was better than other algorithms. However, since PSOAR had more conditional attributes than IICAAR, the performance of its reduction was worse than that of IICAAR.

Table 3 Reduction attribute sets of different algorithms

Table 4 Performance comparison of different intelligent algorithms

Table 5 Comparison of classification accuracy under BP neural network
From the above analysis and discussion, it can be found that IICA had good feasibility and adaptability in the attribute reduction of rough set. Compared with other intelligent algorithms, IICAAR had the advantages of fast convergence speed, high reduction rate, low fitness value, and high classification accuracy.
6 Conclusions
1) In this paper, IICA is applied to the attribute reduction of oil immersed transformer fault. Through introducing, modeling, simulating, and comparing, it was concluded that IICA had excellent feasibility and applicability.
2) IICAAR achieved the optimal reduction of transformer fault attributes. In comparison with GAAR, SAAR, and PSOAR, IICAAR had lower iteration times, higher reduction rate, and better precision, which could reduce the requirement of data storage and improve classification accuracy.
3) On the premise of keeping the discrimination relation unchanged, removing some meaningless attributes could greatly reduce the difficulty of subsequent operations. When the data of the sample set is large, IICA should be adopted.
 Journal of Harbin Institute of Technology(New Series)2020年6期
Journal of Harbin Institute of Technology(New Series)2020年6期
- Journal of Harbin Institute of Technology(New Series)的其它文章
- Analogy Theory and Application of Pressure Difference of Wind Turbine Blade Profile
- A Proposal for an Integrated Model to Evaluate the Circadian Effects of Mesopic Light Sources
- Dynamic Reconfigurable Structure with Rate Distortion Optimization
- Iterative Learning Controller Design for CNC Machine Tools
- Study of Array Antenna Pattern Synthesis Based on Sparse Sensing
- Static Performance and Fracture Numerical Analysis of 301L/Q235B Dissimilar Steel Resistance Spot Welded Joints