
Unifying Convolution and Transformer Decoder for Textile Fiber Identification
2023-09-22 14:30XULuoli許羅力LIFenying李粉英CHANGShan
XU Luoli(許羅力), LI Fenying(李粉英), CHANG Shan(常 姍)*
1 College of Computer Science and Technology, Donghua University, Shanghai 201620, China 2 Silicon Engineer Group, ZEKU Technology (Shanghai), Shanghai 201203, China
Abstract:At present, convolutional neural networks (CNNs) and transformers surpass humans in many situations (such as face recognition and object classification), but do not work well in identifying fibers in textile surface images. Hence, this paper proposes an architecture named FiberCT which takes advantages of the feature extraction capability of CNNs and the long-range modeling capability of transformer decoders to adaptively extract multiple types of fiber features. Firstly, the convolution module extracts fiber features from the input textile surface images. Secondly, these features are sent into the transformer decoder module where label embeddings are compared with the features of each type of fibers through multi-head cross-attention and the desired features are pooled adaptively. Finally, an asymmetric loss further purifies the extracted fiber representations. Experiments show that FiberCT can more effectively extract the representations of various types of fibers and improve fiber identification accuracy than state-of-the-art multi-label classification approaches.
Key words:non-destructive textile fiber identification; transformer decoder; asymmetric loss
0 Introduction
Apparel is one of the necessities in people’s daily life. The type and the content of fibers have a significant impact on clothing comfort, warmth, and perspiration conduction, and other factors[1-3]. Therefore, worldwide countries stipulate that textiles on the market must be clearly marked with fiber types and contents. However, some producers deliberately label cheap fibers as superior fibers to make profits, significantly harming the interests of consumers. Hence, the identification of fibers is one of the major concerns of market regulators and consumers. The commonly employed fiber identification approaches[4-10], such as burning fibers, fiber solubility, and microscopic observation, rely mostly on manual operation which is inefficient, time-consuming, costly, and susceptible to operator conditions. The above methods are not suitable for large-scale rapid test by regulators and for the convenient use by ordinary consumers. Therefore, it is an inevitable trend to develop automatic identification technology for textile fibers[8-13]. Infrared automatic identification technology, which was introduced into the field of fiber identification without breaking textiles[8-10], was once very popular with fiber testing agencies, research institutes and customs. However, this method requires prior knowledge of the fiber type of the tested clothes and can only detect a few types of fibers. In addition, the equipment is expensive. Automatic fiber identification using images of textile surfaces has become a new topic thanks to advancements in camera technology and the ability of neural networks to extract features[12-13]. Fengetal.[12]proposed a DenseNet-based multi-branch recognition framework to transform fiber identification into a multi-label classification task. Ohietal.[13]presented an ensemble architecture based on the lightweight network Xception, and it required fewer training parameters and achieved higher accuracy for single-component fiber identification than previous models[12].
In fact, a large number of textiles are made of two or more types of fibers. The previous works are all based on convolutional neural networks (CNNs) which have excellent performance in single-label image classification. However, the inherent shortcomings of CNNs in multi-label classification, for example, poor recognition of small objects[14], make these studies unsatisfactory when it comes to identifying fine and blended fibers in clothing. Recently, a lot of work has been done to improve the image multi-label recognition ability of CNNs, such as jointly mining label dependency or semantic dependency with recurrent neural networks (RNNs)[14-16]and catching label relevance of multi-label image recognition with graph convolutional networks (GCNs)[17-20]. Textile fibers are very fine (e.g., about 20 μm in diameter for wool fibers, 10 μm for cotton fibers and several micrometers for chemical fibers), which makes it difficult to achieve desired results with the aforementioned methods.
Different from CNNs that utilize convolutional kernels to extract object features, the transformer network[21-23]employs attention mechanisms to obtain global contextual information and extract target features, and has achieved great success in natural language processing tasks. Dosovitskiyetal.[24]introduced the transformer to computer vision tasks. They split an image into a number of patches and fed each patch as a word in natural language processing into a stacked transformer encoder architecture for image classification. Since then, numerous improved transformer encoder architectures have been applied to image recognition tasks[25-27]. Nevertheless, when an input image is split into multiple patches, the above transformer-based frameworks do not take into account the peculiarities of fiber shapes in fabrics, such as fiber curls, overlaps, and tangles, which aggravates the imbalance of fiber types during modeling and leads to low accuracy in fiber identification.
To handle the above problems, this work proposes a model that unifies CNNs and transformer decoders for textile fiber identification, called FiberCT. FiberCT utilizes CNNs to gradually extract fiber features with more advanced semantic information and then sends them to the transformer decoders. The multi-head self-attention mechanism is used to extract label features, and the multi-head cross-attention mechanism is utilized to locate the fiber features of each label to adaptively extract the desired features from the data to identify each type of fibers in the image. The contributions are as follows.
1) A framework for identifying fibers in textile surface images called FiberCT is presented. FiberCT takes advantages of CNN feature extraction and transformer multi-head attention mechanisms to effectively solve the problems of sample imbalance and small sample sizes. It is the first application of the transformer decoder architecture to fiber identification without tearing textiles.
2) A dataset of textile surface images with accurate labeling information, such as textile categories and fiber types, is collected.
3) It is discovered in experiments that the transformer decoder’s cross-attention module can greatly increase fiber identification accuracy.
1 Proposed Method
Each type of fibers has its own unique surface characteristics. In the process of weaving, only physical blending and entanglement occur, so the unique surface characteristics of various fibers in blended textiles have not fundamentally changed. By deeply mining the visual features of various fibers, the accuracy of fiber identification can be improved in the case of small samples. Hence, FiberCT for image-based non-destructive textile fiber identification is proposed, which absorbs the aforementioned ideas and significantly addresses sample imbalance and small sample size challenges. As shown in Figs. 1(a) and 1(b), the overall framework of FiberCT is very simple. It contains a CNN backbone for the fiber spatial feature extraction module (FSFE-Module) and a set of transformer decoders for the fiber component decoding module (FCD-Module). The representations extracted by CNNs usually contain features from different fibers. Multi-head cross-attention operations in the transformer decoder in Fig.1(c) automatically learn the fiber features of each label through continuous querying[28-29], thereby reducing the blending between representations of different fiber types. In addition, an asymmetric loss[30]is introduced to further purify the extracted representations.
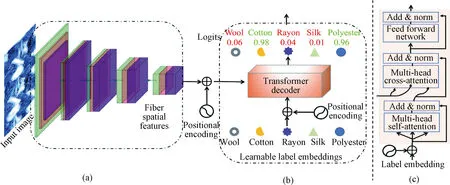
Fig.1 FiberCT framework:(a) FSFE-Module; (b) FCD-Module; (c) transformer decoder architecture
1.1 Fiber feature extraction
The FSFE-Module adopts a standard CNN backbone[31](ResNet50 by default) to extract fiber spatial features as shown in Fig.1(a). Given a textile fiber imageI∈RH×W×3as input, we extract its spatial featuresFs∈Rh×w×c0through the CNN backbone, whereHandWare the height and the width of input images,handware the height and the width of feature maps, andc0is the dimension of features. The features are then projected from dimensionc0to dimensioncin the linear projection layer to match the desired query dimension, and the projected features are reshaped toF∈Rh×w×c.They are sent to transformer decoders as keys and values along with queries (label embeddings)Q0∈RK×cand then perform cross-attention to pool type-related features, whereKis the number of fiber types.
1.2 Fiber component decoding
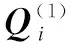
(1)
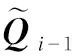
(2)
MH(Q,K,V)=Concat(A1,A2, ,Ah)WO,
(3)
whereQ,KandVare the query, the key and the value, respectively;CKis the dimension of the key;Ahis theh-th attention function;WOdenotes the weight parameter.
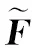
(4)
Subsequently, each label embedding gets better class-related features and updates itself according to
(5)
whereW1andW2are learnable weight parameters;b1andb2are bias parameters.
The label embeddingQ0∈RK×cis a learnable parameter that is updated layer by layer and gradually gets contextual information related to the input fiber images through multi-head cross-attention, thus implicitly establishing a relationship with the data.
At the last layer (layerL) of the transformer decoder, the queried feature vectorQL∈RK×cforKtypes of fibers is acquired, and then the feature of each type of fibersQL,k∈Rc,k= 1, 2, ,K, is projected to a logit value using a linear projection layer[29]followed by
(6)
whereWkandbkare parameters in the linear layer;P=[P1,P2, ,Pk]T∈RKrepresents the predicted probabilities of fiber types.
1.3 Loss function
The multi-head cross-attention in transformer decoders has been able to identify fiber types well, but the imbalanced fiber features in each image and small sample problems may interfere with the fiber classification effect. In order to better deal with the above problems, a simplified asymmetric loss is introduced, which has a good effect on alleviating the distribution of long-tail data in multi-label classification[30].
Given a textile fiber image as input, our model predicts its fiber type probabilitiesP=[P1,P2, ,Pk]T∈RK.Then, the loss for each training sample is calculated by
(7)
whereykis a binary label to indicate if the image has labelk;γ+andγ-are hyperparameters with default values,γ+=0 andγ-=1.The total loss is calculated by averaging this loss over all samples in the training dataset.
2 Experiments
To evaluate the proposed approach, FiberCT was compared to a number of state-of-the-art multi-label image classification architectures, including CU-Net and FabricNet for fiber identification in textile surface images. The average precision (AP) on each type of fibers and the mean average precision (mAP) over all types were adopted for evaluation. To better demonstrate the performance of the model, the overall precision (OP), the overall recall (OR), and the overall F1 measurement (OF1) were presented for further comparison, as well as the per-type precision (CP), the per-type recall (CR) and the per-type F1 measurement (CF1). In general, CF1, OF1 and mAP are comprehensive and hence are the most important metrics among all the above[12-13]. Since different thresholds might affect the experimental results, the threshold was set to be 0.5 in all experiments for comparison.
2.1 Implementation details
2.1.1Dataset
In the experiments, fabric surface images were taken by optical magnifiers at many clothes stores. A total of 26 types of fibers and 173 textile categories (fabrics with different blending ratios of the same types of fibers were one category) were collected. Figure 2 shows the statistical distribution of fabric components.
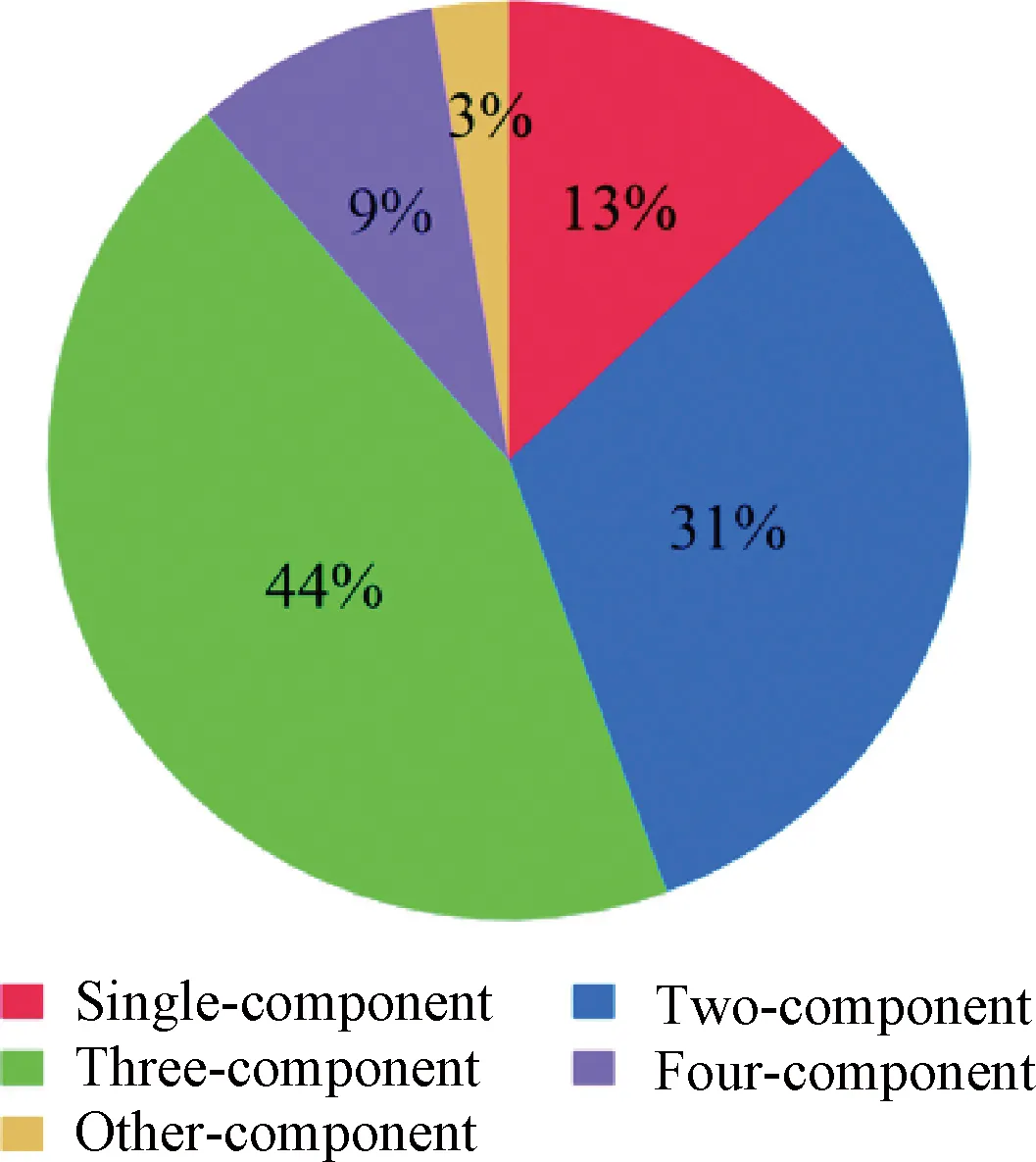
Fig.2 Statistics on fabric component dataset
In practice, only one fabric from the same brand and series was sampled to maximize the diversity of data. Five images at different points on each fabric were collected using commercially available optical magnifiers with a magnification of 50 times, and the magnifiers were connected to mobile devices via WIFI as shown in Fig.3.

Fig.3 Equipment and sampling procedures for collecting textile surface images:(a) a magnifier; (b) a magnifier connected to mobile devices via WIFI
Each time an image of a fabric was taken, the magnifier was rotated randomly to reduce the influence of textile textures, colors, pattern sizes and pattern directions on fiber identification. Figure 4 shows samples of three different fabrics. Label information of fabrics including fiber types and contents was also collected.
2.1.2Experimentalsetup
The proposed method FiberCT was evaluated on the fabric image dataset described in the previous subsection. In the experiment, 80% of the dataset was randomly selected from each fabric for training and 20% for validation. All images were resized to 224×224 as the input resolution and the size of the output feature from ResNet50 was 7×7×2 048. In the experiment,c=c0=2 048, so the size of the final output features in the FSFE-Module was 7×7×2 048. The extracted fiber features were fed into the FCD-Module after adding positional encodings and reshaping. For the FCD-Module, two transformer decoder layers were utilized for label feature updating. Following the last transformer decoder, a linear projection layer was added to calculate logit predictions for all fiber types. In the multi-head attention function,his 4. Flipping, brightness change, contrast change and zooming were used for data augmentation. All tested models were initialized with ImageNet trained weights, and they were further trained on the fabric image dataset. The model was trained 100 times using the Adam[33]optimizer with a batch size of 128, a true weight decay of 0.01, hyperparametersβ1of 0.9 andβ2of 0.999 9, and a learning rate of 0.000 1.
2.2 Fiber identification performance
Table 1 compares the performances of different multi-label image classification models, and the best results are shown in bold. The first three models (SSGRL[18], ML-GCN[19]and MS-CMA[34]) are GCN-based frameworks, while the next three models(C-Trans[35], TDRG[36]and M3TR[37]) are transformer encoder-based frameworks, and CU-Net[12]and FabricNet[13]are fiber identification models without breaking fabrics.
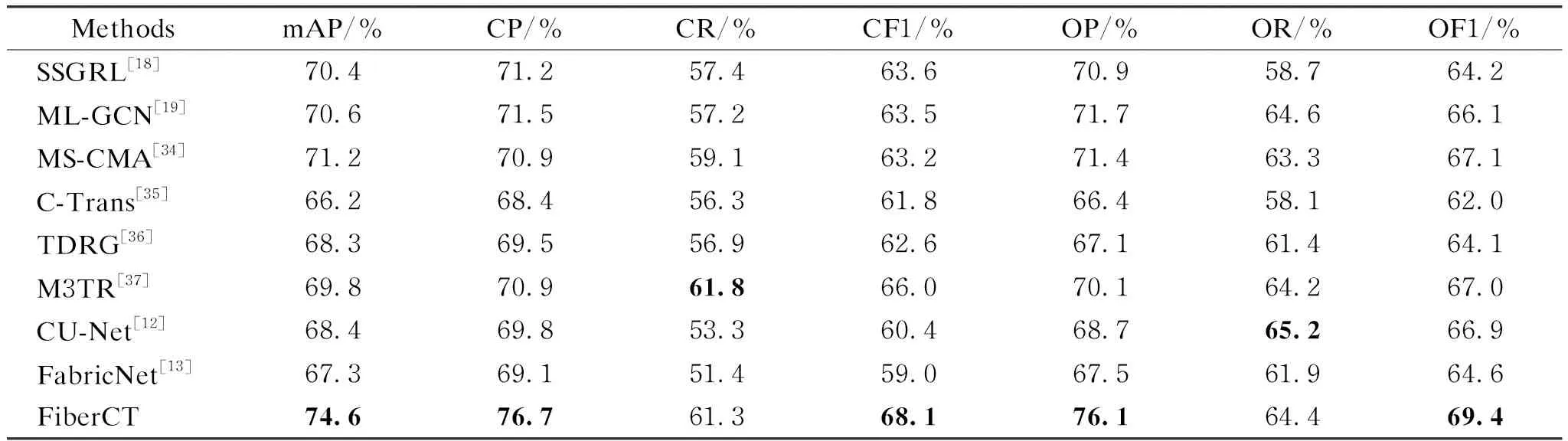
Table 1 Comparison of FiberCT and state-of-the-art methods on fabric image dataset
FiberCT consistently outperforms previous approaches on most major metrics (except CR and OR), demonstrating that FiberCT is more suitable for non-destructive textile fiber identification. Furthermore, it is noted that GCN-based networks surpass transformer encoder-based models in terms of fiber identification accuracy. This could be due to fiber entanglements, occlusions, and deformations during the textile weaving process. The variety of these changes and the small sample lead to unsatisfactory accuracy for all models, and transformer encoder-based models may exacerbate these adverse effects when the image is split into patches.
2.3 Ablation studies
To demonstrate the effectiveness of different components of FiberCT on textile fiber identification, ablation experiments were performed as shown in Table 2. FiberCT consists of an FSFE-Module (default ResNet50) and an FCD-Module (transformer decoder). Additionally, an asymmetric loss function (ASL) is incorporated into the framework. FiberCT ? FCD is the FiberCT without the FCD-Module. FiberCT ?ASL is the FiberCT without the ASL.

Table 2 Performance of FiberCT with various backbones and components
FiberCT performs marginally better (an increase in mAP of approximately 0.7%) in fiber recognition than FiberCT?ASL, implying that the ASL can further purify the extracted fiber representation as mentioned above. This effect is also demonstrated by the comparison of FiberCT?FCD and the baseline. FiberCT?ASL outperforms the baseline and FiberCT?FCD with an increase in mAP of 13.5% and 12.6%, respectively, demonstrating that the FCD-Module based on the transformer decoder can efficiently identify different types of fibers.
3 Conclusions
In this paper, a framework named FiberCT is proposed for textile fiber identification without breaking textiles. FiberCT employs convolutions to extract spatial features of fibers in the textile surface image and multi-head cross-attention modules in the transformer to adaptively decode different types of fabric components. Experiments demonstrate that the multi-head cross-attention modules in the transformer utilize label embeddings to query the existence of a type of fiber label and pool fiber type-related characteristics, which is extremely useful for textile fiber identification. Furthermore, the ASL can help FiberCT perform even better.
 Journal of Donghua University(English Edition)2023年4期
Journal of Donghua University(English Edition)2023年4期
- Journal of Donghua University(English Edition)的其它文章
- Image Retrieval with Text Manipulation by Local Feature Modification
- Multi-style Chord Music Generation Based on Artificial Neural Network
- Polypyrrole-Coated Zein/Epoxy Ultrafine Fiber Mats for Electromagnetic Interference Shielding
- Design of Rehabilitation Training Device for Finger-Tapping Movement Based on Trajectory Extraction Experiment
- High-Efficiency Rectifier for Wireless Energy Harvesting Based on Double Branch Structure
- Review on Development of Pressure Injury Prevention Fabric