
A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification
2021-06-19 13:04:58JuchengYangDiXingZhiqiangHuTongYao
Jucheng Yang |Di Xing |Zhiqiang Hu |Tong Yao
Abstract In recent years,vehicle re-identification has attracted more and more attention.How to learn the discriminative information from multi-view vehicle images becomes one of the challenging problems in vehicle re-identification field.For example,when the viewpoint of the image changes,the features extracted from one image may be lost in another image.A two-branch network with pyramid-based local and spatial attention global feature learning(PSA)is proposed for vehicle re-identification to solve this issue.Specifically,one branch learns localfeatures at different scales by building pyramid from coarse to fine and the other branch learns attentive global features by using spatial attention module.Subsequently,pooling operation by using global maximum pooling(GMP)for local features and global average pooling(GAP)for global feature is performed.Finally,local feature vectors and global feature vector extracted from the last pooling layer,respectively,are employed for identity re-identification.The experimental results demonstrate that the proposed method achieves state-of-the-art results on the VeRi-776 dataset and VehicleID dataset.
1|INTRODUCTION
Vehicle re-identification is a challenging task.Specifically,vehicle re-identification is the problem that matches images of a specified vehicle from different camera images.It is widely used in such hot fields as video monitoring[1],intelligent transportation[2]and urban computing[3].In the realworld,vehicle re-identification faces great challenges because cameras are set at different heights and angles.For example,when the viewpoint of the image changes,the feature extracted from the image in the front angle may no longer be applicable to that in the left rear angle.Therefore,we try to learn the discriminative features that belong to a certain vehicle from multi-view vehicle images.The proposed method focuses attention on the discriminative regions.When the viewpoint changes or the regions are missing in another camera image,the vehicle can still be identified.The multi-view images are shown in Figure 1.
Traditionalvehicle re-identification mainly employs license plate recognition technology[4].This technology identifies a specified vehicle by using its unique license plate ID.However,under the real and complicated traffic scenario,license plate may be covered or counterfeited.In such cases,license plate information cannot help retrieve the target vehicle.Therefore,vehicle re-identification based on appearance and attribute is widely used in real-world.In recent years,with the improvement of the representation capability of convolutionalneuralnetwork,severalvehicle re-identification approaches[5–7]based on deep learning have been designed to develop an effective global feature representation for each vehicle.Reference[6]also proposed a large dataset VeRi-776,which is widely used in today's vehicle re-identification research work.Another works of[8–10]make the distance between the same ID closer,while different IDs farther.However,both of the two existing strategies have some shortcomings in some aspects.These methods focus on learning global feature representation from an entire vehicle image,but they ignore the small but discriminative regions that only belong to a specified vehicle.In particular,when the viewpoint or shooting angle changes,the feature extracted in one angle may no longer be applicable to that in another angle,which may lead to a failed recognition.In such case,these discriminative regions play an essential role in vehicle re-identification.As shown in Figure 2,an obvious characteristic of vehicle A different from vehicle B is that vehicle A has a sunroof,while vehicle B does not.Therefore,no matter how the viewpoint of vehicle A changes,vehicle A will be recognised by focusing attention on the skylight region.Therefore,it is an urgent task to explore more efficient feature representation methods,which have the capacity to focus attention on the discriminative regions.

FI GUR E 1 Vehicles with the same ID look different at different angles

FI GUR E 2 The first row shows the vehicle A,and the second row shows the vehicle B.The boxes marked in red are vehicle A's skylight
The method to learn the discriminative and unique representation from multi-view vehicle images is explored.To this end,we propose a new two-branch network with pyramid-based local and spatial attention global feature learning(PSA).This network integrates local features based on pyramid and global feature that introduces spatial attention into a unified architecture.For pyramid-based local feature learning,we first divide the feature map extracted from convolutional layer horizontally into 3D sub-maps with various scales and then feed each sub-map into the classifier.This pyramid-based local feature learning branch can capture part-level feature information with different scales on the one hand.On the other hand,it can strengthen the connection of parts by using pyramid to solve the problem of part misalignment caused by inaccurate bounding box to a certain extent.For global feature learning,we propose a spatial attention layer to integrate the spatial relationship of feature map,which makes the model focus on the regions with discriminative information rather than the entire vehicle image.Therefore,introducing spatialattention is more robust to different viewpoints or partial occlusions in the vehicle image.Also,spatial attention has been proved effective in Reference[11].
To sum up,the proposed approach localises the discriminative regions by employing both local features and global feature.Our contributions are in three aspects:
(1)We propose a new two-branch PSA algorithm to learn the discriminative features from multi-view vehicle images.
(2)The proposed method combines local features based on pyramid and global feature,which introduces spatial attention collectively.In the two benchmark datasets,our experiments achieve the state-of-the-art results.
(3)To verify the superiority of our methods,we extensively conduct a series of comparative experiments on VeRi-776 dataset and VehicleID dataset.
The rest of this paper is organised as follows.Section 2 introduces the related work.Section 3 describes the proposed PSA algorithm in detail.Section 4 shows the experimental results to verify the superiority of our method.Section 5 is the conclusion of this paper.
2|RELATED WORK
In this section,we briefly look back the related works in the field of vehicle re-identification.Hongye et al.[12]proposed a large-scale dataset VehicleID under the natural monitoring.They proposed a deep relative distance learning(DRDL)approach.Ke et al.[13]published two high-quality vehicle datasets,namely VD1 and VD2.The two datasets included 1,097,649 and 807,260 vehicle images captured in different cities,respectively.
Vehicle re-identification:Feris et al.[14]proposed a novel approach for visual detection and attribute-based search of vehicles in crowded surveillance scenes.First,vehicles were classified according to different attributes.Then,the vehicles with similar attributes were retrieved in dataset.In 2015,Linjie et al.[15]proposed a dataset CompCar for model classification or attribute prediction.But the task is stayed in the coarse granularity,which was not fine enough for ID identification.Recently,the proposal of VeRi-776 dataset and VehicleID dataset has made the task of vehicle-level recognition gain more attention.Based on these two datasets,many vehicle reidentification methods have been proposed.Yuqi et al.[16]introduced the attribute recognition into vehicle re-identification framework,in order to explore the discriminative features.Jinjia et al.[17]proposed to localise the discriminative regions by using spatial transformer network.Yanzhu et al.[18]proposed a vehicle re-identification method,which considered region of interests'deep features as discriminative identifiers.In summary,local regions-based methods are vitalfor vehicle re-identification tasks.
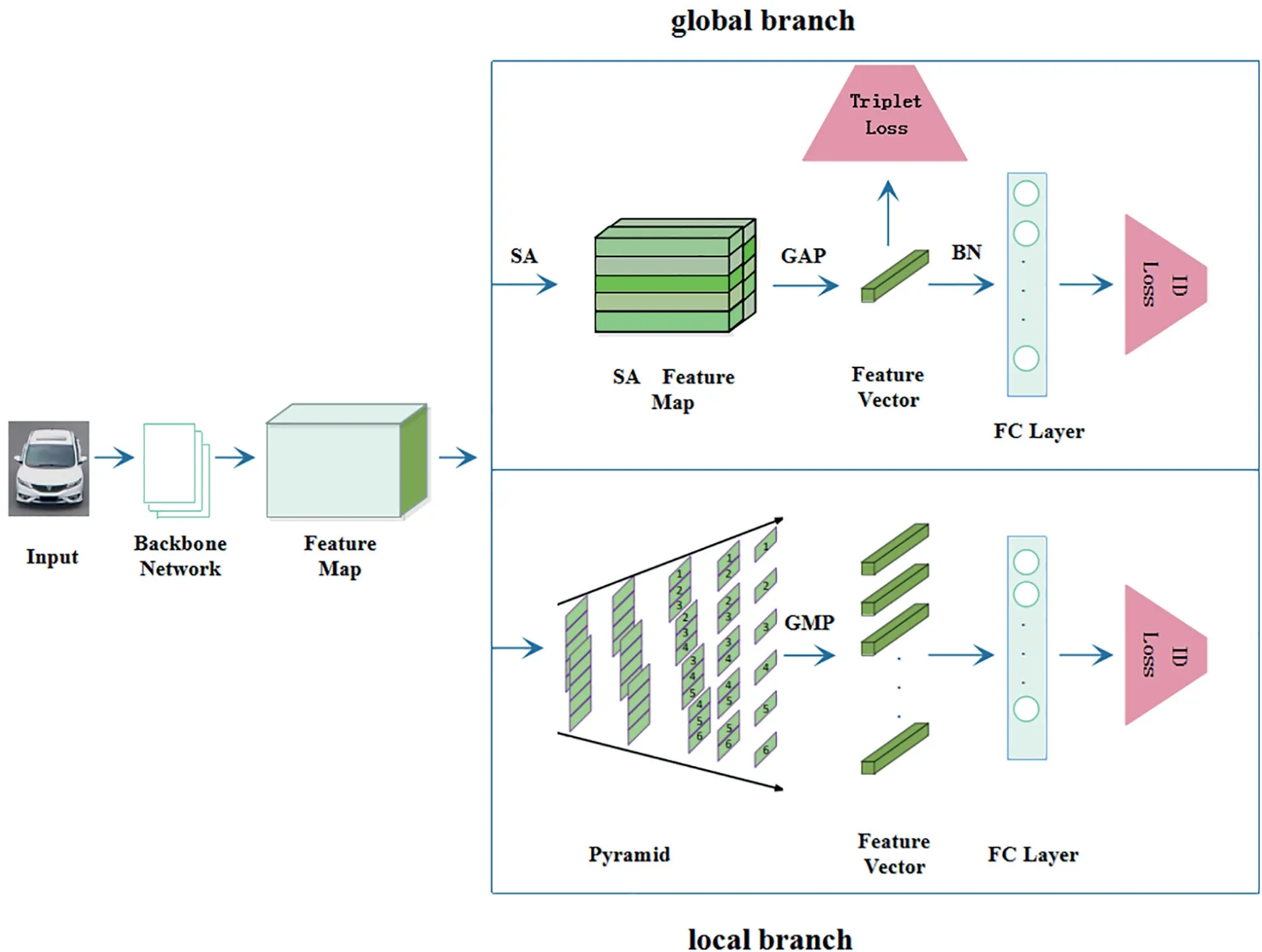
FI GUR E 3 The architecture of the proposed model.The upper branch learns global feature.Meanwhile,it adds spatialattention layer before globalaverage pooling(GAP)layer.Finally,the globalfeature map is optimised by triplet loss and ID loss.For better results,we add BatchNorm layer before ID loss.The under branch learns local features at different scales by building pyramid from coarse to fine
Fine-grained recognition:Vehicle re-identification is a typical example of fine-grained vehicle recognition.References[19–21]are all noteworthy vehicle classification works.Xiao et al.[22]introduced reinforcement learning and found the discriminative regions adaptively in fine-grained regions by means of weak supervision.However,the accuracy of the model based on local features was not high.Tsungyu et al.[23]proposed a bilinear structure to obtain local paired features.However,because there are differences between cameras,the images are different,too.Therefore,fine-grained vehicle recognition cannot learn effective and distinctive local features,resulting in inaccurate identification.
3|PROPOSED METHOD
In order to learn the discriminative features from multi-view images,we propose a new two-branch PSA.This network integrates local features based on pyramid and global feature that introduces spatial attention into a unified architecture.In this section,we first give an overview of PSA.Then,we describe the structure of the two-branch PSA network in detail.Finally,we describe the optimisation strategy in detail.
3.1|Overview of proposed framework
The proposed framework consists of two modules:local features learning network based on pyramid and global feature learning network that introduces spatial attention layer.As shown in Figure 3,the given vehicle image is first fed into the backbone network,and then,a 3D tensor is output.Second,through the processing of the two-branch PSA,the multi-scale local features in local branch and the global feature that introduces spatialattention in global branch are extracted.Third,for each feature map,global maximum pooling(GMP)and globalaverage pooling(GAP)are applied to a pooling layer to capture statistical properties of diverse channels for local branch and global branch respectively.In order to reduce redundancy,we also perform dimensionality reduction operation to reduce feature vectors’channels.Finally,the ID Loss is employed for each feature vector separately.Furthermore,we take advantage of Triplet Loss,which considers the global feature vector generated by global branch as the input to make the distance of positive sample pairs closer and the distance of negative sample pairs farther.
3.2 |Pyramid-based local and spatial attention global feature learning
3.2.1 |Pyramid-based localfeature learning
In this section,the process of extracting multi-scale local features in local branch is introduced in detail,which is inspired by the study in Reference[24].
Although the study[24]was developed for pedestrian reidentification,as the specific applications of image retrieval,there are some similarities between pedestrian re-identification and vehicle re-identification.For example,the proposed method in Reference[24]partitioned feature map horizontally into sub-maps with different scales,which can not only solve the problem of learning local features such as cloth logo,backpack,and shoes but also solve the problem that parts cannot be well-aligned.Similarly,vehicle images can also be divided into several parts horizontally to better learn the distinguishing features such as skylights,inspection sign,car light,and wheel.
There is a set of vehicle imagesX={I1,I2,…,IN}captured by different cameras,whereNis the number of images.The aim of vehicle re-identification task is to search the same vehicle from different images.We inputXinto the backbone network(b)and then,we get a 3D tensorF=B(i),whose size isH×W×C,whereCis the number of channels,andWandHare the width and height of the tensor,respectively.In local branch,we need to extract pyramid-based multiscale local features.So we first partition the feature mapFinton(in this paper,n=6)parts in the horizontalorientation,and the size of each basic part is:(H/n)×W×C.Second,we number these six basic parts 1–6.Third,the division rules based on pyramid are as follows,and we can see from Figure 3 that:(1)in the bottom level of the pyramid,there are two offshoots,corresponding to{1,2,3,4,5}and{2,3,4,5,6}these five adjacent basic parts,respectively.(2)In the second level of the pyramid,there are three offshoots,corresponding to{1,2,3,4},{2,3,4,5}and{3,4,5,6}these four adjacent basic parts,respectively.(3)In the third level of the pyramid,there are four offshoots,corresponding to{1,2,3},{2,3,4},{3,4,5}and{4,5,6}these three adjacent basic parts,respectively.(4)In the fourth level of the pyramid,there are five offshoots,corresponding to{1,2},{2,3},{3,4},{4,5}and{5,6}these two adjacent basic parts,respectively.(5)In the fifth level of the pyramid,there are six offshoots,corresponding to{1},{2},{3},{4},{5}and{6}these basic part,respectively.As for implementation,we take advantage of the pooling operation whose filters'kennelsize is set according to this pyramid structure to achieve this division.Specifically,for each offshoot of the pyramid,we employ a pooling operation,and the setting of filter's kennelsize is kept consistent with the size of this offshoot.Then,we get a series of part-levelfeature vectors with size1×1×C.Afterwards,each part-level feature vector is convoluted by a shared filter whose kernelsize is1×1into a size1×1×cfeature vector.Finally,we input this feature vector into classifier,which considers softmax function as ID Loss.
3.2.2 |Spatialattention global feature learning
In this section,we elaborate how to introduce the spatial relationship of globalfeature map into the model.In this way,the model willbe focused on the regions where the information is distinguished rather than the entire image.Instead of passing the feature map obtained by the last convolutionallayer through GAP layer directly,we assign different significance to different locations in globalfeature map extracted from the last convolutional layer by using spatial attention layer.The significance or attention weight of a location depends on the total degree of activation of all the channels at this location.Through training,all the learned attention weights compete with each other to highlight their importance,so that the model can cover more image details,including distinguished regions.
The calculation rules of attention weights are as follows:
First,given a feature mapFwith sizeC×H×Wextracted from the backbone networkB,the sum of channels for each location on the feature mapFyields a 2D matrixAwith sizeH×W.MatrixAis defined as:
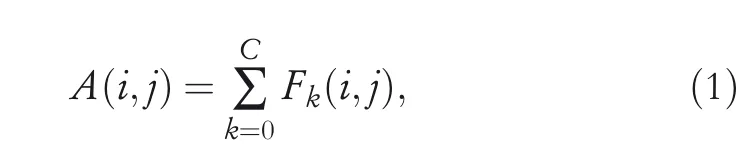
whereFk(i,j)is the element of thei-th row andj-th column ink-th channel of original feature mapF.Cis the number of channels,k∈{0,1,2…,C}.
Then,a softmax function is applied to active the summed matrixA.So,the elementp(i,j)in matrixArepresents the importance or attention weight of the corresponding position.p(i,j)is defined as:
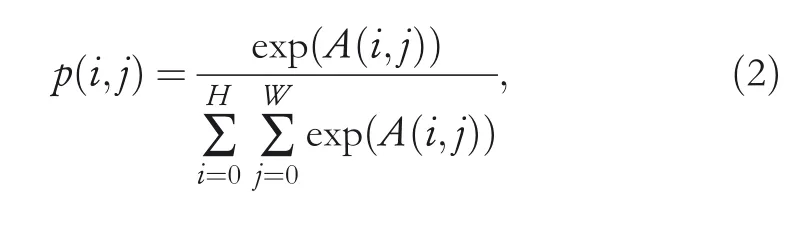
whereWandHare the width and height of the tensor,respectively.
Second,the activated valuep(i,j)is multiplied to the original feature mapFalong the channel axis.Therefore,the outputOwhich has been assigned different importance for different positions can be written as:
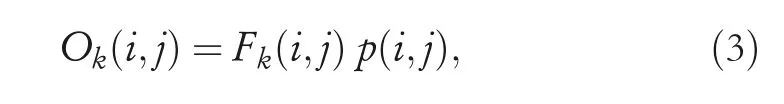
whereOk(i,j)is the element of thei-th row andj-th column ink-th channelof activated feature mapO,k∈{0,1,2…,C}.
Next,the outputOis passed into the GAP layer to perform pooling operation,and then,a feature vector with size1×1×Cis obtained.Similar to the operation of local feature learning,this feature vector is convoluted by a filter with kernel size1×1into a one with size1×1×c,Finally,this feature vector is fed into the classifier which considers softmax function as ID Loss.Furthermore,we also consider triplet loss to make the distance of positive sample pairs closer and the distance of negative sample pairs farther.
3.3 |Optimisation
As for training,we employ both local features and global feature to predict ID.The finalloss functionLis defined as:
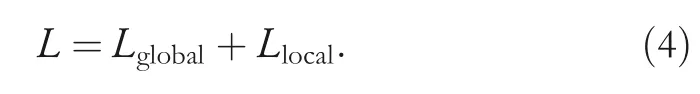
The first item of Equation(4)represents the global loss,which is defined as:

The first item of Equation(5)considers softmax loss as ID Loss,which is defined as:
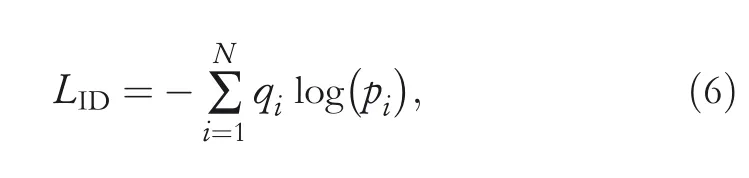
whereNis the class number of vehicles,pi∈[0,1]is the prediction probability of classi,andqi∈{0,1}is the ground truth label of classi.
The second item of Equation(5)considers triplet loss,which is defined as:
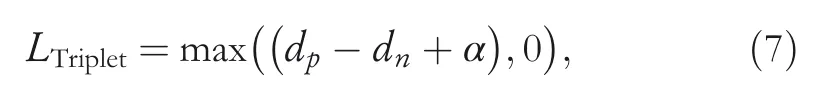
wheredpis the distance of the pair of positive samples,anddnis the distance of the pair of negative samples,andαis the margin of triplet loss.
The second term of Equation(4)represents local loss,which is defined as:

whereSis the number of offshoots,Lsindicates the softmax loss of thes-th offshoot in local feature learning.Lsis defined as:

4|EXPERIMENT
4.1 |Datasets and evaluation metric
We evaluate the proposed PSA model on two large datasets:VeRi-776 and VehicleID.
The VeRi-776 dataset is a real-world benchmark dataset for vehicle re-identification.It includes 50,000 images of 776 vehicles.Specifically,37,778 images of 576 vehicles are employed for training,and 11,579 images of 200 vehicles are employed for testing.Each vehicle is photographed by 2–18 cameras in different viewpoints,resolutions and occlusion conditions.In addition,it contains rich attribute information,such as type,color,brand,license plate,and bounding box.When testing,we take one image of each vehicle captured from each camera as a query.Other images of this vehicle are applied as gallery.For VeRi-776 dataset,we extract 1678 images of 200 vehicles as query set and 11,579 images of 200 vehicles as gallery.
VehicleID dataset is also a large dataset for vehicle reidentification.It is a dataset of images captured by multiple cameras in a small Chinese city.It includes 221,763 images of 26,267 vehicles.This dataset is divided into two parts:one part is 110,178 images of 13,134 vehicles for model training,and the other part is 111,585 images of 13,133 vehicles for model testing.In addition,due to the large test set,it is divided into three subsets,namely small,medium and large test set,containing 800,1600 and 2400 vehicles,respectively.
On the basis of following the common evaluation protocol in the field of vehicle re-identification,we employ cumulative match characteristic(CMC)urve and mean average precision(mAP)as the indicators to evaluate the performance of proposed method.CMC curve is also known as rank curve.Rank-1 is the probability of being right the first time,and rankk is the probability of being right within thek-th time.mAP is mean Average Precision.In the period of evaluation of mAP,two parameters are mainly referred to precision rate P and recall rate R.mAP is obtained by averaging the area enclosed by allP-R curves.The larger mAP value,the higher accuracy of model.
4.2 |Implementation details
We employ Resnet50[25]that pre-trained by Imagenet as the backbone network.For vehicle re-identification task,we change the structure of this backbone and delete the average pooling layer and its subsequent layers.Also,we change the slide step of the last convolutional layer from two to 1.After the pretreatment,we get a 3D tensor whose size is 24×8×1024.For pyramid-based local feature learning,we first apply GMP whose kennel size is set according to pyramid structure to divide the feature map extracted from backbone into several feature vectors containing different local information.Then,a convolution operation with kernelsize 1×1 is employed for each feature vector to perform the dimensionality reduction operation and the final 512D local feature vector is obtained.Finally,we employ ID Loss to predict vehicle's ID.For spatial attention global feature learning,we first apply spatial attention layer followed by GAP on the 3D tensor.Next,convolution operation with kernel size 1×1 is employed to extract the final 512D global feature vector.Finally,ID loss and triplet loss are jointly employed to predict vehicle's ID.
All the input images augmented by random mirror are resized into 384×128.We employ an Adam optimiser with the momentum value of 0.9 and the weight decay value of 5×10-4.During training,we randomly select 16 vehicles and four images for each vehicle.Therefore,the batch size of train set is 64.The learning rate of parameters in pretrained model starts from 0.1,and the learning rate of other parameters starts from 0.01.The learning rate is multiplied by 0.1 every 40 epochs,and the totalnumber of epochs is 60.Our experiment is performed on a NVIDIA TITAN RTX GPU using the pytorch framework.The visualisation results on VeRi-776 dataset are shown in Figure 4.
4.3 |Comparison with state-of-the-art
The proposed method is compared with other state-of-the-art methods on two datasets.
4.3.1 |VeRi-776
We strictly abide by the cross-camera search evaluation protocol and give the comparison results with other approaches on VeRi-776 in Table 1.The analysis process is as below.
Note:Bold for comparison with the results of other algorithms in the table.
First,as you can see,the proposed PSA has achieved a better performance among the listed state-of-the-art latest methods,except SAN[30].As far as we know,SAN is also a part-based approach and strong competitor.Compared with SAN,the proposed PSA has approximate Rank-1 accuracy and Rank-5 accuracy,but better mAP(mAP increased by 3.4%).It demonstrates that our pyramid-based feature division method is more effective,because feature representation with differentgranularities are complementary and can cover more distinguishing details.
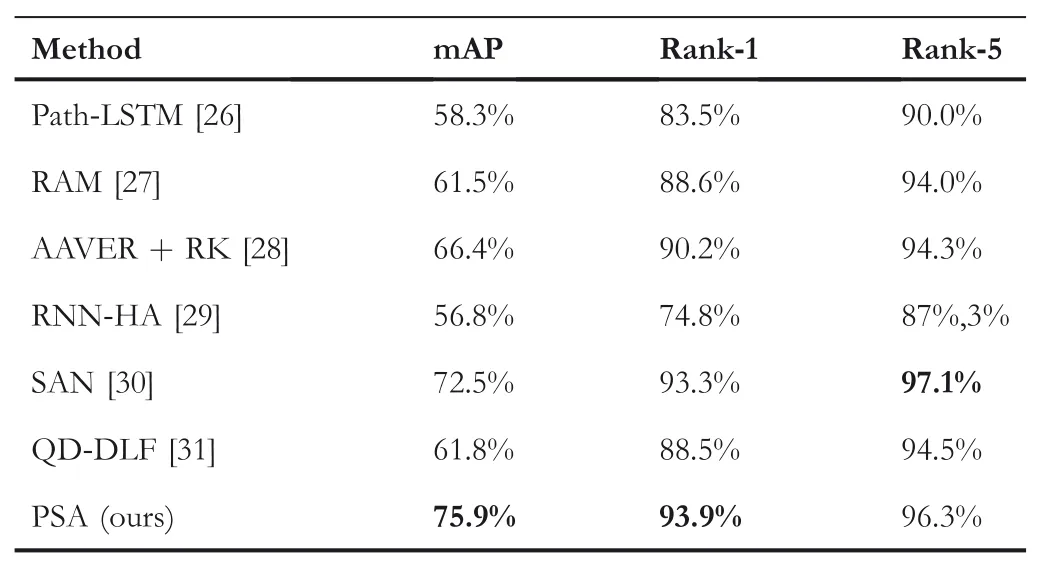
TA B LE 1 Comparison results on VeRi-776 for vehicle re-identification

FI GUR E 4 The visualisation results on VeRi-776 dataset.The images marked with red and dotted bounding box are mismatched and other images are matched correctly
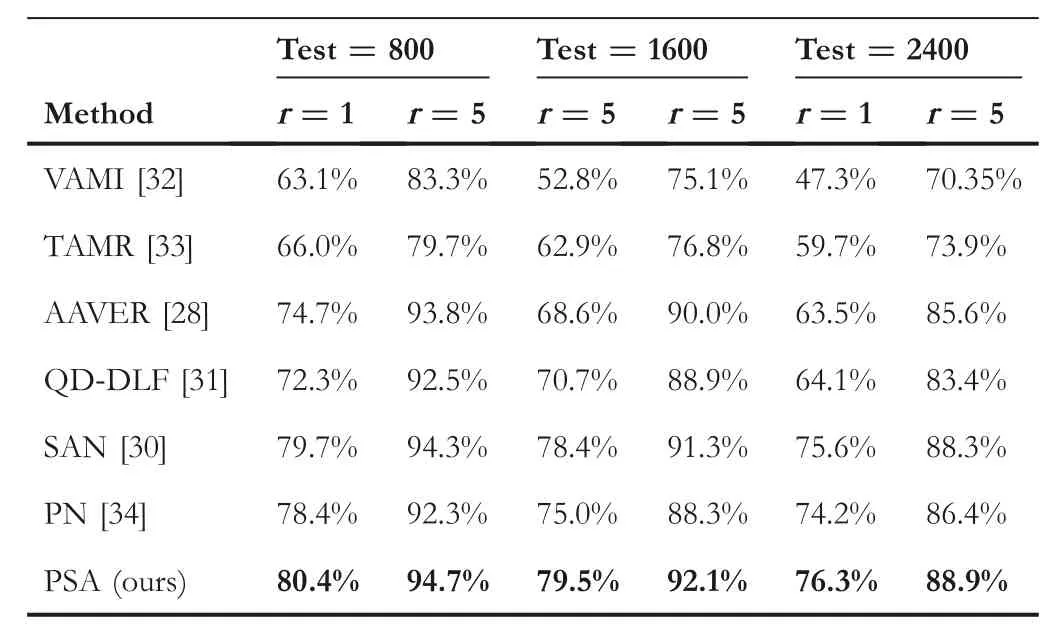
TABL E 2 Comparison results on VehicleID for vehicle reidentification
Second,our method achieves better results without considering any other additional information compared to Path-LSTM [26]considering spatio-temporal information,RAM[27]considering color and model information,and AAVER [28]considering orientation information.This observation proves that using both global feature and local features can capture the distinguishing information that belongs to a special vehicle without help of vehicle's attribute information can achieve better performance.
4.3.2 |VehicleID
The test set is huge,so it is divided into three subsets.In Table 2,we show the comparison between the proposed PSA method and other recent methods.As can be seen from Table 2 that the proposed PSA obtains the highest Rank-1 accuracy and Rank-5 accuracy.Specifically,the Rank-1 accuracy are 80.4%,79.5%,and 76.3%for Test800,Test1600 and Test2400,and the Rank-5 accuracy are 94.7%,92.1%and 88.9%for Test800,Test1600 and Test2400,respectively.The specific analysis process is described below.
Note:Bold for comparison with the results of other algorithms in the table.
First of all,it can be seen that the performance of the proposed PSA method is higher than that of models such as VAMI[32]and TAMR[33]that consider integrating attention to appearance feature extraction.This may be due to the proposed PSA method take advantage of pyramid-based local features to consider regions where spatial attention cannot be focused but distinguished,too.
Second,compared with SAN[30]and QD-DLF[31]partbased models,the proposed pyramid-based part division method captures part-level feature information with different scales,which covers more information,resulting in better performance.
Finally,PN[34]localises discriminative parts by detecting local regions,which depends on the objection detection model.The proposed PSA takes advantage of spatialattention-basedglobalfeature and pyramid-based local features to search the difference regions,leading to a better performance.

TA B LE 3 Comparisons of the proposed method with triplet loss or without triplet loss on VeRi-776
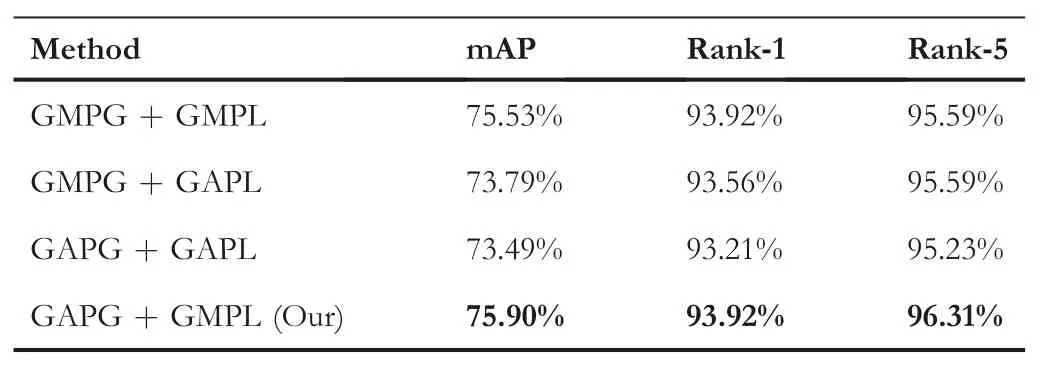
TA B LE 4 Comparison of different pooling strategies on VeRi-776.
4.4 |Component analysis
4.4.1 |Effectiveness of triplet loss
As shown in Table 3,the performance of using Triplet Loss and ID Loss together in global branch is slightly better than the performance of using ID Loss alone.This is because softmax loss is good at learning inter-class information.It only cares about the probability that a category is predicted correctly.So features optimised by softmax loss are radialin the embedding space.In other words,the distance between the same class may be large.Triplet Loss makes the distance between intra-class closer and inter-class further.So we combine ID Loss and Triplet Loss to train the model.However,for the features in the embedding space,ID Loss mainly optimises the cosine distance,while Triplet Loss mainly optimises the Euclidean distance.So the inconsistency of optimisation goals may lead to oscillate.Therefore,we employ BatchNorm to normalise features.We define the features without BatchNorm asf,and the features after BatchNorm asf’.fandf’will be employed for triplet loss and ID Loss respectively.For the local branch,we did not employ Triplet Loss considering the time cost.
4.4.2 |Pooling strategies
In order to further study the impact of the two pooling methods of GMP and GAP,we design a series of experiments on the VeRi-776 dataset.The research results are shown in Table 4.
First,we can see from Table 4 that the performance of using GMP on local features is far better than using GAP on them.This is because for localregion,we need to pay attention to the salient features of this region.GMP just eliminates the influence of irrelevant or unimportant features by selecting the max value of this region.Therefore,the final experiment chooses to employ GMP to perform pooling operation for local features.
Second,as shown in the second and fifth rows of Table 4,the performance of using GAP on global feature is slightly better than using GMP for it.This is because for the entire vehicle image,we need to control the overallinformation of image.GAP retains the complete information by taking average of the feature values.Therefore,the finalexperiment chooses to employ GAP to perform pooling operation for global feature.
5|CONCLUSION
A new two-branch network with PSA is proposed.Compared with the previous methods,the proposed PSA takes advantage of multi-scale partial information and attentive global information for re-identification,which successfully enhanced the discriminative ability of features,and finally formed a more robust feature representation for vehicles.The proposed PSA can learn the discriminative features and effectively avoid the adverse effects caused by changes in viewpoint.It showed good performance on the two benchmark datasets.In the future,we plan to explore more effective attention modules,so that the model can cover the details of the entire image more comprehensively.
ACKNOWLEDGEMENTS
This work was supported by the National Natural Science Foundation of China (Grant No.61702367,61976156),Tianjin Science and Technology Commissioner project(No.20YDTPJC00560) and the Research Project of Tianjin Municipal Commission of Education(Grant No.2017KJ033).
 CAAI Transactions on Intelligence Technology2021年1期
CAAI Transactions on Intelligence Technology2021年1期
- CAAI Transactions on Intelligence Technology的其它文章
- Design and voice-based control of a nasal endoscopic surgical robot
- CHFS:Complex hesitant fuzzy sets-their applications to decision making with different and innovative distance measures
- Deep learning-based action recognition with 3D skeleton:A survey
- TWE-WSD:An effective topical word embedding based word sense disambiguation
- Survey on vehicle map matching techniques
- A survey on adversarial attacks and defences