
Survey on vehicle map matching techniques
2021-06-19 13:05:06ZhenfengHuangShaojieQiaoNanHanChanganYuanXuejiangSongYueqiangXiao
Zhenfeng Huang| Shaojie Qiao|Nan Han|Chang-an Yuan|Xuejiang Song| Yueqiang Xiao
1Schoolof Software Engineering,Chengdu University of Information Technology,Chengdu,China
2Schoolof Management,Chengdu University of Information Technology,Chengdu,China
3Schoolof Computer and Information Engineering,Nanning Normal University,Nanning,China
4Guangxi College of Education,Nanning,China
5Chengdu Tanmer Technology Co.,Ltd,Chengdu,China
Abstract With the development of location-based services and Big data technology,vehicle map matching techniques are growing rapidly,which is the fundamental techniques in the study of exploring global positioning system(GPS)data.The pre-processed GPS data can provide the guarantee of high-quality data for the research of mining passenger’s points of interest and urban computing services.The existing surveys mainly focus on map-matching algorithms,but there are few descriptions on the key phases of the acquisition of sampling data,floating car and road data preprocessing in vehicle map matching systems.To address these limitations,the contribution of this survey on map matching techniques lies in the following aspects:(i)the background knowledge,function and system framework of vehicle map matching techniques;(ii)description of floating car data and road network structure to understand the detailed phase of map matching;(iii)data preprocessing rules,specific methodologies,and significance of floating car and road data;(iv)map matching algorithms are classified by the sampling frequency and data information.The authors give the introduction of open-source GPS sampling data sets,and the evaluation measurements of map-matching approaches;(v)the suggestions on data preprocessing and map matching algorithms in the future work.
1|INTRODUCTION
In this era of Big data,a huge volume of data is being produced every day,which has been utilized to conduct the research studies.After extracting and filtering the data,researchers have used specific rules and designed mathematical models to analyze and discover knowledge from the data[1]in order to obtain useful information for people’s daily activities.With the rapid development of location-based services,trajectory data[2,3]are growing exponentially,which represent the continuous movement of objects,including information such as latitude and longitude.These continuously growing trajectory data assist in the intelligent transportation in several application scenarios.As shown in Figure 1(a),trajectory data can serve the upper application layer in the research of intelligent transportation,for example taxi passenger points of interest mining[4],updating urban road network[5],vehicle abnormal behaviour detection [6]and ride-sharing taxi scheduling[7].Inevitably,the first step is to correct the deviation of trajectory data with map-matching techniques.Then,the corrected data is analyzed and applied to the application layer.In addition,the data generated by the upper application can also be used in the data layer.In practice,there is a certain deviation between the actual driving routes and global positioning system(GPS)sampling data because of the satellite positioning error[8].In addition,“Since the vehicle navigation system was proposed[9–11],the problems of inaccurate positioning and system abnormality have always existed.In addition,several scholars reported that the navigation system initially needs to perform GPS point correction on the electronic map so that the navigation function can be used effectively[12].”In the research of map matching,a Kalman filter is proposed for vehicle navigation[13],which mainly uses the covariance matrix to determine the specific location of the vehicle when the signal is blocked,thus completes the map-matching process of the vehicle position.Hereafter,based on the Kalman filter,a multihypothesis technique for map matching is proposed based on the principle that the likelihood function is used to infer the target position of the vehicles[14].Figure 1(b)describes the workflow of the vehicle intelligent navigation system.Intuitively,after the mapmatching step,the navigation function can work properly,such as route guidance,velocity control,route visualization and position location.As shown in Figure 1,map-matching technique is the core of navigation technology and plays an essential role in the field of intelligent transportation and intelligent navigation system[15,16].
In recent years,with the rapid development of wireless network technology,map-matching techniques have wide application scenarios,such as indoor navigation[17],unmanned aerialvehicle flight[18],robot training[19]and so on.Therefore,it is necessary to use map-matching techniques to rectify the deviation of positions w.r.t.trajectory data.As for the use of trajectory data,we focus on the floating car data(FCD)collected by moving vehicles in the map-matching environment due to its popularity in transportation systems.
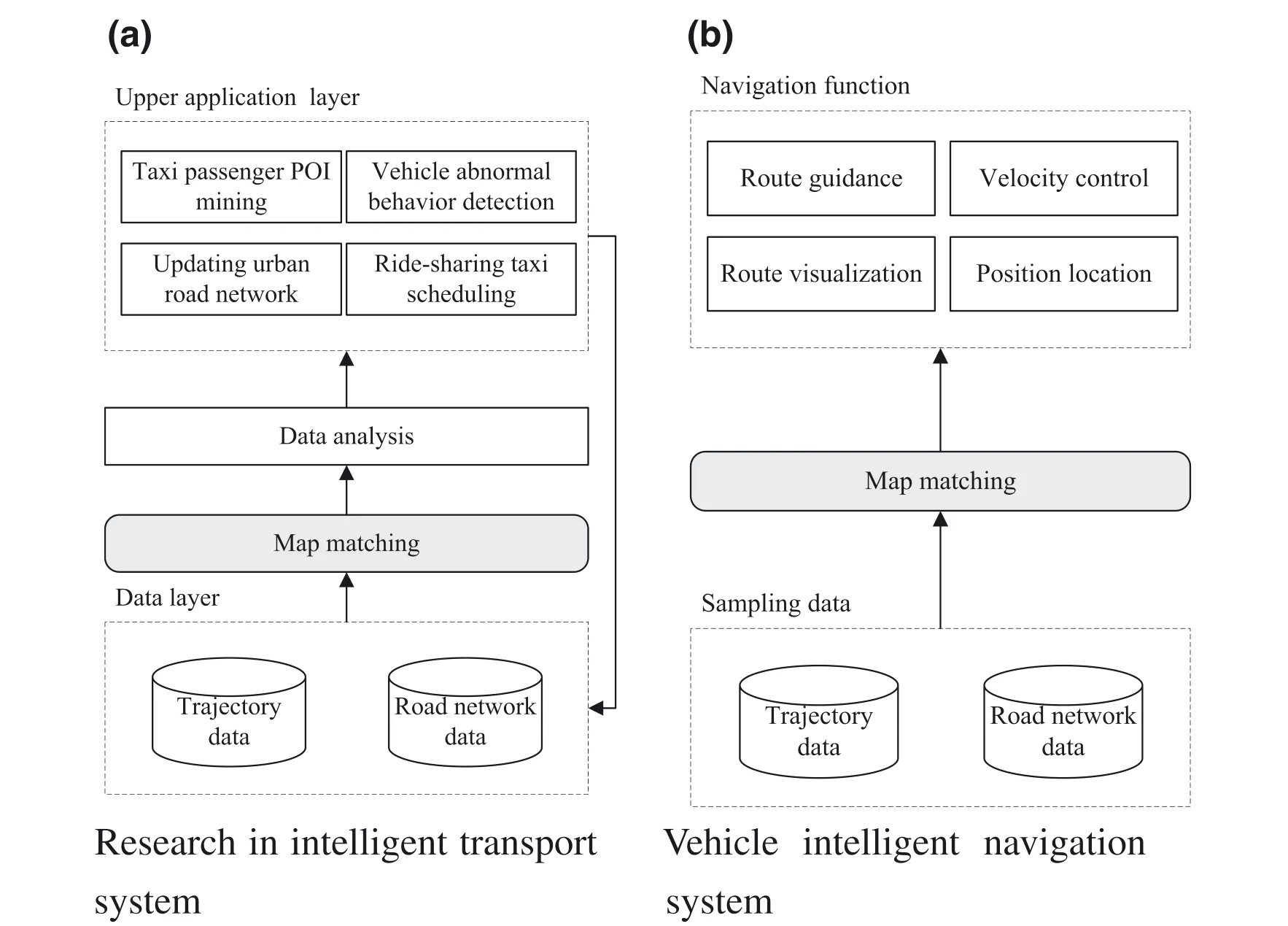
FI GUR E 1 Application scenario of map-matching techniques
As shown in Figure 2,map-matching technique is a complete process including FCD preprocessing,road data preprocessing and selection algorithms[20].The phase of data preprocessing aims to process the originalFCD and road data by using many different kinds of methods to obtain the ideal experimentalresults.The phase of selection algorithms focuses on selecting an appropriate one among many algorithms according to the actual situation.In the phase of map matching,the task is to design appropriate map-matching algorithms on the processed experimentaldata.In the practicalapplications,in the absence of such a process,it will have a significant impact on the experimental results.The phase of visualized results output is an additional step after map matching to visualize the experimental results.By using geographic information system(GIS)tools[21],we can find whether the trajectory data are correctly mapped to the actual path in the electronic map.
The research method of software engineering is very popular,which needs to establish the review goal and research method,and then draws a conclusion[22–24].In[25],researchers believed that a systematic framework can effectively assign effective plans and strategies to assist practitioners.Ghazi et al.[26]reported that the demand for empirical research on software engineering is growing,and by following the research methods of software engineering to determine the problems researchers face in the investigation design and mitigation strategies.However,in order to comprehensively review the map-matching techniques,we review map-matching techniques from a new perspective,including the data preprocessing,selection algorithms,the open source data sharing and evaluation measurements.Starting off the point of view of technology,we aim to summarize the original FCDand road data preprocessing rules,and classify map-matching algorithms from different aspects.Overall,our contributions are as follows in this survey:(i)We give a detailed review of the data preprocessing process,which is rarely mentioned in the map-matching problems,and operation methods and significance of the rules are also presented in the Tables 1,2 and 3;(ii)We categorize the map-matching algorithms according to the GPS sampling frequency and the data information;(iii)Open source trajectory data sets and common evaluation measurements are provided.We do not only describe the data sets,but also provide their downloading websites.In addition,we have made the necessary explanation of the evaluation measurements and(iv)Based on the current trend of map-matching techniques,we provide the future development direction.
The rest of the study is organized as follows:In Section 2,we first provide the necessary definition of map matching and analyze the existing research work.Then,a methodology is given in Sections 3 and 4.Finally,we propose the future direction of map matching and give conclusion in Section 5.
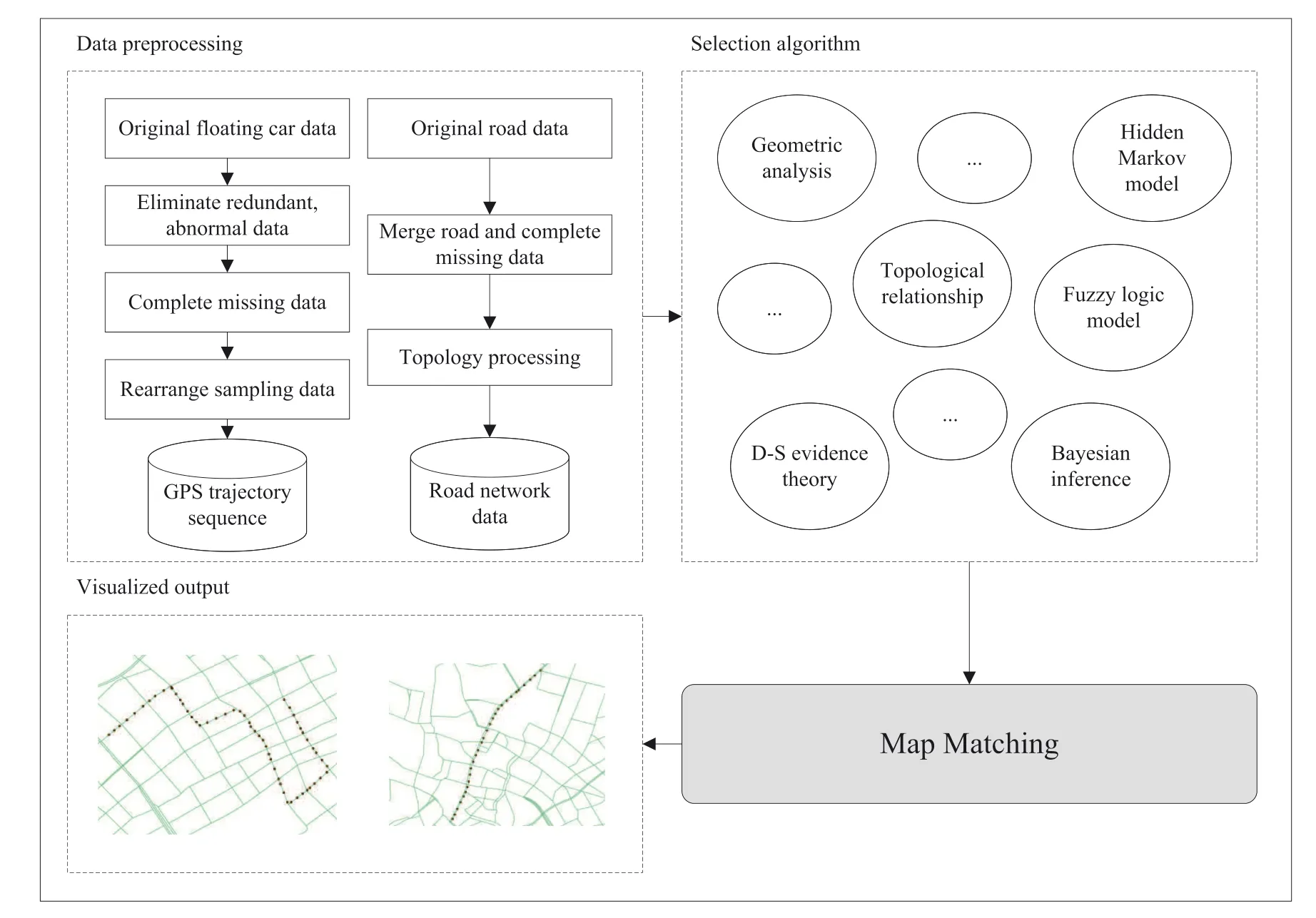
FI GUR E 2 Diagram of map-matching techniques
2|PRELIMINARY
2.1 |Problem definition
Definition1(FCD)In Figure 3,given a set of FCDT=(P1,P2,P3,…,Pn),where each pointPiis a GPS trajectory point generated by the order of timestamps,and eachPiincludes the information such as ID number,latitude and longitude,time,vehicle angle,vehicle speed etc.The three basic elements of FCD include longitude,latitude and time information.The longitude and latitude represent the position of thevehicle,and the GPS trajectory of the vehicle can be determined according to the time information.The more fields FCD contains,the more conditions the matching algorithms can take into consideration,and the higher is the matching accuracy.

TABL E 1 Preprocessing rules of noise filtering

TABL E 2 Preprocessing rules of machining data
TABL E 3 Preprocessing rules of road data
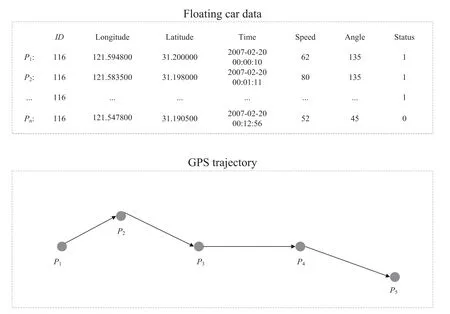
FI GUR E 3 Description of FCD
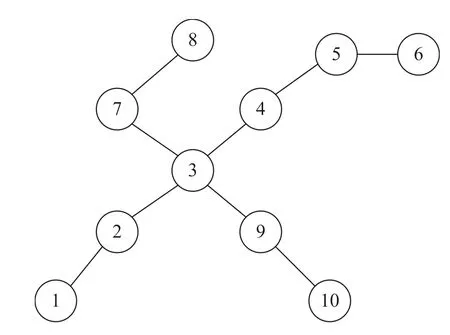
FI GUR E 4 Road network structure
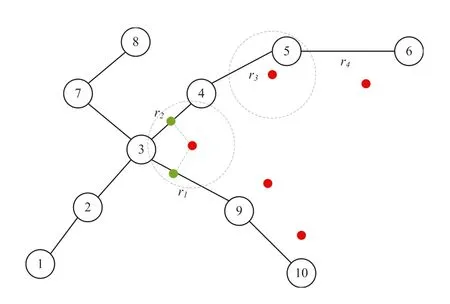
F I GURE 5 Candidate segment
Definition2(Road network structure)Because of the complexity of urban road network structure,the topology model can be used to clearly express the relationship of roads[27].The original road data must be constructed in to a topological graph,please refer to Section 3.2.Assuming that the point is a road junction and the line represents a road segment,then allroad network structures can be represented as shown in Figure 4 and Figure 5.For example,there are two interlaced roads.One road is called‘Beijing Road’,which contains five road segments and six road junctions numbered from 1 to 6.Another road is called‘Nanjing Road’,which consists of four road segments and five road junctions with intersection numbers 3,7,8,9 and 10.Straightforwardly,the intersection of‘Beijing Road’and‘Nanjing Road’is the third road junction.Given a urban road network data,it can be expressed by an undirected graph network G=(V,E),where V is a set of vertices representing road segments intersection,E is a set of edges representing the road segments.In the phase of road data preprocessing,the road segments can be stored by the methods proposed in[28,29],while the road segments intersection is stored by the method introduced in[30].
Definition3(Candidate segment)In map matching,we need to find several segments as candidate objects for trajectory points,which are likely to be the actual path where the trajectory points are located.Typically,we set the search radius centred on the current trajectory point and search candidate segment within circular regions.Thereddotis the trajectory point,and the circle is the search area.Trajectory segments searched by trajectory points includer1,r2,r3andr4.Correspondingly,thegreendotis the matching point of the candidate segments,also known as the candidate matching point.
2.2 |Related work
Intuitively,when the vehicle is driving on the road,a complete trajectory should be correctly displayed on the road.However,due to the errors caused by satellite positioning systems,there are deviations between vehicle trajectory and roads.The map matching problem has been extensively studied in recent 2 decades,but there are few surveys of map-matching techniques,and most of existing work focused on designing map-matching algorithms.
From a methodological perspective,Quddus et al.[31]gave a review of map-matching approaches,including geometric analysis,topological analysis and probabilistic mapmatching and advanced map-matching algorithms.Geometric analysis utilizes the distance relationship between trajectory points and roads for map matching.Topological analysis focuses on the connectivity of trajectories and adjacency road.The probability-based map-matching algorithm uses different mathematical models to find a trajectory with the maximum probability approximating to the realpath.The advanced mapmatching algorithm can reduce positioning errors from multiple aspects,including Kalman filter,fuzzy logic,multiple hypothesis technique and so on.Based on the classification method proposed in[31],Hashemi et al.[32]classified the real-time map-matching algorithms.A variety of different matching algorithms are compared and analyzed.In addition,the disadvantages of weight-based and advanced map-matching algorithms are also compared and analyzed.Song[33]introduced a more comprehensive classification method of map-matching algorithms,which is categorized according to information,application environment and sampling frequencies.Different from previous classification methods,Chao et al.[34]proposed an innovative classification method based on matching models and real scenarios.Similarity measurements,state-transition,candidate-evolving and scoring model are proposed in the study.The similarity model contains two types,that is,distance based and pattern based,corresponding to the distance of the points or trajectory segments projected to the nearest road.Based on the weighted topological graph of all possible vehicle driving routes,the main task of the state-transition modelis to find an optimal path,such as hidden Markov model,conditionalrandom field and weighted graph technique.The candidate-evolving model needs to maintain a set of candidates in the phase of map matching,and evolves from the first point by constantly adding new candidates while pruning irrelevant ones.The particle filter and multiple hypothesis techniques are the most classical methods.The scoring model first needs to partition road into grids,scores the grids according to the timestamp and returns the maximum score of the grid results.Taking into consideration the noise characteristics of trajectory data,Gao et al.[35]introduced the trajectory data preprocessing methods including data cleaning,trajectory compression,trajectory segment and map matching.Noise filtering and stay point detection methods can effectively remove outliers in the phase of data cleaning.However,in order to reduce storage capacity and improve the efficiency of calculation,both distance-based and offline compression methods can work well in trajectory compression.Trajectory segmentation is beneficial for reducing the computational complexity,which is commonly used in three strategies based on time threshold,geometric topology and trajectory semantics.In the phase of map matching,the processed trajectory data and electronic map are combined to transform the sampling sequences of GPS coordinates into the road network coordinates.Real-time online matching and offline matching for historical static data are two most popular approaches.
Although map-matching problem has been studied for many years,many survey studies have deficiencies in some aspect.For example,many researchers regard map matching as map-matching algorithms problem,ignoring the data preprocessing process.Data preprocessing is the initial phase of map matching and should be explored in detail.In addition,the classification of existing map-matching algorithms is not state-of-the-art,so it is necessary to propose a new classification method.These studies in[31–33]just focus on different classification of map-matching algorithms,but it is not a comprehensive study of map matching.In addition,open source GPS sampling data sets and the evaluation measurements are rarely mentioned in the map-matching surveys.Although open source GPS sampling data sets and the evaluation measurements are not the main research contents of the study,we believe that the map-matching surveys should provide more relevant information to facilitate reader’s understanding.In[34,35],it should provide more detailed information.Different from the existing work,we first make a comprehensive summary of data preprocessing,including FCD preprocessing and road data preprocessing.Then,we propose a new classification method for map matching.Finally,open source GPS sampling data sets and the evaluation measurements.In conclusion,we summarize the map-matching problem as comprehensively as possible.
In this section,we first give the necessary definition of map-matching techniques.Then,after a comprehensive review of the existing work,we propose a new classification method for map-matching techniques.
3|SURVEY OF DATA PREPROCESSING
3.1|FCD preprocessing
3.1.1 |Noise filtering
The results obtained by using the original FCD with noise directly in experiments are often not ideal.In the process of data acquisition,due to the frequency of acquisition equipment or acquisition rules,it is inevitable to produce records that are regarded as noise data,such as redundant,abnormal and incomplete records.Here,we will give the following introduction to the noise data filtering approaches as shown in Table 1.
Filteringredundance.When the speed is slow or the vehicle stops,the trajectory points may overlap and the redundant data will generate.Yan et al.[36]combined the speed and distance between adjacent points to determine whether there are redundant points.If the adjacent point distance does not exceed the threshold and the speed is less than 3 m/s,the current trajectory point is ignored.Huo et al.[37]thought that the probability of GPS producing the same record in a short time is very small,so the same record is deleted within a fixed time interval.Hui et al.[38]assumed that no more than 50 m of vehicle position change within 30 min was a parking behaviour and deleted redundant sampling points with the same timestamp.GPS records may have data with the same time and different speeds,so only a set of data needs to be retained in these studies[39,40].
Removalofabnormality.When an extreme situation occurs,the data willbe abnormally generated.For example,if the visible satellite is less than 4 or the vehicle is more than 200 km/h,they are considered as abnormal data and be removed in[41].In the study[36],FCD beyonds the limitation of longitude and latitude is regarded as abnormal data and should be removed,which can only appear within the fixed area of the electronic map,because there are more stringent speed limitations for urban roads,generally 40 km/h.It is only necessary to determine the two coordinates of lower left corner and top right-hand corner which are viewed as the latitude and longitude limitations of the electronic map.Liu et al.[40]believed that the travel time conformed to a lognormal distribution and used the Laida criterion to clean outliers.Wen et al.[39]deleted data with a speed of 0 because they could not reflect the driving behaviour.Wang et al.[42]filtered data with negative speed and replaced it with zero for subsequent adaptive tracking of vehicles.
Removingincompletedata.Ye et al.[43]considered that any records containing missing values should be removed,and only use the complete records.When the attribute variable of one column of the data has a missing value,the entire column attribute is deleted.Although attribute deletion can impact the integrity of the data sets,this method is very effective when the amount of data deleted in the whole data sets is very small.From the viewpoint of coordinates,Dong et al.[44]removed the data with latitude and longitude with value zero.The missing records are deleted in these studies[45,46]because they lack valid information and are ineffective.
3.1.2 |Machining data
Different machining methods can be selected for raw data according to the actual situation so that the map-matching algorithms can obtain a positive result.Note that not all machining methods can be applied in the real data.It is a good way to choose the machining method according to the structure of the data.As shown in Table 2,we summarize some rules of machining data.
Coordinatetransformation:In order to reduce the conversion error of latitude and longitude data received by GPS navigation systems in the phase of transformation in electronic map,based on the seven-parameter transformation model,Tan et al.[47]analyzed the effects of the distribution of different public point positions on the transformation accuracy to establish the relationship between the distribution density of data and the transformation accuracy.The key of coordinate transformation is to solve the transformation parameters and transform them into the coordinate parameters of the corresponding region.Zhang et al.[48]believed that there are positioning errors in different coordinate projection systems.They transformed GPS WG184 coordinate system into Beijing 50 or Xi’an 80 coordinate system using the transformation of spatial coordinate systems.Li et al.[49]first transformed WGS-84 spatial coordinates into BJ-54 spatial coordinates,and finally determined the plane coordinates by Gaussian projection.Zhang et al.[50]believed that there would be errors in converting GPS measurement results to BJ-54 or Xi’an 80 coordinates,and proposed to use Gauss–Kruger projection to convert to plane coordinates.
Fillingmissingvalues:Missing value,as a factor to improve the quality of data mining,cannot be ignored.In literature[51],the five filling methods are summarized,by mainly using interpolation and filling function.Specific methods are given as follows:(a)average method:replace missing values with the average value of the entire sequences;(b)median method:use the median of a certain span range or all valid values to replace the missing values;(c)linear interpolation:the data of the previous position and the latter position of the missing value are interpolated by using a linear formula;(d)forward and backward interpolation:fill in the missing value with the previous or the latter value and(e)temporal interpolation:apply the closest value in time distance to the linear model in order to fill the missing values.Ye et al.[43]believed that the method of multiple filling has more advantages than single values filling,which aims to construct multiple estimates for each missing value and form severalcomplete data sets.The method can simulate the distribution of missing data as close as possible to the realsituation and maintain the original relationship between variables.Cai et al.[52]formulated the trajectory missing distance and time rules,and interpolated the missing trajectory points according to the missing number equal distance.Yin et al.[53]proposed a model using long short-term memory networks to solve the problem of poor effectiveness of traditional completion methods.By comparing various interpolation methods,Wang et al.[54]found that regularized algorithm has better interpolation effect.
Reconstructiontrajectories:When the acquisition time intervalis longer or the signalshielding occurs,the phenomenon of discontinuity will occur in the trajectory points.In order to improve the unity and standard of the trajectory data,and at the same time to obtain the complete motion trajectory of the vehicle by using the limited trajectory data,Sheng et al.[55]designed an improved Hermite interpolation algorithm to perform temporal interpolation on the trajectory points after modifying the errors.The key task of this method is to use polynomial function to restore the trajectories and add restrictions on the vehicle speed and driving distance.Zeng et al.[41]compensated the data using dead reckoning method,which uses the latitude,longitude,velocity,angle and positioning time intervalof the previous point to calculate the position of the next point.Zhao et al.[56]considered that the error between measurement points has an effect on the reconstructed trajectory,and combined the 3σcriterion with the inverse distance weighted interpolation method to generate a new trajectory.Shiet al.[57]used Lagrangian fifth and third polynomialinterpolation to estimate the trajectory points,and then used Kalman filter algorithm to remove the noise of the trajectory.Wang et al.[58]first calculated the statistical information of driving mode with probability distribution,then used maximum likelihood estimation to reconstruct the trajectory.
Trajectorysegmentation:By dividing the trajectory into several segments,the data can be displayed in detail and clearly,which are especially beneficial for the heuristic matching algorithms.Zhang et al.[28]made the rule that the trajectory does not intersect and the distance of the trajectory is greater than the threshold,and partition the trajectory into multiple segments without loops.According to the speed variables,Yang et al.[59]divided the long-time sequence trajectory into three states:high speed,medium speed and low speed.The partitioned trajectory segments need to be used to find homomorphic trajectory and merge into subtrajectories.In addition,partitioning methods based on time threshold,geometric topology and trajectory semantic strategies are also mentioned[35].Zhang et al.[60]used classification and regression tree to segment the original trajectory while calculating the synchronized Euclidean distance(SED)between adjacent trajectory points.Finally,the subtrajectories are merged and simplified by SED.Zhang et al.[61]calculated the change of velocity and direction of adjacent points.When the threshold is exceeded,the trajectory is segmented.
Geometricinformationindexing:Finding a trajectory directly on an electronic map is difficult.Geographic location information is a tuple containing longitude and latitude that can be converted into other expressions for localization.Kang et al.[62]used the Geohash technique to encode the longitude and latitude of the trajectory points in order to find the candidate segments.This method can only be used to search the nearby nine mesh information so that greatly reduces the time complexity.Gao et al.[35]introduced the index structure such as R-tree,B-tree and K-D tree.In addition,some researchers proposed to use the method of griding to index the trajectory data[63,64].Hong et al.[65]used MapInfo software to establish a spatial index search based on a single-layer grid,using two staggered partition mesh division methods.
Dataarrangement:Sorting data is necessary because processed data can sometimes appear complex.There is only one popular way to sort the trajectory data,that is,to arrange the data according to the time stamps.The study[48,66,67]sorted the data in the ascending order according to the sampling time,where the trajectory of each vehicle is from the departure to the destination.Nevertheless,Zhong et al.[68]sort the trajectory points according to the principle of nearest neighbour distance to form the trajectory with sequence.
3.2 |Road data preprocessing
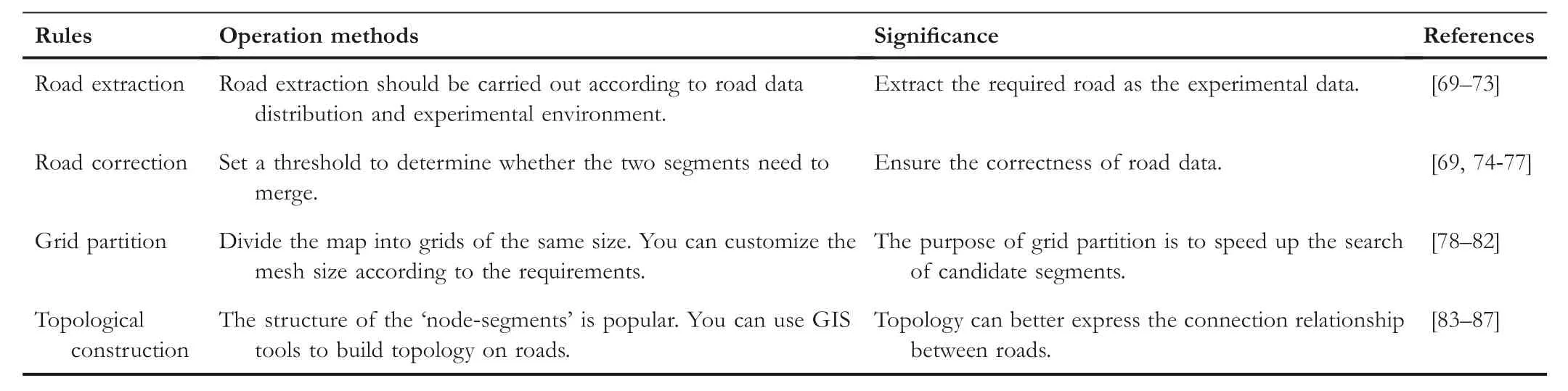
Road data are necessary for map matching because the trajectory points are ultimately to be displayed on an electronic map containing road data.Most electronic maps consist of road data,such as‘Baidu Map’,‘Google Map’and so on.Inevitably,road data also appear missing and wrong,due to slow road renewal and staff mapping errors.For FCD,road data also need to be preprocessed.As shown in Table 3,we summarize the methods of road data processing.
Roadextraction:The goalis to extract the required path.Luo et al.[69]thought that the path planning algorithm needs to work in a network of road connectivity,and combined high-rise and low-rise networks to ensure connectivity including national highway,provincial road,county road,highway and so on.Zhang et al.[70]used the regular expressions to quickly match the node information of road files to obtain the road networks.If the road contains multiple segments,each segment is treated as an object.Yu et al.[71]aimed to explore common road network models and constructed five simplified road network models,such as rectangle and tree branch.Huang et al.[72]extracted road data such as highway and ramp,and carried out operations such as data duplication,data integration and data segmentation.Zhang et al.[73]classified OpenStreetMap data through tags,and then used regular expressions to match node information to obtain multiple road objects.
Roadcorrection:Before constructing the topological graph of road data,we need to check whether the road data are correct.The work done in[69]has focused on repairing road separation.After setting the distance threshold,when the distance between the two end points of the separated segments is less than the distance threshold,the road is merged.Considering the disadvantages of map information in electronic maps,Sun et al.[74]proposed a buffer analysis method to repair the road data by specifying the distance threshold.Instead of changing the raw road data,they added supplementary information to the property tables to generate new layers.In order to meet the needs of traffic management business,Wang et al.[75]simplified the original road data.They perform multilane fragment removal,off-ramp removal on highways and multilane merging.Zeng et al.[76]deleted the pseudo nodes and separate arcs of the road data in order to obtain a connected road network.Deng et al.[77]believed that the traditionalmethod of extracting road intersections was not fine enough,and proposed a trajectory point clustering method to extract road intersections.This method uses local spatial autocorrelation analysis to detect trajectory steering angle hotspots,and uses adaptive spatial point clustering to cluster hotspots and identify the location of intersections.
Gridpartition.Grid division focuses on equivalent block segmentation of maps.Fan et al.[78]partitioned the longitude and latitude of the map equally with 0.002 degree as the unit.Wang et al.[79]used the tree structure to divide the map step by step untilit can no longer partition the grids.Liet al.[80]proposed to quickly and accurately locate the candidate road segments.They divided the road data into grid areas of the same size to build a grid index,using the ID number of grids to quickly identify all segments of the grids.Zhao et al.[81]proposed an adaptive basic grid division algorithm,which can effectively solve the problem of road search errors in equidistant grid division.Liu et al.[82]proposed to use multiprocess technology to cut the original raster image to improve the speed of map division.
Topologicalconstruction.Topologicalconstruction aims to establish the expression relationship between roads.In[83,84],they interrupted the road at the intersection point and divided the road into several small segments through the SuperMap GIS platform.In[85],road data can be partitioned by segments intersection into‘node-segments’,and the topology is constructed by using the breadth-first traversal method.The work was done by Chen et al.[86],which proposed the dual structure of data storage layer as well as dynamic topological layer,and they mentioned that the topologicalrelation of object space is dynamically changing.For expressing the relationship between segments and nodes,Liet al.[87]first recorded segments and nodes separately with tables,and then merged nodes with the same ID to construct road topology.
In this section,we first classify FCD preprocessing rules and introduce each processing rule in detail.Then,we summarize the rules of road data preprocessing.
4|SURVEY OF SELECTION ALGORITHMS
As the map-matching techniques grow rapidly,algorithms based on geometric principle,topologicalstructure,probability and machine learning are applied to map matching,which is also the key technique of map-matching techniques[88–91].In this section,we classify map-matching algorithms with sampling frequency and data information.In addition,the open source GPS sampling data sets and evaluation measurements are given below.
4.1|Classification of map-matching algorithms based on sampling frequency

F I GURE 6 Statistics of sampling frequency of GPS data

TA B LE 4 Classification of sampling frequency
In general,vehicles with GPS positioning devices record GPS information at a certain frequency.By considering energy consumption and communication cost,GPS information is continuously recorded at a lower frequency.As shown in Figure 6,Yuan et al.[92]counted the data generated by more than 10,000 taxis in Beijing for a week.By statistics,the data of sampling frequency within 1 min occupy 34%of the whole data,and it is regarded as high-frequency sampling data.Moreover,sampling frequency more than 1 min is considered to be low-frequency sampling data with a proportion of 66%.As described in Table 4,Gao et al.[93]viewed the sampling data between 1 s and 10 s as high-frequency sampling data,more than 30 s as low-frequency sampling data,and more than 2 min as ultra-low-frequency sampling data.
4.1.1 |High-frequency sampling data-based algorithm
High-frequency sampling data has the characteristics of dense points,small change of heading angle and smooth curve,which can be fully utilized to improve the accuracy of map matching.Based on the topological relationship and connectivity of the road network,Zeng et al.[94]played the advantage of dense trajectory points and used the shortest path search algorithm to obtain candidate road segments because taxi drivers preferred the shortest route.The more dense the trajectory points,the less candidate sections are searched by the trajectory points,and the higher the map-matching accuracy is.Chen et al.[95]used the relationship between the heading angle of the adjacent trajectory points and the candidate segments to find the road junction.If the angle is greater than 45 degrees,it is regarded as the road junction.Because the variation of heading angle ofhigh-frequency sampling data is small,the intersection can be found accurately in the experiment,but the performance effect is poor in the low-frequency sampling data.Liu et al.[96]proposed two different matching algorithms for the map with road segments.When considering the road complexity,the trajectory points are input into the algorithm modelto get the results and feedback back to the model.Otherwise,the prediction results are obtained directly by fitting the formula.Both methods effectively solve the map matching ofYzigzag road.Since essentially considering the smoothness of the trajectory curve,high-frequency sampling data is required.Zhang et al.[97]concentrated on using weighted formulas for angle,distance and slope.If the ultra-low sampling frequency is used,there will be a‘zigzag’phenomenon.

TABL E 5 Classification of map-matching algorithms by sampling frequency
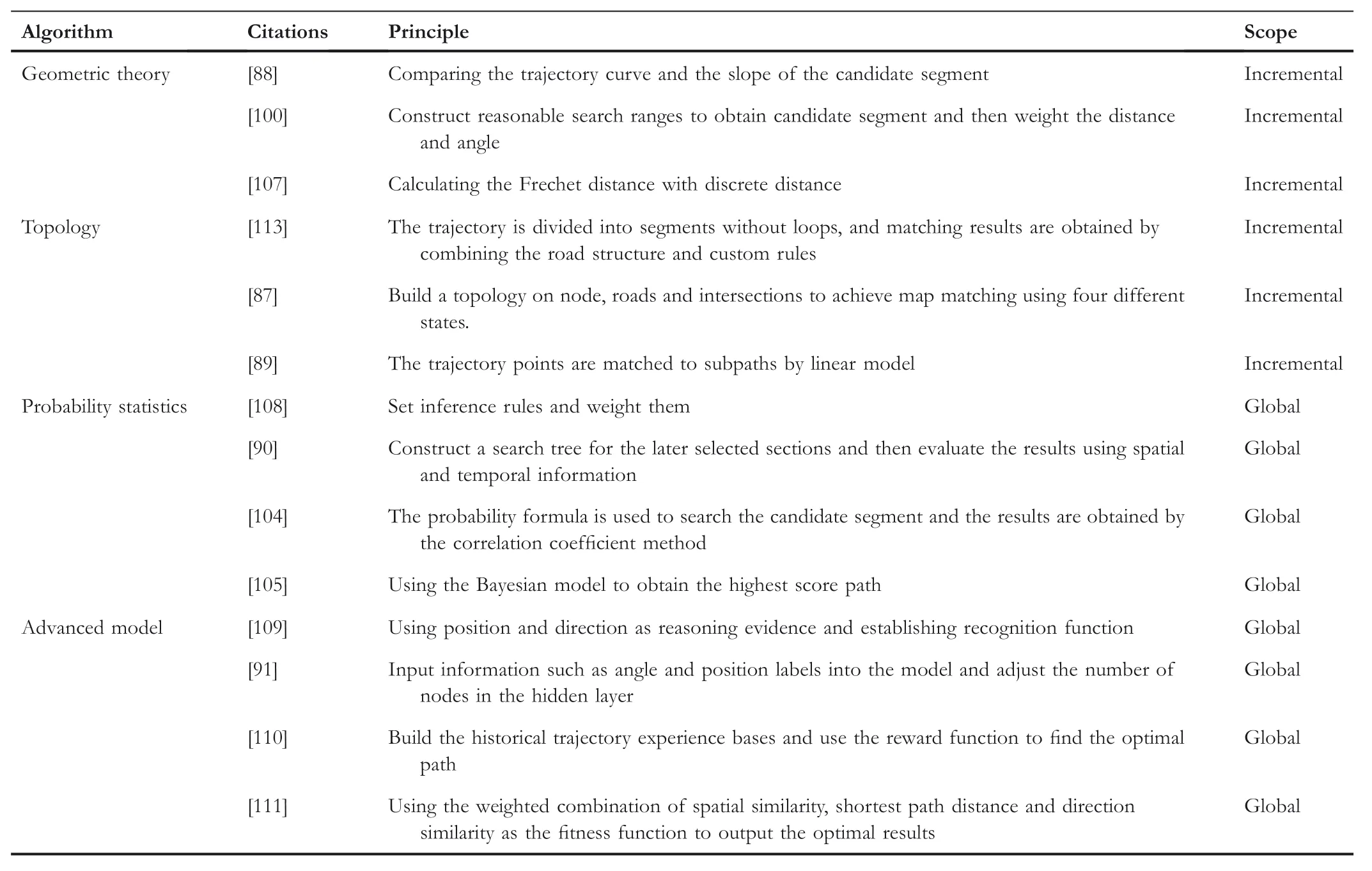
TABL E 6 Classification of the map-matching algorithms by data information
4.1.2 |Low-frequency sampling data-based algorithm
Low-frequency sampling data has the disadvantages of point sparsity and large curve fluctuation,so map-matching algorithms generally focus on incremental,globalor other aspects.Sheng et al.[55]found that the accuracy of the topology searching method decreases with the sampling time interval.They improved the Hermite interpolation method and used the singlezero and multi-zero-segment linear interpolation to obtain the matching results from the aspect of restoring the vehicle route.The concept of reliable points for screening candidate segments is proposed in[98].By comparing the ratio of the top two candidate road segments of the transmitting probability row,the remaining candidate road segments are removed when the ratio is greater than an empirical value,thus reducing the calculation of the transition probability.In addition,A*algorithm and the sliding window are used for real-time matching.Research was done by Lou et al.[99],which proposed spatiotemporal(ST)matching algorithm that considers the spatio and temporal factors.The spatial analysis function takes into account the distance from the trajectory point to the road segments and the adjacent candidate matching points,while time analysis function combines the factors of road segments length and constraint speed.The product of the two functions is taken as the score of the candidate segments,and the segment with the highest score is taken as the matching result.Based on the work in[99],Yuan et al.[92]adopted the interactive voting approach.The candidate matching points need to vote with each other to eliminate the phenomenon of matching errors in adjacent segments.When compared with the ST-matching algorithm,the proposed algorithm is more robust.As shown in Table 5,we summarize the different characteristics of high-frequency and low-frequency sampling data.Although there are many kinds of algorithms,sampling data have similarities,so we summarize the algorithms classification from the point of view of data characteristics and advantage.
4.2 |Classification of map-matching algorithms based on data information
As shown in Table 6,according to the data information contained in the data sets,the map-matching algorithms can be categorized into four types:geometric principle[88,100,101],topology[28,89,102,103],probability statistics[90,104–106]and advanced model[91,107–112].These algorithms can be regarded as incremental and global method according to the number of sampling points in map matching.The incremental method first determines the previous point and then predicts the next point,while the global method takes into account the characteristics of the whole trajectory to determine the output results.
4.2.1 |Geometric principle
In general,the relationship between point-line and line-line is analyzed in the map-matching algorithms based on geometric principle,using distance,similarity and other factors to find the optimal path.In[88],by comparing the trajectory curve and the slope of the candidate segment,the least square method is used to fit the adjacent four trajectory points to the candidate segment.To improve the accuracy of real-time matching for navigation system,Teng et al.[100]proposed a new algorithm integrating ST proximity and improved weighted circle.The product of vehicle speed and traveltime is used as the search radius.The elliptical region is constructed with the adjacent trajectory point as the centre,and the road in the intersecting region is the candidate segment.Because of the dynamic changing speed of vehicles,the search region also changes with the speed.“Then,in combination with the established rules,the distance from the trajectory point to candidate segment,the angle between the driving direction and candidate segment can be determined.”Zheng et al.[107]calculated the Frechet distance with discrete distance,which can determine the relationship between the trajectory curve and the road curve.Viewing distance as a factor,uncertainty inference is used in cloud model to obtain the matching similarity of road segments.
4.2.2 |Topology
The topology-matching algorithm needs to build the road network and combines the local search algorithm to find the optimal path.Zhang et al.[113]split the trajectory into segments without loops and used the stack-stored road topology to find candidate segment.Then,a custom rule is used to filter the candidate segment to obtain the matching results.Li et al.[87]took nodes,roads and intersections as objects to establish the spatial topological relationship between points and lines.They divided the matching process into four different states and implemented the corresponding matching algorithm according to each state.In[89],sensors are used to receive road network data for nearby vehicles.After using the map data of multiple vehicles to obtain the subpath,the matching position is figured out by the linear model.Because of the simulation in the ideal environment,the delay and GPS accuracy of the sensor will affect the algorithm.
4.2.3 |Probability statistics
Probability statistics algorithm is designed to find a matching path with the maximum probability.Tuo et al.[90]used candidate segment to construct map search trees,which have multiple branch paths from root to end and cannot be traced back.Then,considering the spatial and temporal information of trajectory,they evaluated each branch in the map-searching tree.Li et al.[104]proposed a probability formula to establish an elliptical region search candidate segment.According to the characteristics of roads,the correlation coefficient method is used to select the candidate segment.The deviation of the matching points is also rectified on the road segments with the largest coefficient.Cheng et al.[105]thought that there is a probability relationship between the vehicle heading angle of the trajectory point and the road segment.By applying Bayesian theorem,they designed mathematical models to obtain the highest score of candidate segment as matching results.Yao et al.[108]used the membership function to perform fuzzification of three input variables of average error,projection distance and velocity to obtain the fuzzy subset,and designed inference rules for average angle and speed.They weighted the inference results in order to obtain the highest score as the matching path.

TABL E 7 GPS sampling data

TA B L E 7 (Continued)
4.2.4 |Advanced model
Advanced model is relatively novel,including fuzzy logic methods,D-S evidence theory,support vector machine multiclassification matching,neural network,reinforcement learning,genetic algorithms and so on.Bi et al.[109]took the vehicle position and the direction information as the reliability parameters of the reasoning evidence,proposed two identification functions for each candidate segment,then took the maximum value of the function as the matching result.Wang et al.[91]used LIBSVM to establish multiclassification models for processed road network data and GPS sampling data.The map matching is transformed from the real position prediction problem to the multiclassification problem,in which the road network data contains labelinformation such as road segment angle and position.These labeldata need to be input into the extreme learning machine algorithm,and then adjust the number of hidden layer nodes to get the output results.Sun et al.[110]proposed History Markov decision ProcessesQ-Learning algorithm based on reinforcement learning and historicaltrajectory,which include searching for candidate point set,selection of candidate path set and solution of optimal path.First of all,the candidate point set is formed by projecting to the corresponding candidate segment according to the position of the trajectory point.Then,if there is a historical track between the adjacent candidate matching points,the historicaltrack is taken as the candidate segment.Otherwise,the shortest path of adjacent candidate points is used as the candidate path.Finally,distance,historical trajectory weight and connectivity are taken as reward functions to solve the optimal path using reinforcement learning.Gu et al.[111]proposed a map-matching method based on multicriteria genetic algorithm.They used the weighted combination of spatialsimilarity,shortest path distance and direction similarity as the fitness function of the genetic algorithm,and iteratively minimized the objective function to output the optimalresults.
4.3 |Introduction of open source GPS sampling data sets
In this section,we introduce some open source trajectory data sets,including related descriptions,download addresses and registration requirements,as shown in Table 7.We have carried out download test for these data sets.The result is that they are allusable.
4.4 |Evaluation measurements
To estimate the system performance of the map-matching algorithms,experimental measurements are used to verify the advantages and disadvantages of the map-matching algorithms.Commonly used map-matching measurements include accuracy and time efficiency.The accuracy(e.g.correct matching percentage[CMP])is the ratio of the number of roads correctly matched to the total number.Time efficiency(TE)is the time spent from beginning matching to outputting all matched points.
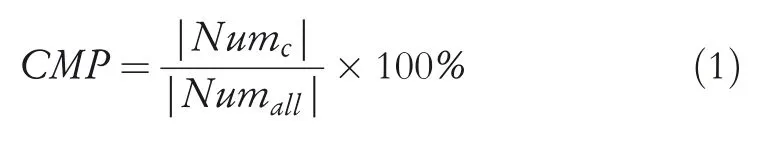
whereNumcis the number of correctly matched points andNumallis the totalnumber of points needed to be matched.

whereTorepresents the time of application ends,andTsis application start-up time.
Map-matching algorithms generally need to be measured by CMP and TE measurements.In addition,some researchers also use Recall,LenCMP and Circuity to measure the performance of map-matching algorithms.
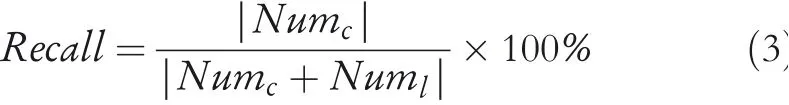
whereNumlis the number of missing matching.
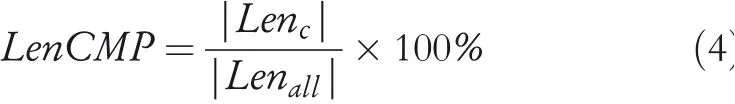
whereLencis the length of the CMP andLenallis the path length of the actual driving of the vehicle.
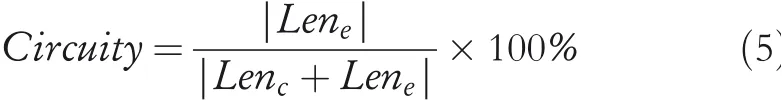
whereLenerepresents the length of mismatching path.
It is worth noting that the selection of algorithmic measurements depends on whether the matching object is a trajectory point or a path length.CMP and Recall are recommended if trajectory points are selected as the study object.Otherwise,LenCMP and Circuity are often used in trajectory path measurement.No matter which one your research object is,TE always appears in the experiment as a basic metric.
In this section,we first partition map matching into sampling frequency and data information-based approaches and then introduce the open source trajectory data sets and evaluation measurements.
5|DISCUSSIONS AND CONCLUSION
We conduct a comprehensive survey of the map-matching problem,which includes data preprocessing and selection algorithms.We first point out the shortcomings of the previous study,and then propose a new classification method for the existing measurements.In addition,we introduce the open source data sets and evaluation measurements.Finally,we present new challenges to map-matching techniques.In conclusion,this study summarizes the current trend of mapmatching techniques and provides guidance for future research directions.
Map-matching technique is the basis of trajectory mining.With the development of the Internet,map-matching techniques,including data preprocessing and matching algorithms,also have new challenges.In order to further study the vehicle map-matching techniques,the following aspects can be studied in the future.
5.1|Challenge of data preprocessing
(i)Incomplete FCD is the most common problem in data preprocessing,which will increase the difficulty of map matching.Most researchers prefer to use vehicle speed and heading angle variables for map matching,but the deletion method and adjacent value filling are inappropriate.We can analyze the overall trajectory curve and insert the missing value.If the amount of data is large enough,we can train the modelwith historical data,which can be used to predict the missing value.FCD with more attributes should be further explored,which is applied to map-matching algorithms in order to improve the accuracy of map matching,for example,vehicle slope,altitude and other factors;(ii)Currently,the road network structure appears mostly in the form of point line,which willinevitably lose the integrity of the road.In the three-dimensional road,high speed and other complex road,the lack of road integrity will increase the error of matching.When building a road network structure,we can add additional space to store complete roads.In addition,due to the time lag of open road data,we can cluster the massive floating vehicle data in order to restore the missing road.
5.2 |Challenge of map-matching algorithms
Although most map-matching algorithms are based on highfrequency sampling data,map-matching algorithms based on low-frequency sampling data have attracted a lot of attentions in recent years.We can focus on the following directions:(i)Due to sparsity of low-frequency data,most studies are based on hidden Markov probability or advanced model,and there is rare work on geometric principles and topologicalstructures.We can apply the algorithms based on geometric principle and topology by combining more attributes of low-frequency sampling FCD and road data;(ii)When searching candidate segment,grid search is more popular because it works fast.When candidate segments appear in extreme positions,most people choose to continue searching for eight nearby grids to avoid missing candidate segments,but it also increases the computational overhead.It is reasonable to construct a circular region with the product of vehicle speed and driving time as radius to choose the search results of nine grids to reduce the computational overhead;(iii)The increasingly mature distributed computing platform can efficiently support large-scale data analysis and modelling problems.We can use cluster computing capabilities to improve the efficiency of map matching.
ACKNOWLEDGEMENTS
This work is partially supported by the National Natural Science Foundation of China(Grant Nos.61772091,61802035,61962006,71701026,U1802271,U2001212,62072311),the Sichuan Science and Technology Program (Grant Nos.2021JDJQ0021,2018JY0448,2019YFG0106,2019YFS0067,2020YJ0481,2020YFS0466,2020YJ0430,2020JDR0164,2020YFG0153,20YYJC2785),CCF-Huawei Database System Innovation Research Plan (Grant No. CCF-HuaweiDBIR2020004A),the Natural Science Foundation of Guangxi(Grant No.2018GXNSFDA138005),a Project Supported by SiChuan Landscape and Recreation Research Center(Grant no.JGYQ2018010),the Innovative Research Team Construction Plan in Universities of Sichuan Province(Grant No.18TD0027),Guangdong Province Key Laboratory of Popular High Performance Computers (Grant No.2017B030314073),the Key R&D Program of Guangdong province(Grant No.2018B030325002).
ORCID
ShaojieQiaohttps://orcid.org/0000-0002-4703-780X
 CAAI Transactions on Intelligence Technology2021年1期
CAAI Transactions on Intelligence Technology2021年1期
- CAAI Transactions on Intelligence Technology的其它文章
- Design and voice-based control of a nasal endoscopic surgical robot
- CHFS:Complex hesitant fuzzy sets-their applications to decision making with different and innovative distance measures
- Deep learning-based action recognition with 3D skeleton:A survey
- TWE-WSD:An effective topical word embedding based word sense disambiguation
- A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification
- A survey on adversarial attacks and defences