
Deep reinforcement learning based task offloading in blockchain enabled smart city①
2023-09-12 07:30JINKaiqi金凱琦WUWenjunGAOYangYINYufenSIPengbo
High Technology Letters 2023年3期
JIN Kaiqi (金凱琦),WU Wenjun,GAO Yang,YIN Yufen,SI Pengbo
(Faculty of Information Technology,Beijing University of Technology,Beijing 100124,P.R.China)
Abstract With the expansion of cities and emerging complicated application,smart city has become an intelligent management mechanism.In order to guarantee the information security and quality of service(QoS) of the Internet of Thing(IoT) devices in the smart city,a mobile edge computing (MEC) enabled blockchain system is considered as the smart city scenario where the offloading process of computing tasks is a key aspect infecting the system performance in terms of service profit and latency.The task offloading process is formulated as a Markov decision process (MDP) and the optimal goal is the cumulative profit for the offloading nodes considering task profit and service latency cost,under the restriction of system timeout as well as processing resource.Then,a policy gradient based task offloading (PG-TO) algorithm is proposed to solve the optimization problem.Finally,the numerical result shows that the proposed PG-TO has better performance than the comparison algorithm,and the system performance as well as QoS is analyzed respectively.The testing result indicates that the proposed method has good generalization.
Key words: mobile edge computing(MEC), blockchain, policy gradient, task offloading
0 Introduction
Developed with the help of big data and Internet of Thing (IoT)[1],the smart city is capable of the intelligence management in terms of smart grid,smart community, smart hospitality, smart transportation,smart warehouse and smart healthcare[2].However,most of the IoT devices in smart city are lack of integrated security mechanisms and vulnerably exposed in the open area,which brings challenges such as data privacy and security into smart city[3-4].
Fortunately,blockchain,which is an intelligent decentralized system using distributed databases to identify,disseminate and record information,makes it possible to guarantee the data security and establish a reliable network system[5].The core techniques of blockchain are consensus mechanism and smart contract,which are responsible for the development of trust among distributed nodes and autonomic management of the system,respectively.Due to the intervention of blockchain,the security access[6],data privacy and security[7-8]and data integrity[9]can be ensured in smart city.
However,it is wildly acknowledged that the operation of consensus mechanism and smart contract of blockchain requires substantial computation resource.To further facilitate the implementation of blockchain in smart city,mobile edge computing (MEC) servers are always deployed with the access points to provide highly expandable computation resource[10]and reduce the service latency[11].
In the MEC-enhanced smart city,the wireless resource allocation problem has been wildly studied.The dynamic scheduling problem is researched in the Internet of Everything,and a multiple scheduling algorithm is proposed adopting round robin scheduling,proportional fair scheduling and priority based scheduling,enhancing the resource allocation efficiency[12].The joint user association and data rate allocation problem is modeled to optimize the service delay and power consumption,and correspondingly solved by iterative algorithm and bisection algorithm[13].Task offloading is the most typical resource management problem in MEC,and it is also widely studied in the scenario of smart city.In a multi-user and multi-server MEC scenario,a joint task offloading and scheduling problem is studied aiming to minimize task execution latency and solved by a heuristic algorithm[14].Aiming at the maximization of offloading accomplish rate,problems restricted by the power consumption of mobile equipment as well as the deadline of offloading tasks are studied by adopting deep reinforcement learning (DRL) and convex optimization[15-16].Considering the time cost,energy cost of IoT devices and resource utilization of cloudlets in smart city, the computation offload problem is researched,and a balanced offload strategy is perceived using Pareto optimization[17].By using game theory,the comprehensive profit of mobile devices and edge service providers are designed as optimization problems,coming up with an offloading solution enhancing both data privacy and system power efficiency[18].
When blockchain is enabled in smart city,the resource management problem is necessarily considered with more variables such as task profit obtained from the blockchain system,service latency and resource occupation.To optimize these multiple optimization objectives with complex restrictions,DRL is efficient by the perception ability of deep learning and the decisionmaking ability of reinforcement learning[19-20].In blockchain enabled MEC scenario,task scheduling and offloading problems are studied and modified as Markov decision process(MDP).Policy gradient method is adopted to solve the optimization goal considering the long-term mining reward,system resource and latency cost while deep Q-learning (DQL) optimizes the task execution delay and energy consumption[21-22].Another DRL method called asynchronous advantage actor-critic(A3C) is applied in the cooperative computation offloading and resource allocation scenario,enhancing the computation rate and throughput as main factors of optimization function[23].In the intelligent resource allocation mechanism for video services,the system performance is optimized by A3C in terms of throughput and latency[24].Aiming at the system energy efficiency in Internet of Vehicles (IoV) scenario,A3C is also adopted to solve the optimization function composed of energy and the computation overheads[25].
Specifically,in a related scenario proposed in Ref.[26],where MEC provides users with sufficient resources to reduce the computing pressure in the IoT system supported by blockchain,the node matching between users and edge computing servers in consideration of wireless channel quality and QoS is studied,the simulation results show excellent performance with the help of reinforcement with baseline algorithm.However,different from the common IoT,the smart city has diverse requirements in application layer,and the demand of high restrictions on latency in applications such as high definition (HD) mapping and intelligent driving decision in smart traffic service is one of the most important factors[27].In this perspective,the application implied in the smart city dabbles in a wider range and ensures more latency restriction in comparison with common IoT services,which has not been fully studied.
In order to realize the data security and ensure the quality of service(QoS)requirements of smart city applications,both the blockchain and MEC technologies are adopted to enhance the system.The secure process and storage of original data from the smart city applications with latency constraint is considered as the task.The task offloading problem maximizing the long-term reward which consists of the profits of task processing and the cost of task processing latency is the main concern.The task offloading problem is formulated as a MDP,and the DRL method which uses a deep neural network as the decision agent is used to optimize the long-term reward.The episodic simulation is built,and the policy gradient (PG) with baseline algorithm is adopted to train the decision agent.The performance with different environment parameters are tested,which respectively confirm the effectiveness and the generalization ability of the policy gradient based task offloading(PG-TO)algorithm.
The rest of this article is organized as follows.System model is formed in Section 1.The task offloading problem is formulated in Section 2 with the definition of the actions,states and rewards of the MDP.In Section 3,DRL is used to solve the task offloading problem.The training and testing results are given in Section 4.At last,this paper is concluded in Section 5.
1 System model
In this paper,the MEC-enhanced smart city scenario is considered,and the blockchain technology is adopted to ensure the secure process and storage of original data from the smart city applications.As shown in Fig.1,the system is composed of physical layer and blockchain layer,which is described in detail in this section.Besides,the reputation model and the profit model are also given in the following.
1.1 Physical layer
The physical layer of the proposed MEC-enhanced smart city with blockchain management functions is shown in Fig.1.There are 3 classes of participants in the proposed physical layer,which are user equipment(UE),access point (AP),and main access point(MAP).
(1) UE can be IoT device or mobile device which has limited frequency and computing resources.It is the user of various emerging applications in smart city,and the key information of its applications or behaviors are considered as the computation task which needs to be uploaded to the blockchain for secure process and storage.It is capable of operating the preset program according to the smart contract in blockchain but does not participate in the consensus process.
(2) AP is generally the small base station deployed with MEC server.It performs as the blockchain node which takes part in the consensus process in blockchain and is responsible for uploading the offloaded tasks from UEs to the blockchain.
(3) MAP is the central control node which is in charge of assigning the computation tasks form UEs to appropriate APs.Besides,it has the similar property as AP that it can participate in the consensus process and maintain the blockchain system.
1.2 Blockchain layer
As the rules of blockchain nodes running in the smart city,the smart contract defines the detailed responsibility of the nodes.Based on the smart contract,the specific steps of the task offloading process are shown below.
(1) UE adopts various applications in smart city generating computation task and declares the average task fee it can pay for the task.
(2) UE generates task offloading request including information of the average task fee and the latency limitation,and sends the requests to the MAP.
(3) MAP observes the frequency and computing resource occupation of all the APs,the reputation value of the APs and the arrived task offloading requests of the UEs.
(4) MAP assigns the tasks to APs according to the current system observation in step(3).
(5) APs allocate frequency and computing resources to transmit and compute the offloaded tasks.
(6) If the task is offloaded and computed successfully within the tolerable latency,the task is accomplished and task fee is paid to the APs as task profit.Otherwise,AP does not get paid.
(7) MAP updates the reputation value of APs according to the accomplish status of tasks.
1.3 Reputation model
In order to value the reputation and profit for each APs,the corresponding value model is proposed in the following subsections.As the historical reputation of each blockchain node reflects its competitiveness in the consensus process,the credit model formulated in a MEC enabled blockchain system[26]is used in this paper.The reputation is denoted byri,which shows the reliability of thei-th AP and is closely related to the probability of accomplishing a task within the tolerable latency.The value ofriis linear within a restricted rangeri∈[1,5] ,whose initial value is set as 3.Every time if the task is accomplished by thei-th AP,(ri+0.1),otherwise,(ri-0.5).
1.4 Profit layer
The profit of APs is only contributed by the task fee paid from the offloaded tasks of UEs.In order to establish an incentive mechanism,it is supposed that APs that have high reputation value will be paid with more profit,which is a reward and approval for the high quality of service.When thei-th AP accomplishes thej-th offload service,the practical profit can be described as

2 Problem formulation
In the blockchain enabled smart city scenario,the frequency and computing resources of the APs are limited.As the task offloading is a key process which can affect not only the profit of the APs but also the overall system performance,it is formulated as an optimization problem.The target is set to be maximizing the longterm cumulative profit gains from offloaded tasks for APs while considering the limitation of the resources of APs and the service latency constraint for QoS.The optimization problem is formulated as

According to the system model described in Section 1,as MAP only observes the situation of current time step,the task offloading process has the Markov property, which is modeled as a Markov decision process (MDP).The MDP is denoted as(S,A,P,R) ,whereSstands for state space,andArepresents the action space.Specifically,Pis defined asP(s′|s,a) to describe the probability of the system state transition froms∈Stos′∈Safter taking actiona∈A,whileRis defined asR(a,s) which is the reward from taking actionawhen state iss.The detailed definition of state,action and reward is shown below.
2.1 State
The design of state should consider those elements includingSA,SR,SOandSB.SArepresents the state of the APs,which includes the frequency and computing resource occupation situation of the current time and the next(T-1) time steps.SRdenotes the state of the processing tasks in the system,including the index and reputation value of the AP where the tasks are offloaded,and the practical profit gain for AP when tasks are accomplished.SOandSBgive the state of tasks which have arrived and are waiting to be offloaded.SOdenotes the tasks which can be observed in detail,including information of the required frequency resource in each APs if offloaded to,the related transmission latency and the expected profit.AndSBdenotes the extra unobservable tasks that have arrived at the system,including the arrival time,expected profit and the expected service latency of these tasks.The state structure detail is shown in Fig.2.
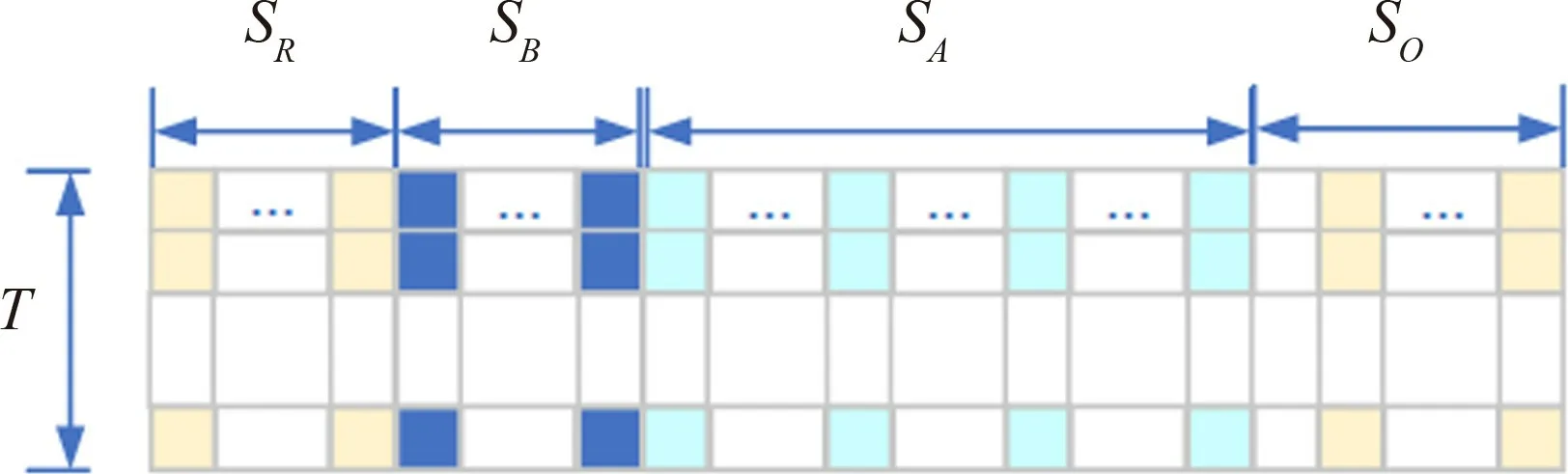
Fig.2 The state observation of each time step t
2.2 Action
In the researched scenario,as MAP is capable of observing state information of APs,the definition of action is to select the suitable APs for UEs to offload their tasks.In time stept,if the await offloaded tasks number isDtand the APs amount isNA,the action space size is (NA+1)Dt,for the reason that the task could be either offloaded to any of the APs or not.Therefore,the action space is so huge that the efficiency of the proposed algorithm would decrease.As a result,simplify the action space by observing the firstKnumber of await tasks at each time step and offload them adopting first-in-first-out (FIFO) method.
As the intellectual property of task offloading,the optimization of long-term accumulation value by serial decision could be realized the same as the parallel decision.Hence,it is considered that the parallel action decisions are decomposed into serial decisions in the same time step.The decision times in time steptis denoted asXtand all the action in the time steptis denoted as
In this method could the action space be reduced,whose space size isNA+1 ,denoting as{1,2,…,NA,?} ,whereat,x=imeans that the first await task will be processed by thei-th AP in thex-th step at timet.Specifically,if the first task is thej-th task in the system task process list,at,x=istands forat,ji= 1.
2.3 Reward
As the optimization problem is defined in Eq.(3),the computing and frequency resources are easily implemented that MAP will not offload tasks to the APs whose frequency and computing resources are insufficient.As for the service experience,the service latency restriction of tasks in Eq.(3) can be defined as a penalty function in the reward to guarantee the accomplish rate of the scheme.Therefore,the reward can be defined based on Eq.(3) as

where the discount factor isδ= 1 ,andTMdenotes the maximum time step number of one episodic simulation.
3 Policy gradient based task offloading algorithm
This section introduces the PG with baseline which is one of the DRL algorithms,to develop the policy gradient-based task offloading algorithm (PG-TO)for the proposed optimization problem.The PG-TO algorithm is illustrated in detail including the adoption of the PG with baseline method and the episodic simulation process in the following.
3.1 The adoption of PG with baseline
The adoption of PG with baseline algorithm in the proposed optimization problem and the data flow of state,action and reward in the training process are shown in Fig.3.The PG agent,which is the policy networkπθ,outputs the probability distribution of action according to the input state,and then randomly chooses the action based on the probability distribution.The network parameterθinπθis continuously optimized after each training iteration.In this way,the probability distribution of actions under each state can be established and approach the optimal strategy of probability distribution of action.

As the average profit of each time step for theq-th sample,the baseline is calculated for eachEtimes of episodic simulation in one iteration.The variance is reduced and the efficiency of policy training is enhanced by the deduction of baseline fromvi,l.

Fig.3 The data flow in the training of the proposed PG-TO algorithm
3.2 Simulation design
The overall episodic simulation design of the proposed PG-TO algorithm is shown as Algorithm 1.The total iteration number is set asPand the policy networkπθis trained based on the PG with baseline.

Algorithm 1 PG-TO 1: Establish UEs,APs and MAP in the simulation environment,initialize the related system parameters.2: Generate Q worksheets.3: Randomly initialize the neural network parameters θ by normal distribution.4: for iteration p < P do 5: for episodic simulation i < I do 6: get the initial state si,l = si,0 7: while time step t < TM do 8: based on πθ and si,l get ai,l 9: if action ai,j =?then calculate kt according to Eq.(5)update t = t +1 10: else Offload the j-th task to the ai,l -th APs kt = 0 acquire f^j ,t^f,j 11: end if 12: store si,j,ai,j,ri,j in the trajectory 13: update J1(t) ,J2(t)14: update state si,l 15: end while 16: end for 17: Calculate the baseline b「i/E?,l by Eq.(8)18: Update parameters of network by Eq.(7)19: end for
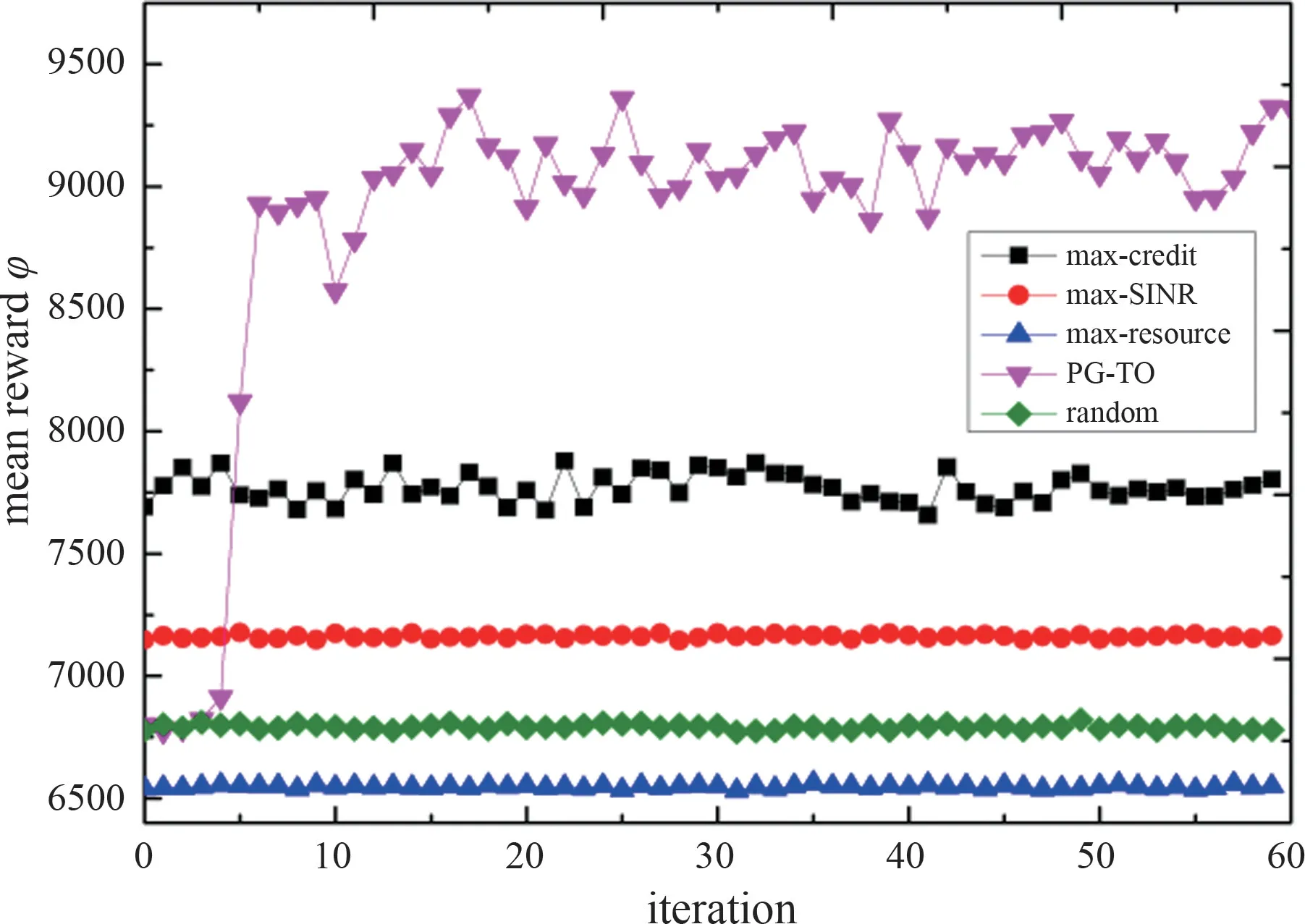
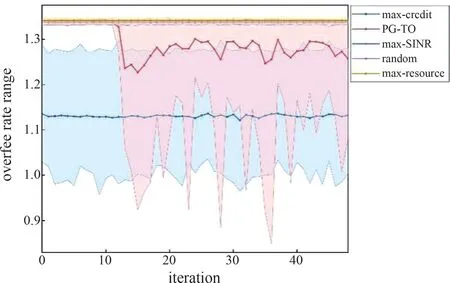
In the beginning of each time of episodic simulation,the policy networkπθtakes observation of current simulation environment gettingsi,land output the probability distribution of action.Then, actionai,lis selected randomly according to the output probability distribution of action.Ifai,l=?, there is no task offloaded to any APs at current time step, is obtained according to Eq.(5) and then the system time step moves on.If the related task is offloaded to theai,l-th AP for processing, whilef^jandt^f,jare counted, andri,l=0.Then,{si,l,ai,l,ri,l}is recorded as one sample in the trajectory.Afterwards, the related task setsare updated and the next statesi,l+1is obtained.The above steps are repeated to obtain a complete trajectory sample of a whole episodic simulation as long ast The training parameters are defined in Table1.Refer to the scenario setting in Ref.[26],which adopts NB-IoT service model specified in 3GPP 36.752[28].The bandwidth is set as 180 kHz,and the number of frequency resource units is 48 as 3.75 kHz single-tone is adopted.The size of task and the corresponding profit for APs are classified into small and big referring to Ref.[26].The transmission frequency resource requirements of tasks are also defined according to the subchannel classifications in NB-IoT.The observable future timeTis set as 300 times steps as the system performance indicators are more reasonable when the system reaches a steady state and to avoid excessive redundant simulation experiments.The number of APsNAin the simulation makes trade-off between system state complexity and reasonable service pressure.The numerical setting ofNTmakes a reasonable size of input state space while the number ofNWcomprehensively considers the APs' numbers,overall system tasks quantity and job density. Symbol Parameter Setting D Maximum frequency resource units number 48 F Maximum computing resource units number 64(Dt,Ft)Frequency resource requirement and transmitting time of j-th data package in each time step (big){(4,8),(1,8),(48,1)}{(24,2),(12,4),(4,2)}T Time steps that can be observed to the future 300 Frequency resource requirement and transmitting time of j-th data package in each time step (small)fj Expected task profit of the j-th task(big) [10,15]Expected task profit of the j-th task(small) [15,20]T~ Maximum latency of tasks 25 NA Number of APs 5 NT Maximum number of observable processing tasks of each AP 25 NW Maximum storage number for await allocate tasks arrived of each AP 125 α Weight for task profit 1 β Latency cost weight for each task 5 λ Tasks arrival rate 0.8 R Proportion of small tasks in all tasks 0.8 The policy network used by PG-TO method has 2 fully hidden layers,each of which has 32 neurons.Moreover,max-SINR,max-credit,max-resource and random are set as the comparison methods.Max-SINR always selects the AP which has the maximum SINR towards UEs.The max-credit prefers the AP with the maximum reputation valueriwhile the max-resource tends to offload tasks to APs with the maximum available frequency and computing resources. Fig.4 Mean reward φ Fig.4 shows the average value of mean rewardφwhich is the averageg(a) ofIsamples in each iteration.For training efficiency,the learning rate is set as 0.001.And then,it is decreased to 0.0005 after 20-th iteration for better convergence performance.Theφof PG-TO rises rapidly and surpasses the value of the max-credit after only 5 iterations,and finally converges to about 9100.Theφof PG-TO is about 16.6% better than the second-best max-credit strategy,while max-SINR strategy is in the third place,about 7180.The random strategy and the max-resource strategy perform worst,both of which range from 6500 to 6800. As two important components inφ,the average task profit and the average latency cost of APs are shown in Fig.5,and their calculation formula is shown in Table 2.In Fig.5(a),the max-credit strategy obtains the largest income among all the comparison algorithms as it always picks the AP with the highest reputation and earns higher task profit for each completed task according to Eq.(1).Meanwhile,max-SINR obtains the lowest latency cost due to the good quality of wireless transmission referring to Fig.5(b).In Fig.5 and Fig.4,it can be found that there is a contradiction between the profit of APs and the latency performance of UEs.However,the advantage in task profit surpasses the shortage of latency cost,so the max-credit reaches the second-best strategy.Specifically for PG-TO,the optimal performance inφis contributed by a little bit better task profit and about 40% less latency cost compared with max-credit. Indicators Calculation formula Figure Task profit α ∑f^j∈Jd(t)j(at)t^f,j + td,j[] Fig.5(a)Latency cost β ∑1 j∈Ja(t)[] Fig.5(b)tf,j + td,j Overtime rate ∑j∈Ja(t)(t^f,j + td,j)/(tf,j + td,j) Fig.6(c)Overfee rate ∑j∈Jd(t)f^j/fj Fig.7 Moreover,the indicators which closely related to the system performance are also calculated and analyzed in Fig.6,and the related calculation formula of Fig.6 (c) is shown in Table.2.As shown in Fig.6(a),the frequency resource occupation of PG-TO is on the same level as the comparison strategies except for max-SINR.This is because the max-SINR strategy causes load imbalance among APs,and thus restricts the utilization rate of frequency resources. As shown in Fig.6(b) and Fig.6(d),the performances of computing resource occupation and the complete rate are consistent.Specifically,in Fig.6(d),the mean complete rate is calculated in the simulation program,which is the ratio of the number of finished tasks to the total number of tasks in the system.It can be observed that the max-credit strategy completes the fewest tasks while the other comparison algorithms complete more amount of tasks and consumes more amount of computing resources. Besides,the ratio of practical task profit to expected task profit is further counted as the overfee rate.Accordingly,the overfee rate range of each strategy is shown in Fig.7,which marks the corresponding maximum and minimum overfee rate of each iteration and the related calculation formula is shown in Table.2.Generally,the mean overfee rate of PG-TO algorithm fluctuates in the range of 1.16 to 1.27,and its mean overfee rate is 14.2% higher than the second-best max-credit strategy,lower than any other comparison strategies.Moreover,it is easily spotted that the variance overfee rate of max-credit and that of PG-TO are at a significantly high level compared with other strategies.The reason is that max-credit strategy always selects the AP with the maximum reputation value,which causes tasks backlogs in the high credit value APs whose reputation declines due to the timeout of tasks.However,as shown in Fig.5(a) and Fig 6(d),maxcredit strategy has greater advantages than other comparison strategies with the lowest complete rate.Hence,it could be indicated that tasks with relatively high initial task fee are opportunistically offloaded to the higher reputation APs while tasks with lower initial task fee are selectively abandoned.Similarly,the intelligent task offloading scheme learned by PG-TO is shown by the training results that it can gradually learn the advantages of the max-credit and alleviate the huge cost of latency as shown in Fig.5(b). Fig.7 Overfee rate range For the policy network trained under the situation that the proportion of small tasks is 0.8,the performance with proportion of small tasks chaning is tested.In the test of each small tasks proportion,100 samples different from the training samples are generated for simulation. Fig.8 shows the test results in the proportion of small tasks from 72% to 88% with 2% interval.As the small tasks proportion increases,the total task profit decreases,thenφvalues of random strategy,max-resource strategy,max-SINR strategy and PG-TO all show a downward trend as a whole accordingly except for the max-credit strategy. For the max-credit strategy,φis positively related to the increase proportion of the small tasks.That is because the overtime problem caused by the unbalanced offloading scheme can be slightly alleviated when the overall load of the system reduces,and then the advantage of choosing the maximum reputation to get the maximum practical task profit becomes obvious.Additionally,PG-TO obtains the highestφwhen the small tasks proportion ranges from 0.72 to 0.86,which indicates a good generalization. Fig.8 Test result of mean reward φ In all,the proposed PG-TO algorithm has a significant advantage in the optimization goal over the other 4 comparison algorithms.The PG-TO algorithm is capable of providing APs with more task profit while maintaining an acceptable latency cost.The resource occupation of PG-TO is at an average value,and the overtime rate along with complete rate are well balanced.Moreover,PG-TO shows a good generalization facing with different level of system tasks load.This means that the proposed PG-TO algorithm is capable of intelligently selecting proper APs to have the tasks offloaded in comprehensive consideration of APs' state,wireless environment,and tasks set while ensuring the latency requirements. This article researches the task offloading process in a MEC-enhanced smart city with blockchain management functions.The task offloading process is modeled as a MDP and an optimization problem is developed focusing on the profit gain for APs and QoS requirement of UEs.The proposed optimization problem is solved by the PG method using the reinforce with baseline algorithm, and its training performance is 16.7% better than the second-best comparison strategy.The test performance with various small task proportion indicates that the proposed PG-TO algorithm has a good generalization.4 Simulation and performance evaluation
4.1 Training performance


4.2 Test performance

5 Conclusion
 High Technology Letters2023年3期
High Technology Letters2023年3期
- High Technology Letters的其它文章
- Joint UAV 3D deployment and sensor power allocation for energy-efficient and secure data collection①
- Experimental study on the failure factors of the O-ring for long-term working①
- Research and experimental analysis of precision degradation method based on the ball screw mechanism①
- In-flight deformation measurement for high-aspect-ratio wing based on 3D speckle correlation①
- Semantic-aware graph convolution network on multi-hop paths for link prediction①
- A greedy path planning algorithm based on pre-path-planning and real-time-conflict for multiple automated guided vehicles in large-scale outdoor scenarios①