
函數(shù)型空間自回歸模型的貝葉斯估計
2022-09-29 06:53:24徐登可田瑞琴
高校應(yīng)用數(shù)學(xué)學(xué)報A輯 2022年3期
徐登可,田瑞琴
(1.杭州電子科技大學(xué)經(jīng)濟學(xué)院,浙江杭州 310018;2.杭州師范大學(xué)數(shù)學(xué)學(xué)院,浙江杭州 311121)
§1 引言
在當今大數(shù)據(jù)時代,隨著信息化技術(shù)的飛速發(fā)展,收集數(shù)據(jù)和儲存數(shù)據(jù)的技術(shù)得到了快速的提高;并且隨著使用工具越來越先進,人們收集到的數(shù)據(jù)也越來越復(fù)雜.在計量經(jīng)濟學(xué),氣象學(xué),醫(yī)學(xué)等方面,常常會獲得帶有明顯函數(shù)特性的數(shù)據(jù),即觀測數(shù)據(jù)是在空間或時間上的一個或多個維度上獲得的,這一類型的數(shù)據(jù)稱之為函數(shù)型數(shù)據(jù).函數(shù)型數(shù)據(jù)分析已經(jīng)成為統(tǒng)計學(xué)家研究的熱點領(lǐng)域之一.目前有很多專家對函數(shù)型數(shù)據(jù)模型進行了參數(shù)估計,變量選擇,模型檢驗等比較系統(tǒng)的研究.例如,基于函數(shù)型主成分分析,Hall和Horowitz(2007)[1]提出了具有標量響應(yīng)變量和函數(shù)型解釋變量的函數(shù)型線性回歸模型的最小二乘方法,并且證明了獲得的估計量具有非參數(shù)的最優(yōu)收斂速度.Shin(2009)[2]提出了部分函數(shù)型線性回歸模型,并研究了模型中未知回歸系數(shù)的理論性質(zhì).Feng等(2021)[3]研究了函數(shù)型單指標變系數(shù)模型的參數(shù)估計,并且在一定的正則條件下建立了獲得估計量的良好理論性質(zhì).Zhou和Peng(2020)[4]研究了缺失數(shù)據(jù)下部分函數(shù)型線性回歸模型的參數(shù)估計.Hu 等(2020)[5]研究了偏正態(tài)數(shù)據(jù)下函數(shù)型線性回歸模型的異方差檢驗和參數(shù)估計問題.Shi等(2021)[6]研究了函數(shù)型分位數(shù)回歸模型的模型檢驗問題.另外,有關(guān)函數(shù)型數(shù)據(jù)分析的其它研究內(nèi)容還可以參見文獻[7-9].在以上這些文獻研究中,函數(shù)型數(shù)據(jù)分析的響應(yīng)變量是一個獨立變量,不是一個具有空間相關(guān)的響應(yīng)變量.然而在實際應(yīng)用中會發(fā)現(xiàn),在函數(shù)型數(shù)據(jù)建模分析時不僅會存在函數(shù)型解釋變量,有時還會同時出現(xiàn)具有空間相依關(guān)系的響應(yīng)變量的情形.
目前研究具有空間相依關(guān)系的最主要模型是空間自回歸模型.空間自回歸模型廣泛應(yīng)用于經(jīng)濟學(xué),環(huán)境科學(xué)以及地理信息等領(lǐng)域,且得到了大量的統(tǒng)計學(xué)家和計量經(jīng)濟學(xué)家進行深入的研究.例如,Liu等(2018)[10]基于懲罰擬極大似然估計方法研究了空間自回歸模型的變量選擇問題.Jin和Lee(2019)[11]考慮了空間自回歸模型的廣義經(jīng)驗似然估計和檢驗問題.王周偉等(2019)[12]基于Spatial AIC準則研究空間自回歸模型的變量選擇.Xie等(2020)[13]研究了發(fā)散維時空間自回歸模型的變量選擇,并證明了變量選擇方法具有相合性和Oracle性質(zhì).Cheng和Chen(2021)[14]提出了部分線性單指標空間自回歸模型并且針對模型研究了截面極大似然估計問題.Hu 等(2020)[15]基于函數(shù)型主成分分析研究了函數(shù)型空間自回歸模型的估計,并建立了參數(shù)部分和函數(shù)系數(shù)部分估計的理論性質(zhì).
另外近年來由于計算機的快速發(fā)展,貝葉斯統(tǒng)計發(fā)展非常迅速,取得了非常豐碩的研究成果.例如,Li等(2014)[16]研究了基于似然比檢驗統(tǒng)計量的貝葉斯版本假設(shè)檢驗.Tang等(2018)[17]基于P樣條對線性混合效應(yīng)變換模型進行貝葉斯估計和貝葉斯局部影響分析.Tian和Song(2020)[18]基于貝葉斯橋懲罰分位數(shù)回歸研究了模型的貝葉斯變量選擇問題.田瑞琴等(2021)[19]研究了縱向數(shù)據(jù)下半?yún)?shù)均值方差模型的貝葉斯分析.Zhang等(2021)[20]基于分位數(shù)回歸研究了半?yún)?shù)混合效應(yīng)雙重回歸模型的貝葉斯估計問題.但是有關(guān)部分函數(shù)型空間自回歸模型的貝葉斯統(tǒng)計推斷成果卻幾乎沒有.因此本文主要基于函數(shù)型主成分分析,應(yīng)用聯(lián)合Gibbs抽樣和Metropolis-Hastings算法相結(jié)合的混合算法來研究函數(shù)型空間自回歸模型的貝葉斯估計.
本文結(jié)構(gòu)安排如下:§2介紹函數(shù)型空間自回歸模型,函數(shù)型主成分分析以及給出基于模型得到的似然函數(shù);§3詳細給出實現(xiàn)貝葉斯估計的先驗分布,條件分布以及算法;§4節(jié)通過大量的模擬研究說明模型與方法的可行性;§5是應(yīng)用提出的模型和貝葉斯方法對加拿大氣溫數(shù)據(jù)進行實證分析;§6是結(jié)論.
§2 模型與似然函數(shù)
2.1 函數(shù)型空間自回歸模型
考慮部分線性函數(shù)型空間自回歸模型
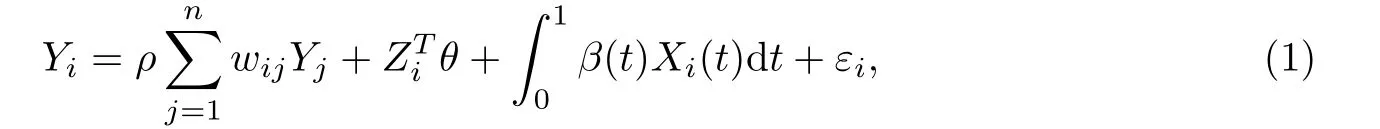
其中Yi表示第i個個體的實值響應(yīng)變量,Zi表示p維標量型解釋變量向量;Xi(t)∈L2(T)為函數(shù)型解釋變量,L2(T)表示所有定義在T上的平方可積函數(shù)構(gòu)成的希爾伯特空間,不失一般性假設(shè)T=[0,1];wij為非隨機空間權(quán)重矩陣W的第(i,j)個元素,并且滿足當i=j時,wij=0;ρ為未知的空間鄰近效應(yīng)參數(shù),θ=(θ1,θ2,···,θp)T是未知p維回歸參數(shù),β(t)是定義在[0,1]上的平方可積函數(shù);另外在這里假設(shè)εi是獨立同分布服從于均值為零,方差為σ2的正態(tài)分布,即εi~N(0,σ2).
模型(1)也可以寫成矩陣的形式,令Y=(Y1,Y2,···,Yn)T,Z=(Z1,Z2,···,Zn)T,X(t)=(X1(t),X2(t),···,Xn(t))T,ε=(ε1,ε2,···,εn)T.那么模型(1)可以重新被寫成
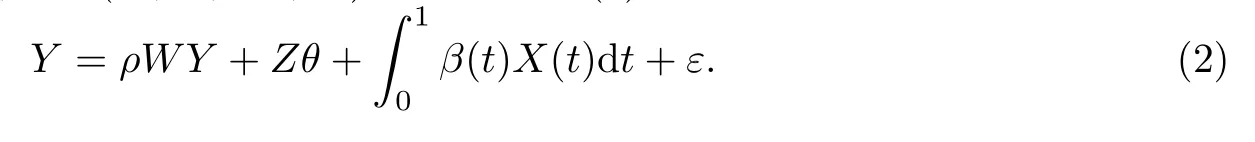
2.2 似然函數(shù)
首先,定義函數(shù)型變量X(t)的協(xié)方差函數(shù)和經(jīng)驗協(xié)方差函數(shù)分別為
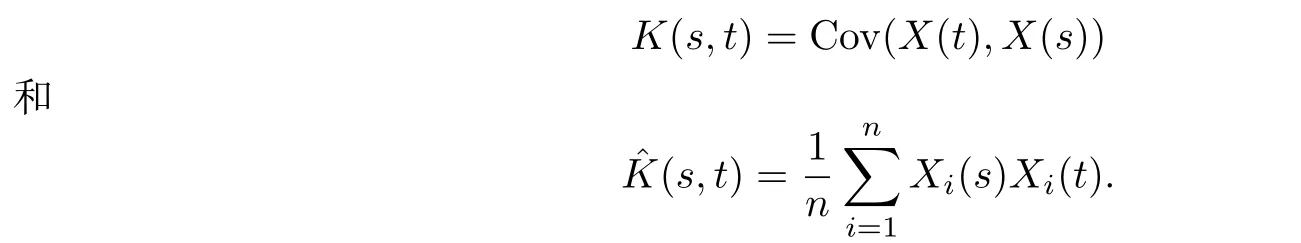
在這假設(shè)協(xié)方差函數(shù)對應(yīng)的特征根從大到小排列為λ1>λ2>··· >0,對應(yīng)的經(jīng)驗協(xié)方差函數(shù)特征根為,{φj}和分別為對應(yīng)的正交特征向量.顯然這里{φj}和為空間L2([0,1])上的標準正交基,那么利用Mercer定理可得K(s,t)和(s,t)分別有譜分解
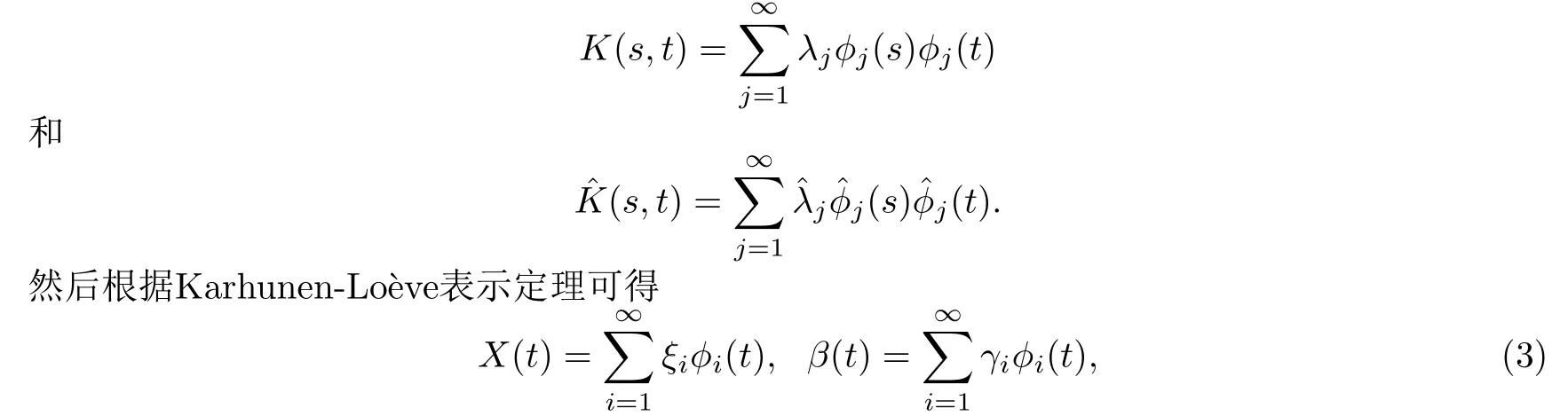
其中ξi是不相關(guān)的隨機變量,且滿足,和γi=〈β,φi〉,這里〈·,·〉表示在L2(T)內(nèi)上的內(nèi)積.因此把(3)代入模型(2)可得

其中m ≤n表示截斷參數(shù).若用近似φj,模型(5)可以被重新寫成
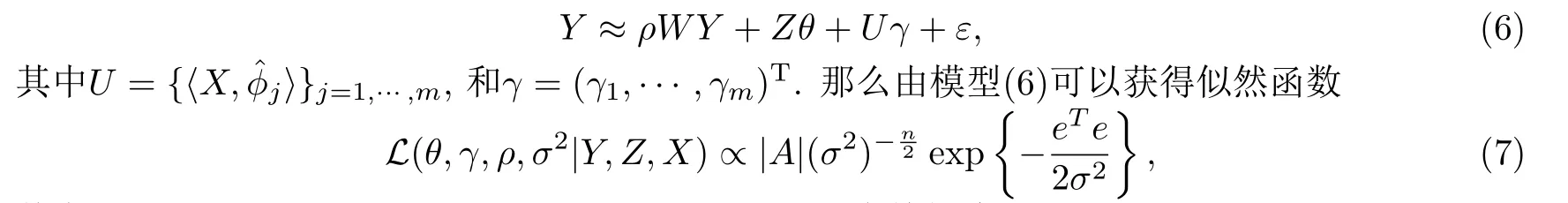
其中e=AY -Zθ-Uγ,A=In-ρW,和In是n×n維單位陣.
§3 貝葉斯估計
3.1 先驗分布
為了應(yīng)用貝葉斯方法估計模型(1)中的未知參數(shù),需要具體化未知參數(shù)的先驗分布.類似于Ju等(2018)[21],為了簡便在這假設(shè)θ和γ相互獨立且具有正態(tài)先驗分布,分別為θ~N(θ0,Σθ)和γ~N(γ0,Σγ),其中假設(shè)超參數(shù)θ0,γ0和Σθ,Σγ是已知的.另外假設(shè)ρ~U(-1,1),σ2~IG(c0,d0),其中c0和d0是已知的超參數(shù),“U(·,·)”表示均勻分布,“IG”表示逆Gamma分布.這樣未知參數(shù)的聯(lián)合先驗定義為

其中“p(·)”表示參數(shù)的先驗概率密度函數(shù).
3.2 貝葉斯后驗推斷
令Ψ=(θ,γ,ρ,σ2),在這里主要利用MCMC方法獲得未知參數(shù)Ψ的貝葉斯估計.基于似然函數(shù)(7)和聯(lián)合先驗分布(8)可以獲得參數(shù)Ψ的聯(lián)合后驗分布,具體為
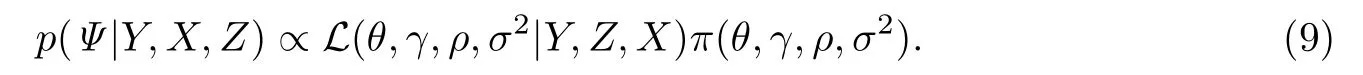
基于上式進行直接抽樣和后驗推斷是比較困難的.為了解決這個問題,首先需要推導(dǎo)獲得每一個未知參數(shù)的條件分布,然后利用Gibbs抽樣和Metropolis-Hastings 抽樣算法相結(jié)合的混合MCMC抽樣算法來從各自的條件分布中抽樣,具體如下.
·θ的條件分布

·γ的條件分布
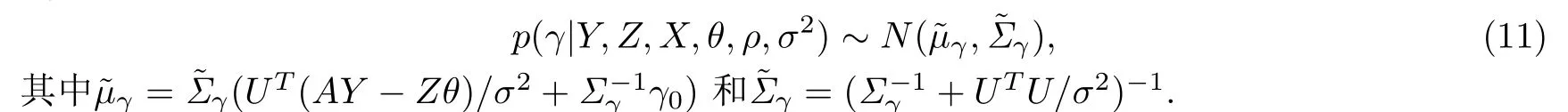
·σ2的條件分布
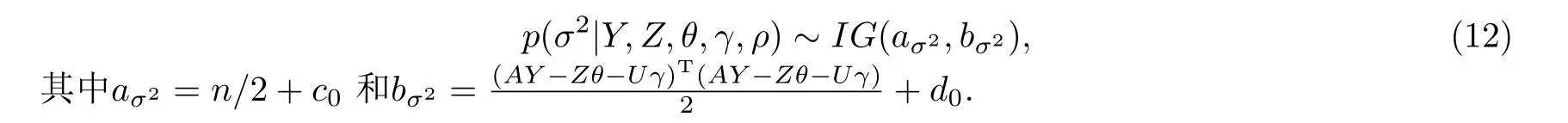
·ρ的條件分布

那么這樣就可以通過表1中的具體MCMC算法產(chǎn)生后驗樣本序列(θ(l),γ(l),ρ(l),σ2(l)),l=1,···,J.從(10)-(12)表達式中很容易發(fā)現(xiàn),這些條件分布是熟悉的正態(tài)分布和逆Gamma分布,那么從這些分布抽取隨機數(shù)是比較容易的.但是條件分布p(ρ|Y,Z,X,θ,γ,σ2)是不熟悉且相當復(fù)雜的分布,如何從這個分布中抽取隨機數(shù)是比較困難.這樣,選擇Metropolis-Hastings算法來從這個分布中抽取隨機數(shù).并選擇正態(tài)分布作為建議分布[21],其中通過選擇來使得接受概率在0.25與0.45之間.算法具體應(yīng)用如下: 在(l+1)次迭代時且目前值為ρ(l),從建議分布產(chǎn)生一個新的備選值ρ*,它被接受的概率為

表1 未知參數(shù)Ψ=(θ,γ,ρ,σ2)的后驗樣本抽樣算法
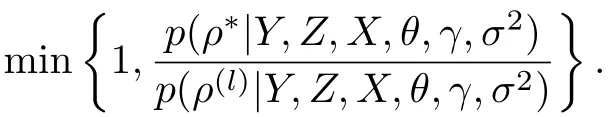
這樣基于以上MCMC算法就可以收集到收斂的后驗樣本并記收集到的MCMC樣本為Ψ(k)=(θ(k),γ(k),ρ(k),σ2(k)),k=1,···,M,M <J.這樣參數(shù)的后驗均值估計分別可以估計為


§4 模擬研究
本節(jié)通過數(shù)值模擬研究來說明前面提出的貝葉斯估計方法的有效性.數(shù)據(jù)從模型(2)產(chǎn)生,其中θ=(1,-0.5,0.5),Z產(chǎn)生于多元正態(tài)分布N(0,ΣZ),(ΣZ)i,j=0.5|i-j|,i,j,=1,2,3.為了比較不同的信噪比影響,選取模型方差σ2=0.25和1.另外令空間參數(shù)ρ=0.5,0,-0.5表示不同程度與方向的空間依賴性.類似于Lee(2004)[22],設(shè)置權(quán)重函數(shù)W=IR ?Hq,Hq=,其中l(wèi)q表示全是1的q維向量,“?”表示Kronecker積,n=R×q.針對函數(shù)型部分,類似于Shin(2009)[2],函數(shù)型系數(shù)其中ξj獨立同分布于均值為0,方差為λj=((j-0.5)π)-2的正態(tài)分布,在這個模擬中,考慮未知參數(shù)θ,γ,ρ,σ2的無信息先驗:θ0=03,Σθ=10×I3,γ0=0m,Σγ=10×Im,c0=d0=0.01,其中0m表示全是0的m維向量.進一步選擇R=50,70和q=3,6.這里通過使用函數(shù)型主成分分析方法獲得最優(yōu)的截斷參數(shù)m,即
在上面的各種設(shè)置環(huán)境下,應(yīng)用聯(lián)合Gibbs抽樣和Metropolis-Hastings算法的混合MCMC算法來計算未知參數(shù)的貝葉斯估計.對于每一種情形重復(fù)計算100次.對于每次重復(fù)產(chǎn)生的每一次數(shù)據(jù)集,MCMC算法的收斂性可以通過EPSR值來檢驗[23],并且在每次運行中觀測得到在3000次迭代以后EPSR值都小于1.2且接近于1.因此在每次重復(fù)計算中丟掉前3000次迭代以后再收集M=2000個樣本來產(chǎn)生貝葉斯估計.所有的結(jié)果展示在表2-4中.另外,為了測量函數(shù)型系數(shù)估計的好壞,選擇用如下定義的RASE來衡量精確度

表2 當ρ=0.5時不同情況下未知參數(shù)的貝葉斯估計結(jié)果
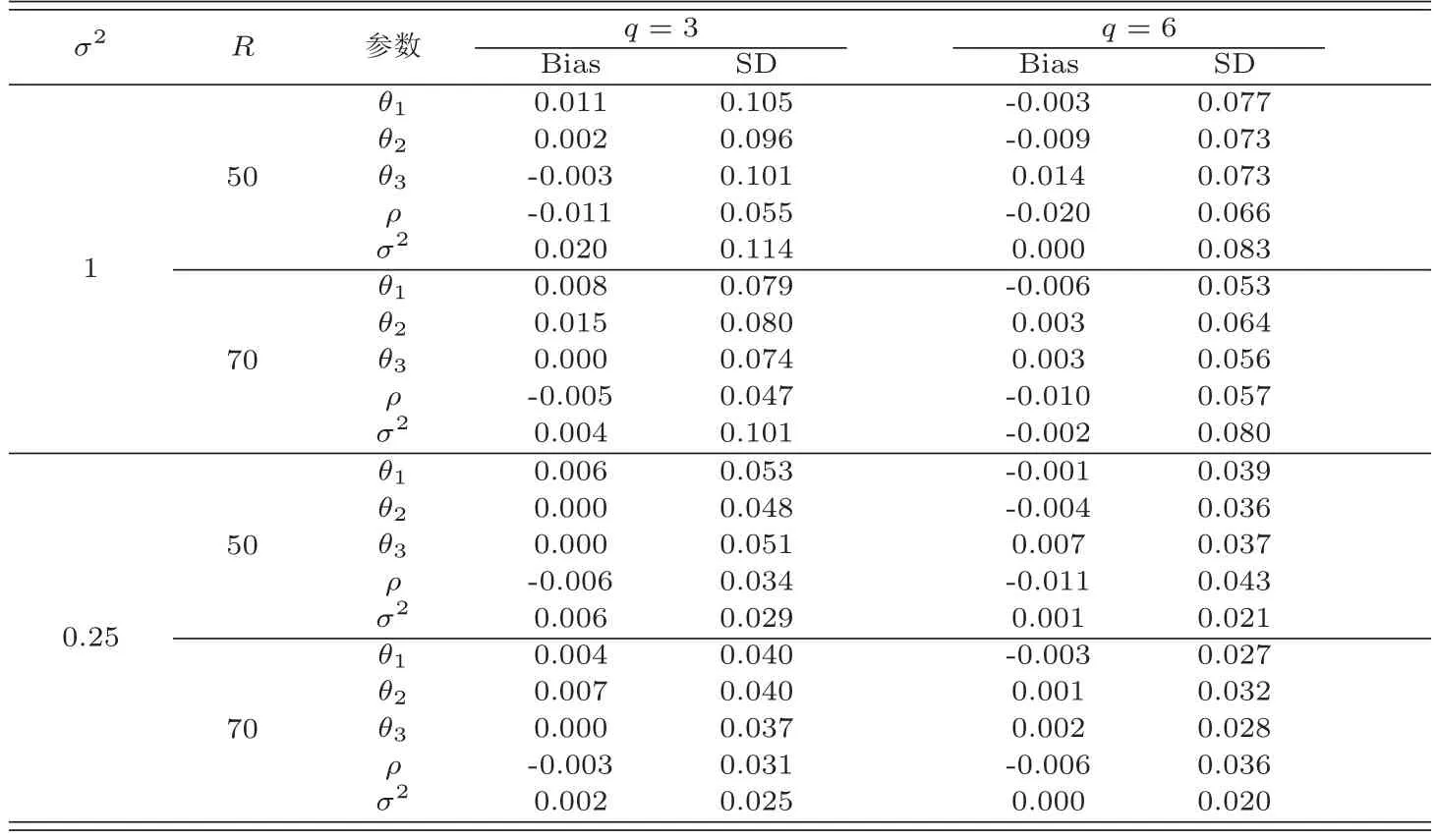
表3 當ρ=0時不同情況下未知參數(shù)的貝葉斯估計結(jié)果
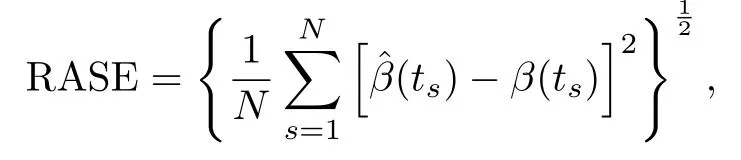
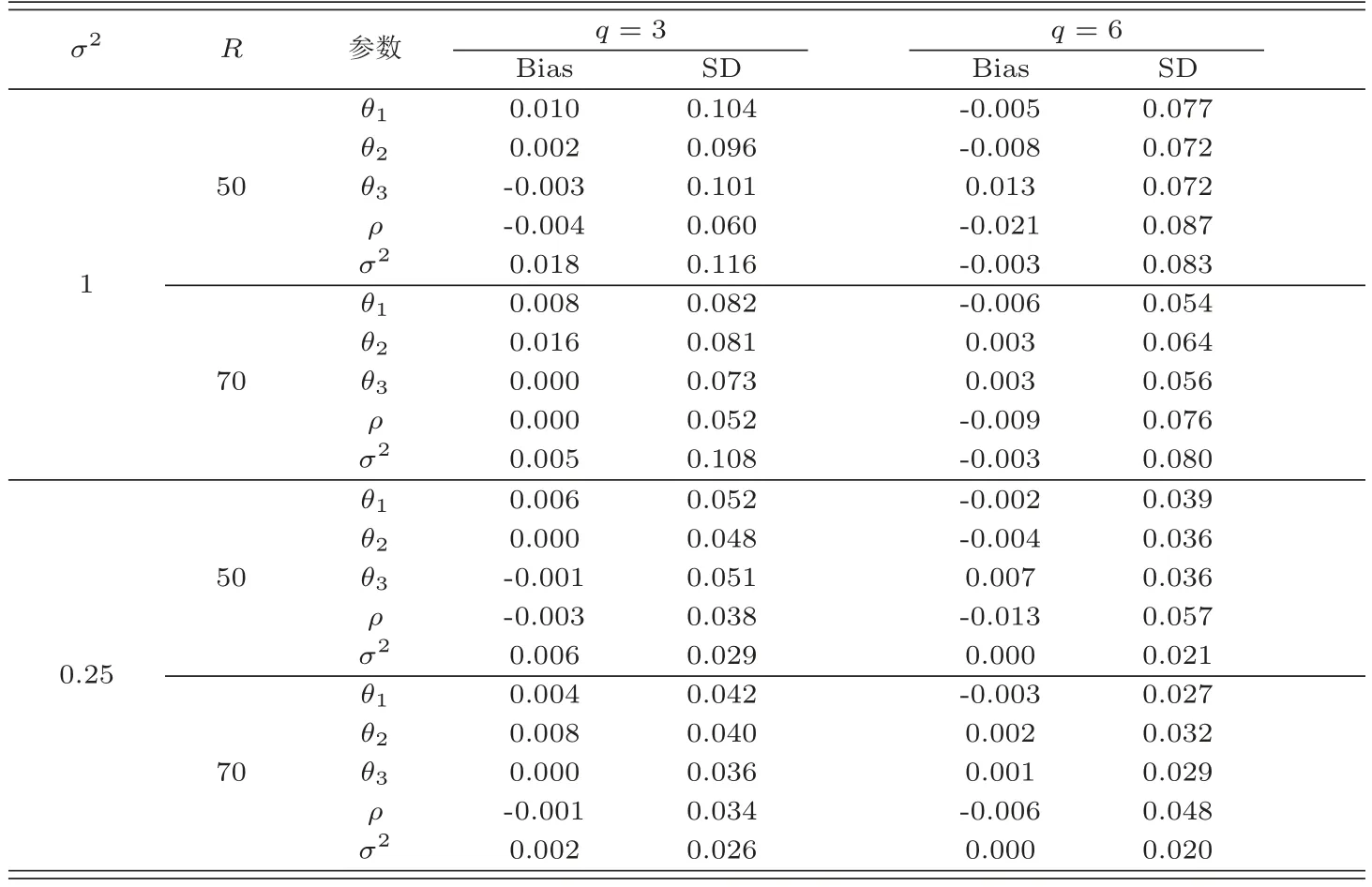
表4 當ρ=-0.5時不同情況下未知參數(shù)的貝葉斯估計結(jié)果
其中ts,s=1,···,N表示函數(shù)型系數(shù)計算的格子點,N=200.模擬結(jié)果展示在表5中.為了更加直接的看出函數(shù)型系數(shù)估計的好壞,畫出并展示了一部分曲線估計圖在圖1-圖6中.
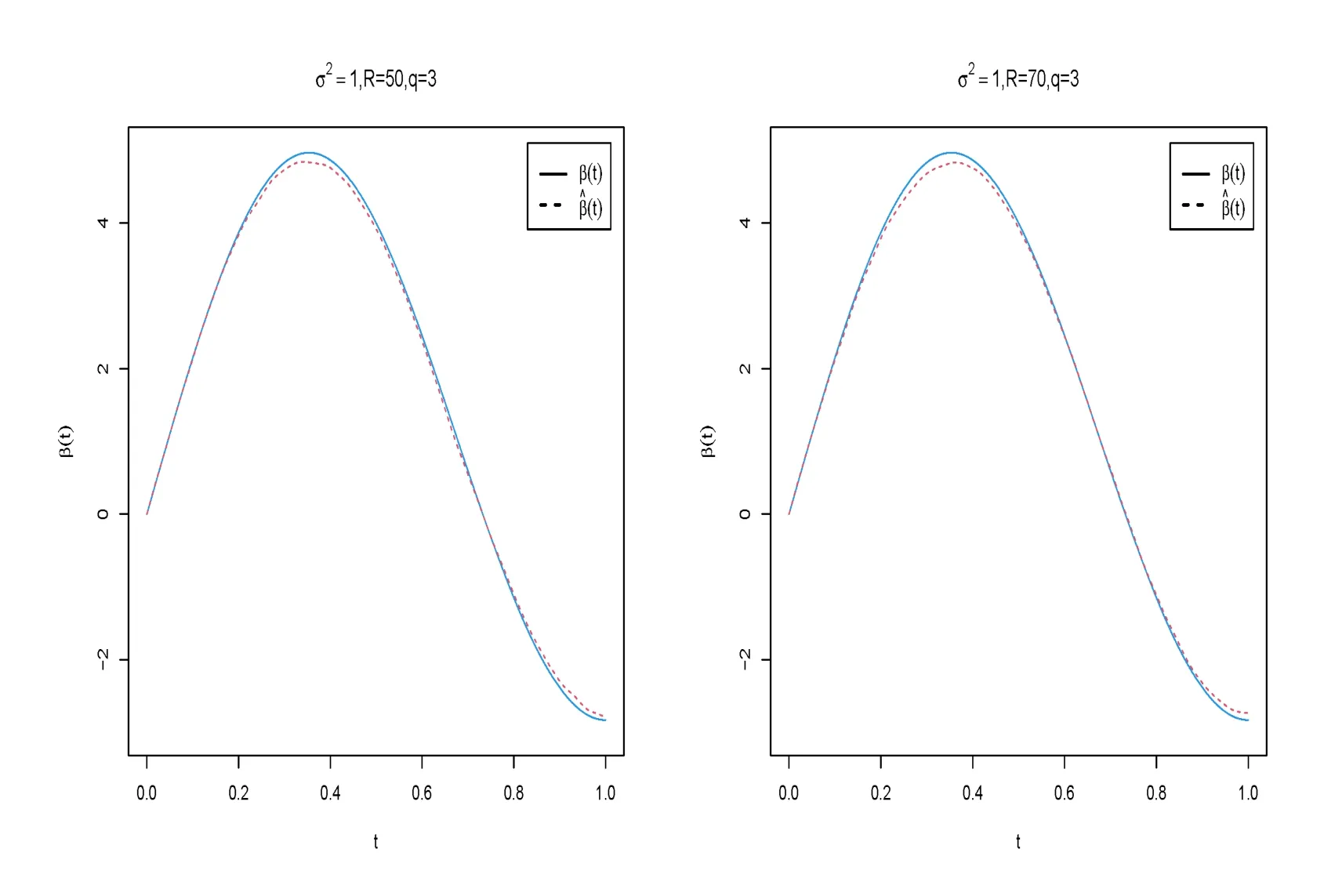
圖1 當ρ=0.5時, σ2=1,R=50,q=3和σ2=1,R=70,q=3的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果

圖2 當ρ=0.5時, σ2=1,R=50,q=6和σ2=1,R=70,q=6的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果

圖3 當ρ=0.5時, σ2=0.25,R=50,q=3和σ2=0.25,R=70,q=3的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果
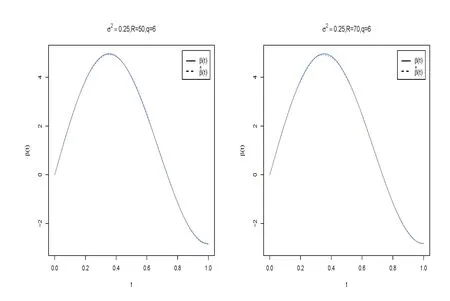
圖4 當ρ=0.5時, σ2=0.25,R=50,q=6和σ2=0.25,R=70,q=6的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果
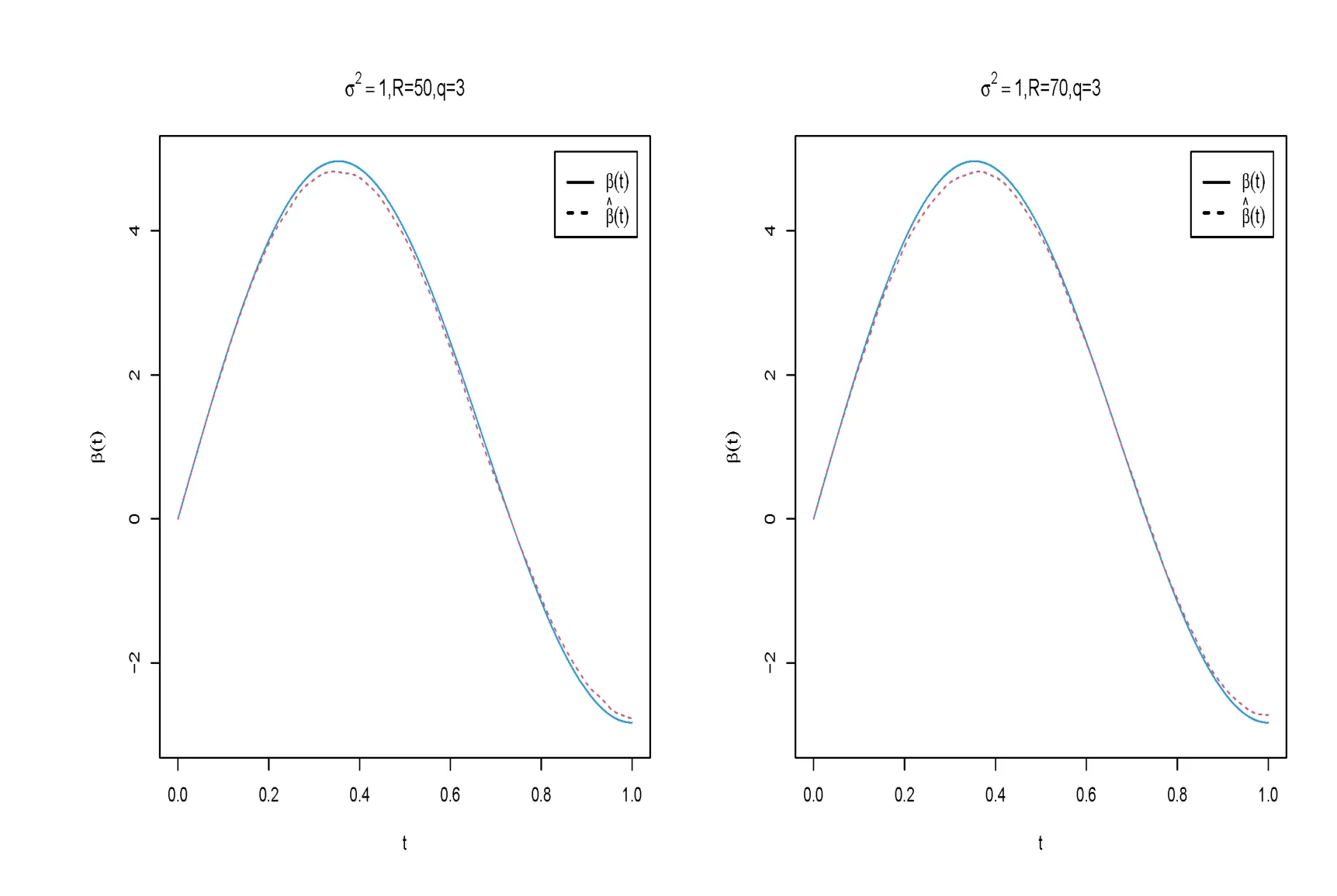
圖5 當ρ=0時, σ2=1,R=50,q=3和σ2=1,R=70,q=3的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果
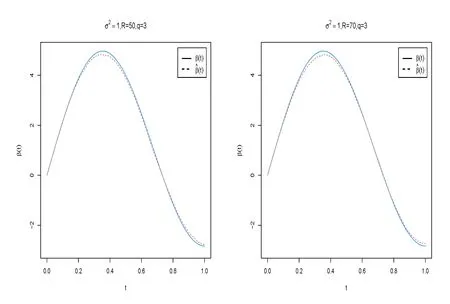
圖6 當ρ=-0.5時, σ2=1,R=50,q=3和σ2=1,R=70,q=3的函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果
在表2-表4中,“Bias”表示基于100次重復(fù)計算未知參數(shù)的貝葉斯估計和真值之間的偏差,“SD”表示未知參數(shù)貝葉斯估計的標準差.從表2-表5中可以得到以下結(jié)論(i)在估計的偏差Bias和SD值方面,不管何種情形下貝葉斯估計都相當精確.并且隨著樣本量的增大,模型中參數(shù)部分和函數(shù)型系數(shù)部分的貝葉斯估計結(jié)果變得越來越好.(ii)基于不同的空間參數(shù)ρ,貝葉斯估計結(jié)果都是一樣的好.(iii)當模型方差逐漸變小時,貝葉斯估計效果也變得越來越好.(iv)隨著樣本量的增大,RASE值變得越來越小,這也表明函數(shù)型系數(shù)估計得越來越好.從圖1-圖6中也展示了不管何種情形下,估計出來的函數(shù)型系數(shù)的曲線與相應(yīng)的真實函數(shù)的曲線逼近得都比較好,這與表5展示出來的結(jié)果是一樣的.總之,從以上所有結(jié)果中可以看出應(yīng)用提出的貝葉斯估計方法能很好地恢復(fù)函數(shù)型空間自回歸模型中的真實信息.
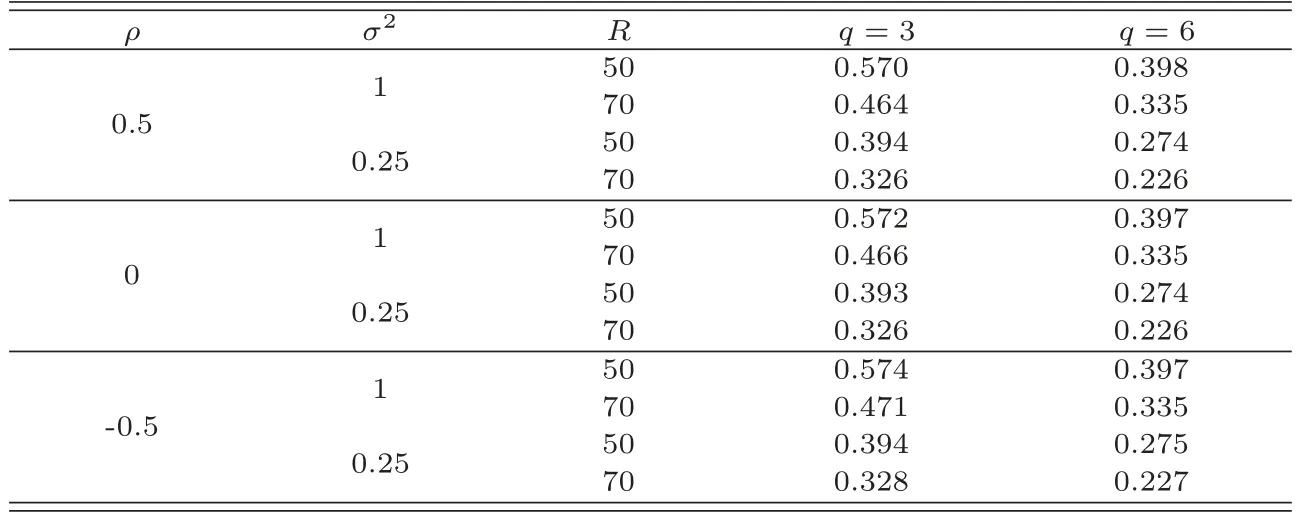
表5 不同情況下函數(shù)型系數(shù)β(t)的貝葉斯估計結(jié)果(RASE值)
另外,為了測試提出的貝葉斯估計方法在協(xié)變量高維情況下的效果,令θ=0.5×1K,K=15,“1K”表示全是1的K維向量.其它參數(shù)的設(shè)置和前面一樣.為了節(jié)省空間,在這里僅列出σ2=0.25,R=70,q=3情況下的模擬結(jié)果并展示在表6中,表中“Biasθ” 表示所有θ分量估計的偏差絕對值的和,“SDθ” 表示所有θ分量估計的標準差的和;“Biasσ2”,“Biasρ”,“SDσ2”,“SDρ”表示相應(yīng)參數(shù)的絕對偏差和標準差;“RASEβ”表示函數(shù)型系數(shù)β估計的RASE值.從表6中不難發(fā)現(xiàn),在不同的空間參數(shù)下,所有參數(shù)的估計效果差別不大且是比較滿意的.這說明所提出的貝葉斯估計方法在高維情況下運行是可行有效的.

表6 當R=70,q=3,σ2=0.25時高維協(xié)變量情況下所有參數(shù)的貝葉斯估計結(jié)果
§5 實際數(shù)據(jù)分析
本節(jié)利用前面提出的函數(shù)型空間自回歸模型與貝葉斯方法來分析加拿大氣溫數(shù)據(jù),有關(guān)數(shù)據(jù)描述可以參見R語言包fda中CanadianWeather的介紹.該數(shù)據(jù)由加拿大35 個氣象站1960年到1994年期間每天的平均降雨量,平均氣溫以及氣象站所處的經(jīng)緯度等信息數(shù)據(jù)組成.為了分析年降雨量和氣溫之間的關(guān)系,假設(shè)35個氣象站的年平均降雨總量的對數(shù)為Y,35 個氣象站的每天平均氣溫曲線為X(t).在這里首先用如下定義的莫蘭指數(shù)計算空間相關(guān)性,
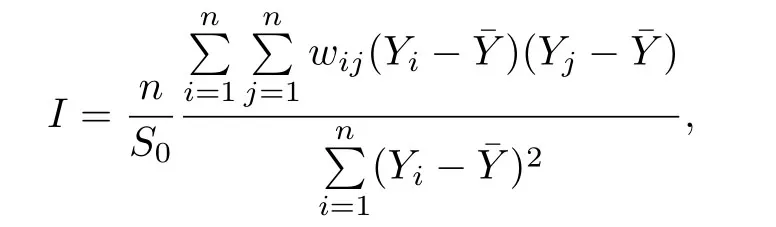
其中n=35,wij是空間權(quán)重值,即空間權(quán)重矩陣W的元素;S0是所有空間權(quán)重的聚合,即S0=在這個實證分析中,首先利用35個氣象站的經(jīng)緯度數(shù)據(jù)計算它們各自的歐氏距離,然后用歐氏距離的倒數(shù)以及進行標準化生成空間權(quán)重矩陣W.在此基礎(chǔ)上計算出莫蘭指數(shù)為0.2655和顯著性檢驗p值為0.000,因此可以認為35個氣象站的年降雨量存在空間相關(guān)性,有理由認為存在空間效應(yīng).故為了分析每天平均氣溫對年平均降雨量的影響,采用以下的函數(shù)型空間自回歸模型進行分析,

通過應(yīng)用文中提出的貝葉斯估計方法和無信息先驗獲得空間參數(shù)的估計為=1.184以及函數(shù)型系數(shù)β(t)的曲線估計和95%的置信帶估計如圖7所示.其中為了測試算法的收斂性,畫出了所有未知參數(shù)的EPSR值的圖,且列在圖8中,從圖8中也能看出3000次迭代以后所有參數(shù)的EPSR值都小于1.2,這表示3000次迭代以后算法都收斂了.

圖7 實例分析中函數(shù)型系數(shù)β(t)的貝葉斯估計(實線);以及95%的置信帶估計曲線(虛線)
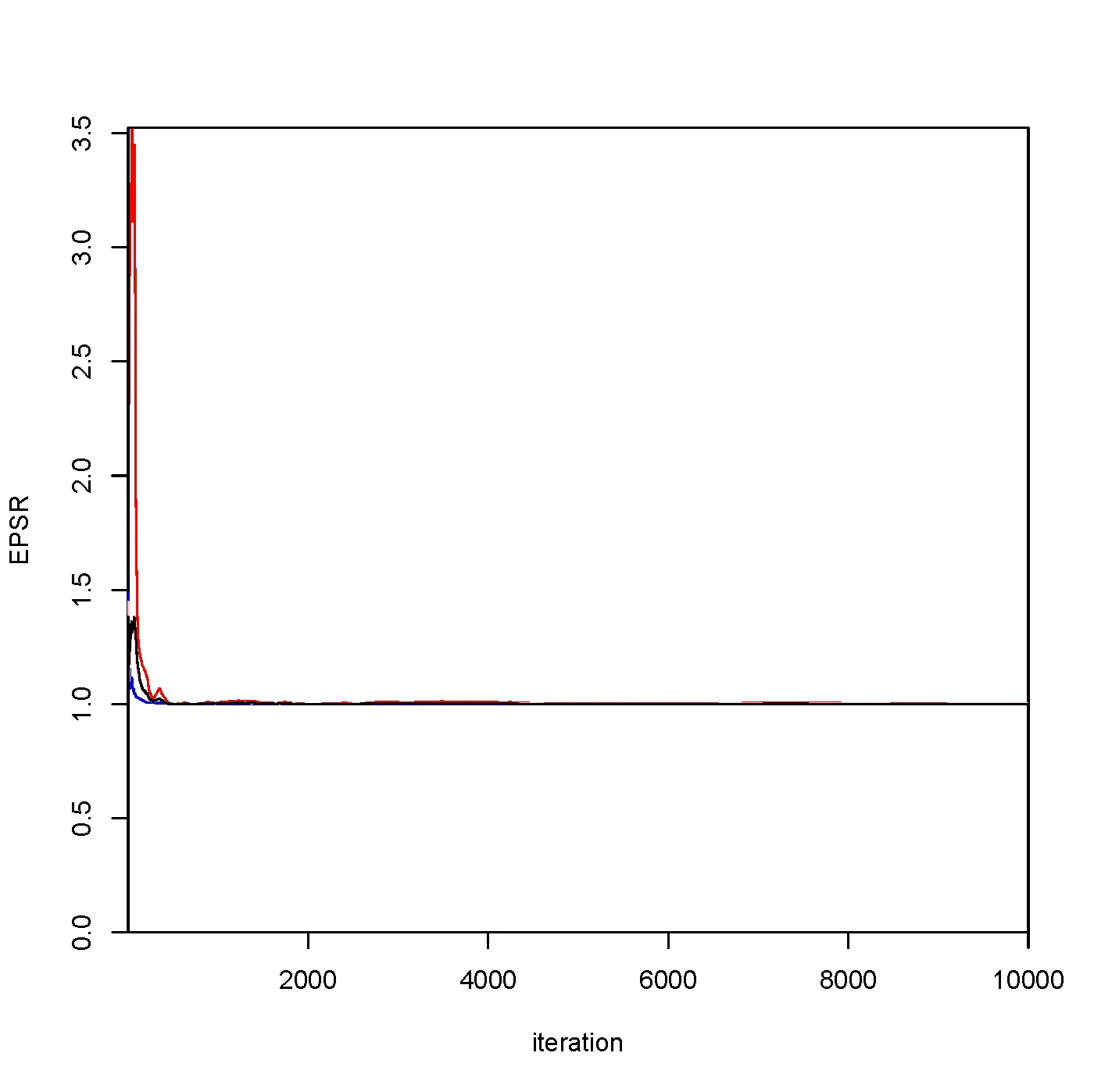
圖8 實際數(shù)據(jù)分析中所有參數(shù)的EPSR值
最后再次對殘差數(shù)據(jù)計算獲得莫蘭指數(shù)為-0.054和顯著性檢驗p值為0.449,因此可以認為使用該空間模型有效提取了信息和模型擬合效果還是比較不錯的.
§6 結(jié)論
針對響應(yīng)變量具有空間效應(yīng)的部分函數(shù)型空間自回歸模型,應(yīng)用基于Gibbs抽樣和Metropolis-Hastings算法相結(jié)合的混合MCMC算法,以及運用Karhunen-Lo`eve表示定理來逼近函數(shù)型系數(shù)的思想研究了模型的貝葉斯估計方法.模擬研究顯示(1) 隨著樣本量的增大,函數(shù)型系數(shù)和參數(shù)部分的貝葉斯估計效果都是越來越好;(2) 在不同的空間參數(shù)模擬環(huán)境設(shè)置下獲得的模型貝葉斯估計效果都是一樣好;(3) 隨著模型方差逐漸變小,模型中參數(shù)部分和函數(shù)型系數(shù)部分估計的效果也都會變得越來越好.另外對加拿大氣溫數(shù)據(jù)進行了實證分析,首先計算度量空間相關(guān)性的莫蘭指數(shù),顯示數(shù)據(jù)具有空間相關(guān)性.因此應(yīng)用提出的函數(shù)型空間自回歸模型對數(shù)據(jù)進行了建模和貝葉斯分析,通過混合MCMC算法獲得空間參數(shù)和函數(shù)型系數(shù)的估計,最后也進行了殘差分析,結(jié)果顯示該模型擬合數(shù)據(jù)比較有效.因此通過這些模擬仿真結(jié)果和實證分析結(jié)果都顯示了所提出的模型與貝葉斯方法的有效性和可行性.
猜你喜歡
小學(xué)生學(xué)習(xí)指導(dǎo)(高年級)(2021年4期)2021-04-29 02:17:10
河北理科教學(xué)研究(2020年2期)2020-09-11 06:15:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年11期)2019-01-31 02:39:26
娃娃樂園·綜合智能(2018年23期)2018-12-26 09:10:20
娃娃樂園·綜合智能(2018年3期)2018-03-22 06:13:46
數(shù)理化解題研究(2017年4期)2017-05-04 04:07:54
中國照明(2016年6期)2016-06-15 20:30:14
鐵道通信信號(2016年6期)2016-06-01 12:10:20
電子器件(2015年5期)2015-12-29 08:43:15
數(shù)學(xué)年刊A輯(中文版)(2015年2期)2015-10-30 01:56:14
