
Data-Driven Based Fault Prognosis for Industrial Systems: A Concise Overview
2020-05-22 02:55KaiZhongMinHanandBingHan
Kai Zhong, Min Han,, and Bing Han
Abstract—Fault prognosis is mainly referred to the estimation of the operating time before a failure occurs, which is vital for ensuring the stability, safety and long lifetime of degrading industrial systems. According to the results of fault prognosis, the maintenance strategy for underlying industrial systems can realize the conversion from passive maintenance to active maintenance. With the increased complexity and the improved automation level of industrial systems, fault prognosis techniques have become more and more indispensable. Particularly, the datadriven based prognosis approaches, which tend to find the hidden fault factors and determine the specific fault occurrence time of the system by analysing historical or real-time measurement data, gain great attention from different industrial sectors. In this context, the major task of this paper is to present a systematic overview of data-driven fault prognosis for industrial systems.Firstly, the characteristics of different prognosis methods are revealed with the data-based ones being highlighted. Moreover,based on the different data characteristics that exist in industrial systems, the corresponding fault prognosis methodologies are illustrated, with emphasis on analyses and comparisons of different prognosis methods. Finally, we reveal the current research trends and look forward to the future challenges in this field. This review is expected to serve as a tutorial and source of references for fault prognosis researchers.
I. Introduction
WITH the rapid development of information collection and industrial automation technologies, the industrial system of modern society has made considerable progresses and become more and more elaborate. With the increase in the components of the industrial system, the interactions between them have become more and more frequent and complex,which makes the occurrence probability of functional failure greatly increased [1]–[4]. And these characteristics are particularly prominent in modern industries. Against this background, fault detection and diagnosis are increasingly important for safety-critical industrial systems. However, simply detecting and diagnosing a fault may be insufficient in some cases, since some critical functions of the system have already been destroyed before the fault occurs. Hence, it is necessary to prognose the fault ahead of time so as to provide the predictive maintenance measures and repair schedules.
Specifically, fault prognosis is equivalent to establishing the long-term (multi-step) predictions regarding the evolution in time of a particular interested fault signal (indicator) [5]. The concept of fault prognosis is firstly put forward by researchers when analyzing the automated maintenance system for vessels. Since then, fault prognosis has attracted great attention from both the scientific and industrial communities,and many related research works have been proposed[6]–[10]. The objective of fault prognosis is to determine whether a failure is impending and estimate how soon and how likely a failure will occur, aiming to prevent system degradation, catastrophic failures, ensure the long-term stable operation of the industrial enterprises, and ultimately result in the end of life (EOL) or remaining useful life (RUL) of the faulty component or subsystems [11].
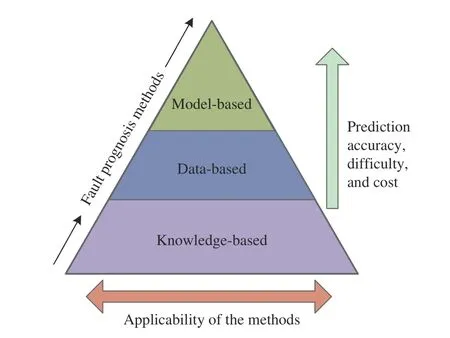
Fig. 1. Taxonomy of different prognosis methods.
As per literature, current fault prognosis methods can be generally classified as three types: model-based methods,knowledge-based methods and data-based methods (see Fig. 1).Concretely, model-based methods are approaches that build accurate mathematical description of systems using physics or first-principle. The identification and update of the model parameters generally require specifically designed experiments and statistical methods, respectively. As a result, they tend to outperform other kinds of models when sufficiently knowledge of physical mechanisms are available. However, as industrial systems become more and more complex, to exact mathematical knowledge about the system is generally unavailable. Additionally, model-based methods are often built case by case. Hence, it is not conducive to apply them to other systems.
On the other hand, knowledge-based methods are based on engineering experience and historical events, the prognosis results obtained by these methods are more intuitive. Hence, it is easy to carry out and efficient when the process models can be easily obtained or the process knowledge has been readily accumulated. However, the formation of the process knowledge is always time consuming, and knowledge-based models rely too much on the capability of the expert experience and sometime it is even impossible to build such models due to the combinational explosion problem, thus the prediction accuracy is greatly reduced and application scope is largely limited.
Apart from the aforementioned two types of prognosis methods, the data-based method mainly determines the health status of the system within a certain period of time by analyzing the previously observed data [12]. Because they do not require the professional knowledge or mathematical models of industrial systems, the data-based methods are applicable when data is sufficiently abundant and have relatively low operating cost. With the development of modern information and digital technology, the collection of large amounts of system measurement data provides the basis for data-driven fault prognosis applications with higher prediction accuracy, widely promoted in the past decades.Even if the enough observation data is not always available in some actual working environment, several specific datadriven methods can produce accurate prognosis results with few training samples [13] or lacked experimental samples[14]. Therefore, this paper focuses on data-driven fault prognosis methods, which mainly include but are not limited to machine learning algorithm, statistical pattern recognition based methods, and artificial intelligence models.
Notably, some traditional data-driven prognosis methods,such as principal component analysis (PCA) and partial leastsquares (PLS) have inherent limitations. They often assume that the industrial systems to be linear, Gaussian or operated under stationary conditions. However, most of these assumptions are hard to be satisfied in practice. Therefore, in past years, various improved versions of the general databased prognosis methods have been proposed, such as independent component analysis (ICA), Gaussian mixture models (GMMs) and so on. To the best of our knowledge,though the research about fault prognosis has progressed to an exceptionally high standard, no comprehensive review has been proposed on recently developed data-based fault prognosis methods for industrial systems until now. The motivation of this survey paper is to provide such an overview for data-based fault prognosis methods.
The remaining parts of this paper are organized as follows.The fault prognosis methods for different systems are introduced in Section II. Section III shows the detailed implementation procedures of the typical data-driven fault prognosis method. A systematical review of the state of the art data-based methods for different industrial systems fault prognosis is given in Section IV. Section V is used to look forward the future perspectives and challenge of fault prognosis under the gradually complicated industrial system.Finally, Section VI concludes the paper.
II. Industrial System and Its Characteristics
In this part, two typical industrial systems are briefly described, and the main data characteristics of these systems are also introduced.
A. Continuous System
Industrial systems can generally be divided into two primary subcategories, continuous system and discrete system. As depicted in Fig. 2, continuous systems mainly involve steel,chemical, petroleum and so on. As its name implies, the continuous system operates around the optimal state most of the time and produces constant outputs after the process has been started. It is noteworthy that most studies focus on continuous process in the early stage of data-driven fault prognosis.
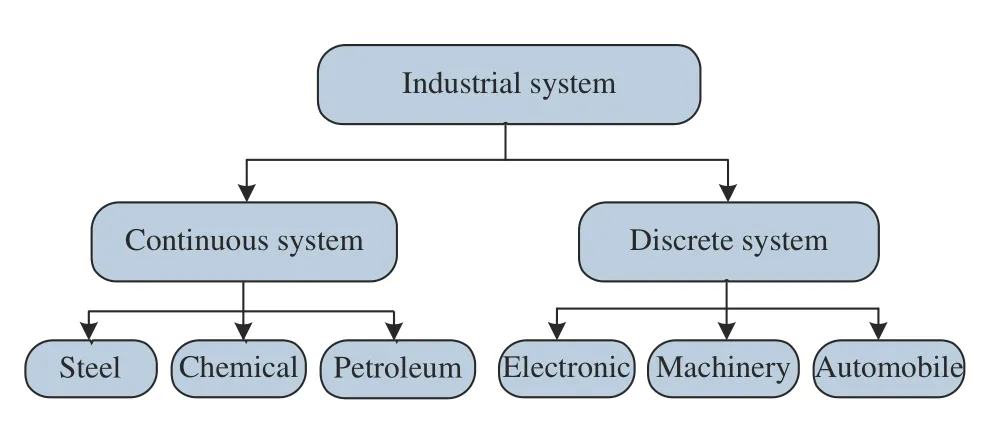
Fig. 2. Typical kinds of industry systems.
B. Discrete System
In contrast, the discrete systems usually have finite operation durations and the production strictly follows the process specifications. In addition, the set point of this system always changes, which means the system is often operated under different process conditions. Hence, the discrete system is generally more complicated than the continuous system. In practice, electronic, machinery and automobile and many other systems belong to this type.
C. Characteristics
With the increase of production links, more frequent interactions arise between various subcomponents. The data of modern industrial systems mainly has the following characteristics [15]–[18]: 1) dynamic behaviors, 2) nonlinear relationships, 3) non-Gaussian distribution, 4) time-varying multimodality, 5) non-stationary. And the detailed description of these characteristics are shown in Section IV, followed by the review of existing fault prognosis methods for the corresponding industrial systems.
III. Data-Based Fault Prognosis Procedures
In this section, the detailed implementation procedures of a typical data-driven fault prognosis method are divided into four layers, which are shown in Fig. 3 , including data collection and analysis layer, feature extraction and selection layer, model selection, training and validation layer, fault prognosis and health management layer. The detailed illustrations of every layer are given as follows.
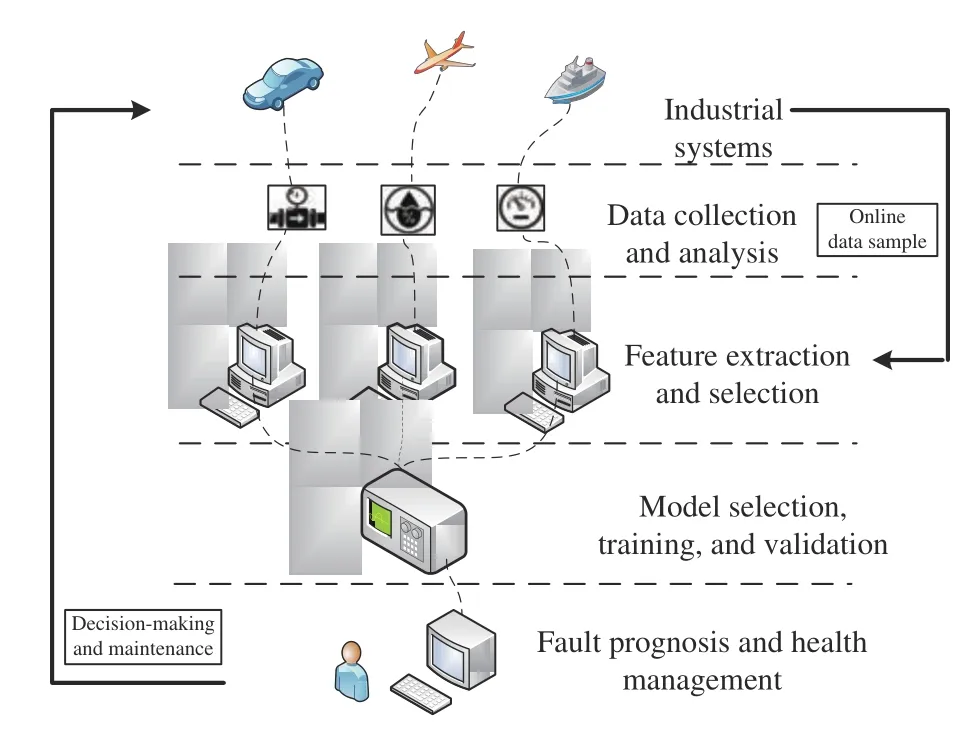
Fig. 3. The typical function structure for data-driven fault prognosis system.
A. Data Collection and Analysis
The data collection and analysis layer is the basis and data sources of the data-based fault prognosis methodology.Generally, in this layer, the original measurement data is collected, then the data characteristics are analyzed and the most appropriate measurement datasets (generally the data under stationary state is collected for continuous system and the data under most representative process conditions is collected for discrete system) are provided for modeling and evaluation. Since the following layers are all based on this layer, it is an important step for data-based fault prognosis. In other words, if an appropriate measured data has been selected for model construction that can well describe the operating conditions of current industrial systems, the satisfactory prognosis results can be guaranteed and vice versa.
B. Feature Extraction and Selection
The feature extraction and selection can be regarded as the preprocessing step for measurement data of data-driven fault prognosis [19]–[22]. It is obviously that not every measurement variable is directly related to the underlying fault. Feature extraction and selection technique can extract the conducive information for fault detection and prognosis from the massive original data [23]. Therefore, it will not only improve prognosis accuracy, but also reduce computational complexity [24]. With the increasing of system complexity and data volume, feature extraction is gradually becoming an indispensable part in dealing with fault prognosis problems for complex industrial systems and achieves great success. In this part, we summarize the commonly used methods in regard of fault prognosis. These techniques can be roughly classified as statistical methods (PCA [25], ICA [26], PLS [27], FDA [28],subspace-aided monitoring [29]) and engineering knowledge based methods (Fourier transform [30], wavelet analysis [31]).A comparison of these feature extraction algorithms can be found in Table I.
Although the above standard methods have various limitations, they still find good applications in many industrial systems. In recent years, in order to meet the increasing requirements for fault prognosis, various improved algorithms have been proposed to improve the effect of feature extraction and selection. Specifically, the dynamic principal component analysis (DPCA) [32] can describe process monitoring parameters with autocorrelation and cross-correlation properties. Multiblock PCA [33] and multiblock partial least squares (MPLS) [34] are multiblock analysis algorithms for plant-wide process feature extraction, a survey on wavelet analysis in machine fault feature extraction can be found in[35]. Since the above methods are not the main goal pursued here, the detailed introduction and analysis of them are omitted here. Furthermore, there is no conclusive evidence that a single method outperforms all others in all situations, so we should choose the appropriate one according to the data characteristics in the actual fault prognosis situation.
C. Model Selection, Training, and Validation
Following the features extraction and the analysis results of process data characteristics, the intelligent prognosis model is then applied and the complexity is also evaluated, e.g., which kind of model can be chosen to model, what is the model structure and parameters should be. For example, if the data relationship is non-Gaussian distributed, we can simply select the ICA model to realize fault prognosis. If the process has dynamic characteristics, the dynamic signal processing approach can be employed, such as wavelet analysis and DPCA.
Since the prognosis model is considered to be the driving force for data-driven fault prognosis, choosing the most suitable model is of significant importance. However, there is no unified standard or pattern for model selection till now.Alternatively, the model selection can be realized by a special way or experience.
Once a certain model is determined, the process data based model efficiency assessment can be carried out. Therefore, the process data is often divided into two parts: the training dataset, which is used to evaluate the model performance, and the testing dataset, which is applied to put the model for online utilization. Nevertheless, in some particular cases, the industrial process cannot provide sufficient process data,especially the fault data for model training and testing. In this case, it is necessary to use the cross-validation technique or turn to some resampling methods (boosting and bagging) to make full use of the existing data.
D. Fault Prognosis and Health Management
According to the comprehensive analysis of the above methods, the fault prognosis mainly aims at potential and future fault [36], which means the research object of fault prognosis is the future uncertainty event [37]. That is, the health status over the next period of time is determined by the variation trend analysis for the measurement data. Fig. 4 is the description of implementation process of the fault prognosismethod and time periods for the development of the fault. If a good solution is given in the stage of the incipient fault, it is possible to eliminate the hidden trouble of the accident to avoid the occurrence of the disastrous fault.

TABLE I Comparison of Commonly Used Feature Extraction Algorithms
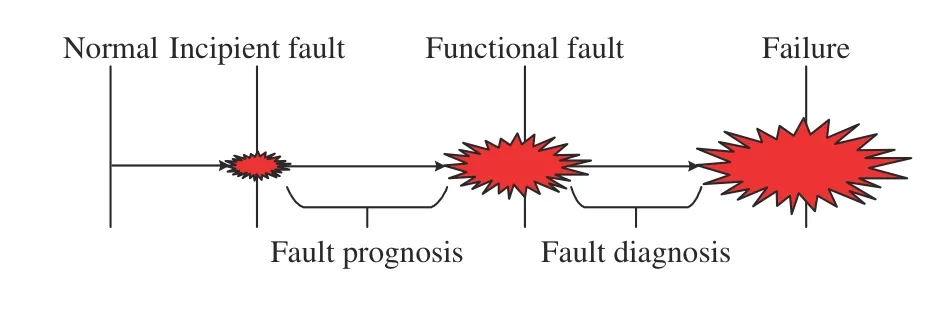
Fig. 4. The relationship between fault prognosis and fault diagnosis.
Since fault prediction is far less developed than fault diagnosis, early development of fault prognosis was once regarded as a complement to fault diagnosis. In fact, the research objects of fault prognosis and fault diagnosis are the faults in different time periods [38]. Specifically, fault prognosis aims at potential faults, i.e., the generated faults in systems, subsystems or components are predicted, and then the residual life is estimated. Fault diagnosis is to determine the fault before the occurrence of secondary damage or catastrophic failure of system, subsystem or component. The relationship between fault prognosis and fault diagnosis [39]is briefly described in Fig. 4. What is more, the difference between fault prognosis and fault diagnosis lies in their purposes rather than their implementation procedures [40].
RUL estimation is another mainstream idea of fault prognosis, which is used to determine future health status by analyzing the performance degradation trends of industrial systems [41]. Compared with the incipient fault diagnosis, this method can determine the system fault condition more accurately, then the staff can specify a maintenance plan based on the predicted health status, which means that the RUL estimation method can be considered as the core of the condition-based maintenance (CBM) implementation [42].With the improvement of system stability requirements and the development of various intelligent algorithms, we firmly believe that RUL estimation will become an important research direction in near future.
IV. Review of Data-Driven Fault Prognosis
Industrial systems often have complex structural principles and operating conditions, which will result in multifarious data characteristics for their measurement variables. It is of great significance to propose appropriate methods for these different data characteristics in industrial systems to improve the accuracy of fault prognosis. This section will summarize and analyze the fault prognosis methods from the view point of different data characteristics.
A. Dynamic System Fault Prognosis
1)Problem Statement:Temporal continuation of different sampling points widely exists due to the intrinsic feedback control systems, which makes the dynamic data characteristics very common in industrial systems. The dynamic characteristics of the system are mainly manifested by the autocorrelation and crosscorrelation properties between different sampling points of the measurement variables. And for different industrial systems, the dynamic steps differ from one another [43]. Nevertheless, most existing data-driven fault prognosis methods neglect the dynamic characteristics or describe it just by increasing the sampling interval. As a result,these methods will cause the loss of partial dynamic fault information and increase of noise effect, thus reducing the fault prognosis performance. Hence, various dynamic fault prognosis schemes are proposed recently, which are introduced as follows.
2)State Estimation Methods:It is believed that the current state of the system is only related to one or a few of the previous state parameters, which means the future health status can be determined by estimating the previous state parameters. The state estimation is a very common method in predicting the health status of a system using dynamic characteristics of measurement variables. Generally, this method does not directly predict the health status, but estimates the state variables to determine the performance degradation trend of current systems. As a common state estimation method, hidden Markov model (HMM) has been widely used in fault prognosis and a novel method for employing hidden Markov models is proposed in [44]. The proposed methods are validated on a vertical drilling machine and the physical test-bed, both of them show promising diagnosis and prognose results. Similarly, other HMM-based fault prognosis methods for dynamic system can be found in[45]. It is worth noting that how to identify key or part of parameters of industrial systems is also crucial [46], [47].
Besides, the filter method is another classical state estimation based one, which assumes that the state variables of the next moment are directly related to the state variables of the current time, and the health status of the system can be obtained by the constructed relationship between the health parameter and the system state variables. Xuet al. [48]proposed a method for system fault estimation and prediction using a modified particle filtering and exponential smoothing,respectively. Finally, the Monte Carlo simulation was used to calculate the system predictive reliability. Cosmeet al. [49]proposed a new fault prognosis by incorporating fuzzy system into the interacting multiple model filter to model the dynamics of system. The prognosis results showed better performance in both numerical example and experimental PRONOSTIA platform.
3)Regression Analysis Methods:The regression analysis method is mainly used to determine the quantitative relationship between variables, which can be used to model the data relationship between different sampling points. The autoregressive is a simple method to model the autocorrelation data change process. However, this method is less efficient than directly predicting the evolution process of measurement variables. It is used to model the degradation process of fault factors after feature extraction in the current fault prognosis process. Liet al. [50] proposed a fault prognosis method based on fault reconstruction. The vector AR method and wavelet denoising method are used to predict the degradation process of extracted fault factors, the RUL of the continuous process can be estimated. Zhaoet al. [51] firstly used a combined relative analysis to extract critical fault effects, then a vector auto-regression model is developed to realize fault prognosis. Recently, Wanget al. [10] proposed a hybrid algorithm that combines the iterative dynamic least squaresupport vector regression method and moving window mechanism to achieve fault prognosis for dynamic systems,which received a good multi-step prediction result upon the traction motors of CRH trains.
4)Dynamic Statistical Methods:The dynamic statistical prognosis method is a kind of advanced ones, which can be used to cope with the ubiquitous dynamic behaviors in the measurement data. For example, the DPCA [52] is an improved method of PCA, which will make it possible to deal with dynamic data. Jiaet al. [53] propose a new dynamic kernel partial least squares (DKPLS) method for fault prognosis. The measurement data is decomposed by DKPLS to extract the variables that are fault-related, and the forgetting factor is introduced to assign weights to the collected data samples. Then the health status of industrial systems can be determined according to the corresponding process monitoring and quality prediction methods proposed. In addition, the similar fault prognosis methods using dynamic prognostic can also be found in [32] and [54].
5)Dynamic Neural Networks(DNN)Methods:During the past years, neural networks (NN) has been proven to be a powerful tool for prognosis [55], [56]. In order to improve the efficiency of processing dynamic data by NN, a sequential fuzzy clustering dynamic based fuzzy NN method is proposed in [57]. This method is capable of learning the model sequentially and adapting itself to variations, thus providing accurate estimate or prediction on the status of the dynamic process. Other kinds of dynamic NN, such as dynamic wavelet neural networks [58] and dynamic Elman neural networks [59]are also proposed and applied to fault prognosis.
6)Discussions:In recent years, lots of advanced methods have been proposed for dynamic system fault prognosis.Among them, the DPCA and DPLS are the simplest ones to carry out. However, the dynamic step of the augmented matrix is always difficult to confirm, which can seriously affect the prognosis results. And it is still worthy of studying in the future despite the existing methods for dynamic step calculation. In contrast, the state estimation methods can consider both the autocorrelations and cross-correlations of different variables, which are quite powerful in disposing the complex dynamic characteristics among different variables.The regression analysis method depends on the relationship between variables and may show worse performance than directly predicting the evolution process of measurement variables. It is noteworthy that both the regression analysis method and state estimation method can be incorporated with dynamic statistical methods or DNN methods for enhanced results in special dynamic industrial systems. And the detailed advantages and disadvantages of different dynamic process prognosis methods are shown in Table II.
B. Nonlinear System Fault Prognosis
1)Problem Statement:Generally, nonlinearity generally stems from linear characteristics or linear equations of the system’s dynamics [60], and nonlinear systems are systems whose behaviours are within the control of nonlinear differential equations. Hence, it is more difficult to prognose the fault in nonlinear system than that of linear system. Due to the increasing complexity of the industrial system structure,the nonlinearity between different measurement variables is more and more common in many modern industrial systems.However, most of existing linear methods usually assume that the systems are linear, which is obviously not conducive to the realization of high-precision fault prognosis for nonlinear system. In order to improve the prognosis performance for the nonlinear industrial system, significant research works have been proposed in the past years, detailed analyses of which are shown in this subsection.
2)Kernel-Based Methods:The kernel-based method is widely used in processing nonlinear objects. Its main principle is to establish a map between the original monitoring space and the high-dimensional kernel space with a specific kernel function, which can extend the existing linear applicable methods to the nonlinear situation. The common kernel methods mainly include the kernel PCA (KPCA) method in which the kernel function is incorporated into the PCA model.Recently, Xuet al. [61] used the local KPCA (LKPCA) method to prognose the incipient faults, which showed better fault prognosis performance than the other traditional methods. Liuet al. [62] combined the support vector regression (SVR)method with various kernel functions to realize fault prognosis for nonlinear systems. The simulation results upon the Tennessee Eastman process show that the newly raised method acquired a better result than the single SVR method. Other kernel-based methods designed for fault prognosis of nonlinear system can also be found in [63] and [64].

TABLE II Comparisons of the Fault Prognosis Methods for Dynamic Process
3)Particle Filtering Methods:Particle filters (PF) are usually regarded as the sequential Monte Carlo (SMC)methods using a statistical method called Bayesian inference,the first implementation of this technique was by Gordonet al. [65], then a particle filtering-based framework for fault diagnosis and failure prognosis in complex nonlinear systems was systematically introduced in [66], followed by a particle filtering method for state-of-charge prognosis in lithium-ion batteries [67]. Jinet al. [68] established a nonlinear model to track the degradation process of the bearing, and the extended Kalman filter is used to realize RUL prediction and shows better results than the contrasted methods. Recently, Chenet al. [69] established a novel integrated framework based on PF and the least squares support vector regression (LSSVR)for the nonlinear system failure prognosis and received much higher prediction accuracy in three-vessel water tank systems.
4)Artificial Neural Networks Methods:Artificial neural networks (ANNs), also identified as the representative nonlinear information processors, have input layer, output layer and the hidden layer, which have been widely used in fault prognosis for nonlinear systems. Darooghehet al. [70]used a combined method based on NN and PF, and the proposed hybrid methodology showed superior performance in predicting the fault of gas turbine engine. Authors of [71]showed a systematic review prognostic modelling options mainly including knowledge-based, statistical methods, ANNs and so on for RUL estimation. And Mandicet al. [72]introduced the structure, learning algorithm and stability of neural network in context of fault prediction.
5)Discussions:Though the aforementioned nonlinear methods have received great attention and have been widely used to fault prognosis recently, the linear ones are still very important in the cases that have fix set of conditions with limited variation about these conditions. This is the reason why the linear prognosis approaches such as PLS and regression analysis are still widely used nowadays.Nevertheless, with the significant growing of complexity and automation degree of modern industrial systems, this part mainly introduced some other nonlinear methods, which show great advantages for fault prognosis in complex nonlinear industrial systems.
As a typical nonlinear modeling method, NN often needs some parameters beforehand, such as the number of network nodes, network layer, learning rate and so on. Hence, this kind of method is troublesome in particular industrial processes.Similarly, the kernel-based methods also need to choose the appropriate kernel functions and set the corresponding kernel parameters. Compared with NN models and kernel-based methods, the particle filtering methods seem much more straightforward. And the detailed advantages and disadvantages of different nonlinear process prognosis methods are shown in Table III.
C. Non-Gaussian System Fault Prognosis
1)Problem Statement:The non-Gaussian characteristic means that the measurement data does not conform to the Gaussian distribution and fluctuates within a certain range under certain operation conditions. However, most existing fault prognosis methods assume that process variables are Gaussian, which can be easily violated in practical industrial systems due to the existence of various environmental factors and signal generation mechanism, hence, the general Gaussian distribution based methods may show poor performance. In order to guarantee the prediction results of non-Gaussian data with higher precision, lots of advanced approaches have been set up in the past years. This subsection provides a detailed introduction of the existing fault prognosis methods for non-Gaussian industrial systems.
2)Independent Component Analysis(ICA):ICA is a popular method to search the independent latent components in the process measurement data, with a higher order statistics information, hence, it can dig more information from the non-Gaussian distribution data than other methods. [73] developed a new multivariate fault prognosis framework for non-Gaussian faulty data with a hidden fault process based on ICA, which is more efficient than traditional methods regarding fault prognosis in the flue gas turbine. Maet al. [74]used the kernel independent components analysis (KICA) to deal with both non-Gaussian and nonlinear features of process data to realize fault prediction which had been successfully applied to Tennessee Eastman process. Besides, Geet al. [75]combined ICA and Bayesian estimation for multivariate quality prediction, which can achieve satisfactory fault prognosis for non-Gaussian systems and has been verified in two case studies.
3)Gaussian Mixture Models:Another popular method for non-Gaussian system prognosis is the Gaussian mixture model(GMM), which assumes that the process data in the complex industrial system can be described by some local linear models. Wanget al. [76] developed the GMM monitor,diagnosing and forecasting the faults automatically, which also keeps the reliability and safety of complex systems. Raiet al. [77] proposed a GMM based HI, which maintained its monotonicity as the bearing condition deteriorates and the simulation experiment showed that the proposed method achieved better results for RUL estimation of bearings.

TABLE III Comparisons of the Fault Prognosis Methods for Nonlinear System
4)Discussions:Notably, though a lot of different types of non-Gaussian methods have been developed for fault prognosis, the Gaussian methods still play an important role in both industrial and academics fields due to the certain production with fixed conditions and limited variation.Nevertheless, since the level of modern industries has risen rapidly, miscellaneous data and complicated interactions and the non-Gaussian properties may be more common. Hence, it is necessary to develop new non-Gaussian modeling methods for better prognosis performances.
In addition, although these two approaches seem irrelevant,they are in fact closely related. If there are a mass of process variables for modeling, the GMM can be combined with ICA to realize dimensionality reduction for the variables, so it is much easier to construct the GMM model. Based on the above analysis, we know that ICA and GMM are the two most widely used methods for the non-Gaussian process prognosis.And the detailed advantages and disadvantages of the two different methods are shown in Table IV.
D. Time-Varying and Multimode System Fault Prognosis
1)Problem Statement: Time-varying multimode has attracted the attention of scholars recently. Existing fault prognosis methods generally assume that the degradation occurs under a single fault with a single mode, which means the fault evolution process is relatively stable. However, the operation condition may vary from time to time in practice,and it is obviously unreasonable to assume the operation condition under a single mode. The occurrence of a fault is likely to cause one or more other faults. Meanwhile, there is still some randomness while these concurrent faults occur. In addition, due to the different fault mechanisms, the fault factors generally have their own characteristics, that is, the fault evolution process is not constant. Therefore, the stable fault prognosis methods are not practicable in modern industrial systems, and the methods that can handle timevarying and multimode problems are badly in need. This subsection summarizes and classifies the current methods for time-varying multimode industrial systems, the details are shown as follows.
2)Multimodel Methods: The multi-model methods are commonly used to deal with fault prognosis problems based on the known fault modes, and lots of multimodel methods have been established for fault prognosis. Wenet al. [78]proposed a flexible Bayesian multiple-phase model based method to describe degradation process for prognosis, and the effectiveness of the new approach is verified in both the numerical example and real case. A fixed model is generally not able to achieve accurately prediction for the degradation process under multiple fault modes. Therefore, establishing prediction models for different degradation models becomes the simple and effective method. Verbertet al. [79] took the mode change in fault evolution process into consideration, and proposed a multivariate multi-model method to achieve reliability prediction. The simulation results confirm that the multi-model method is superior to the single-model method in respect to prediction accuracy when there are multiple degradation modes. Limet al. [80] used Bayesian estimation to infer the probable degradation process from multiple models. The switching Kalman filter (SKF) is used to implement model estimation and RUL prediction, which can better represent the changing degradation path. Recently, the authors of [81] reviewed four technical processes of machinery health prognostics and also showed some related multimodel methods for fault prognosis and RUL prediction.
3)Adaptive Methods: When the systems are slow-varying,the adaptive and recursive methods are generally suitable for the implementation of fault prognosis. It can determine model parameters based on the fault modes and the analysis of specific degradation processes. Dayalet al. [82] developed a recursive exponentially weighted PLS approach for state prediction and adaptive control in industrial systems.Therefore, this method is suitable for fault prognosis with uncertain fault mode change process, and ensures the fault degradation prediction accuracy in different modes by updating the prediction model. Prakashet al. [83] proposed an adaptive RUL prediction method for the dynamic systems with unknown degradation modes. The RULs are regularly updated through the adaptive degradation technique and the effectiveness of the method is demonstrated on a multicomponent electrical system. Wenet al. [84] used two phases(i.e., offline phase and online phase) to achieve multimode fault prognosis. The offline phase estimates the model of each unit and determines the unit that failed, and the online phase updates the prediction model with the collected measurement data and determines the health status of the system. And theeffectiveness is demonstrated through simulation and real case studies.

TABLE IV Comparisons of the Fault Prognosis Methods for Non-Gaussian System
4)Isolation Estimation Method: The isolation estimation method is able to realize fault prognosis for multiple faults simultaneously. This method often requires to establish corresponding degradation models for each possible fault [85]offline. Each of the currently existing faults can be separately predicted to determine the current health state in the actual fault prognosis process. Yuet al. [86] believed that it was impossible to completely detect all faults in the system only based on one observation of the abnormal behaviors.Therefore, a new fault prognosis method for implementing multi-fault mode is proposed, which is applied to determine all the faults using multiple fault detection methods. The hybrid differential evolution algorithm is used to estimate the degradation behavior of each faulty component and determine the health status of industrial systems. Ragabet al. [87] used the local data learning method to analyze and establish model for each fault respectively, and analysed the interaction coefficients between different faults to achieve fault prognosis under multiple fault modes. The simulation results show that the novel methodology has a stable prediction performance in the presence of multiple failure modes.
5)Discussions: In this part, we mainly want to emphasize the multimode character, which is also closely related to time.Hence, the fault prognoses for time-varying and multimode system and the dynamic system are analyzed respectively in this paper. From the analysis and research of the above subsection, generally speaking, the multimodel methods and isolation estimation methods mainly realize the fault prognosis for multimode industrial process, which has some stable operation states and switches from one to another. In contrast, the adaptive methods, such as adaptive PCA/PLS,are mainly applied to time-varying process prognosis whose operation condition changes from time to time, frequently. For the isolation estimation prognosis method, it may handle both the multimode and the time-varying objects, so long as the possible faults are correctly separated from each other. And the detailed advantages and disadvantages of those different methods are shown in Table V.
E. Non-Stationary System Fault Prognosis
1)Problem Statement:As we all know, process variables of industrial systems are impossible to keep stationary all the time in reality and some of them may follow non-stationary distributions. Different from the stationary process, nonstationary systems are always more complicated. Especially,the non-stationarity may exist in both the linear and nonlinear systems in the form of time variations when describing the systems, which is often modelled by continuous time stochastic models. And the non-stationary property is usually caused by the variance fluctuations of the process as well as a smoothly varying trend component with shifts in the mean of the process [88]. Hence, when the process data is nonstationary, the prognosis results obtained by the stationary based methods are not reliable. To improve the prognosis accuracy of the non-stationary systems, some kinds of advanced methods have been proposed in the past years, and the detailed analyses of them are given as below.
2)Match Matrix Method:The match matrix (MM) method is firstly proposed by Liuet al. [89]. The MM based method proposed in the paper is able to achieve high long-term prediction accuracy through comparing signatures from any two degradation processes. Based on this, the new method obtained the noticeable improvement of long-term prediction accuracy in regard to mean prediction errors over other competitors. Recently, [90] proposed a systematic review to design a PHM system and select proper tools, which has provided a tutorial and source of references for fault prognosis researchers. Besides, the paper also showed that the MM method is feasible for non-stationary processes.
3)Hidden Markov Model:HMM is a statistical method based on the principle of Markov chains for describing the signals by a limited number of states. It has also been proven to be efficient in widespread applications [91]. As for the fault prognosis based on HMM, there are also a lot of publications.For example, Donget al. [92] proposed the hidden semi-Markov model (HSMM) based on the standard HMM to prognose the health status of a component, which has been verified in real world applications. Furthermore, the authors of[93] developed the hybrid approach based on HMM and grey model, in which HMM is used to model the time duration of the hidden states and the grey model is carried out to compute the expected residual life (ERL). In the works of [94], a novel online health prognostic method based on HSMM and sequential Monte Carlo (SMC) is provided to estimate the RUL values of equipment by Liuet al. And the superior performance of this method is demonstrated by a real case study.
4)Support Vector Machine:Support vector machines(SVM) is a popular machine learning algorithm, which is often used to find an optimal separating hyperplane with the maximum distance between the plane and the nearest data[95] and it is first used to realize pattern recognition.However, the fault prognosis by SVM also received widely attention. Chenet al. [14] set up the novel prognostics model based on multivariable SVM and relative features to predict the RUL of rolling bearing with small samples directly. Andthe results on run-to-failure and simulation experiments validated the novel model is practical for the fault prognosis.The authors of [96] showed a literature review about SVM based RUL estimation in the past decades. The paper mainly introduced different SVM algorithms and their applications to fault prognosis, and also outlooked the future research direction for RUL estimation by SVM-based methods.

TABLE V Comparisons of the Fault Prognosis Methods for Time-Varying Multimode System
5)Sequential Monte Carlo:SMC is usually referred to a representative particle filter method, which was first proposed by Gordonet al. [65] for recursive Bayesian filters. They termed the technique as bootstrap filter, known by others as the sampling importance resampling (SIR) filter. Using the SIR filter, the number of samples required to approximate the future state probability distributions can be significantly reduced and hence, the computation can be more efficient.Point mass, or particles, representing probability densities can be applied to any state-space model [97]. The particles contain information of unknown parameters, which are estimated and updated as a form of the probability density function (PDF) in the Bayesian update process using observations [98]. This powerful sampling-based inference algorithm for dynamic Bayesian networks is feasible for any kind of probability distribution, non-linearity and non-stationarity [99] and shows satisfactory fault prediction results.
6)Gaussian Process Regression:The Gaussian process regression (GPR) is one of the applications of GPs. The prediction output is a Gaussian probability distribution and is expressed by its mean and variance. Variance is the measure of confidence in the predicted mean value of the output [100].GPR needs a prior knowledge of the form of covariance function [101]. Selection of covariance function must be carried out by users, but corresponding hyperparameters can be learnt from the training data using a gradient based optimizer such as maximizing the marginal likelihood of the observed data with respect to hyperparameters. Although stationarity is assumed when specifying a GP prior, several approaches for specifying nonstationary GP models can be adopted to make the model applicable to non-stationarity. In[102], the GPR models with three different kinds of covariance functions are discussed for feature tracking and RUL evaluation and realize a better accuracy prognosis of the bearing RUL by analyzing two important features. What is more, the authors of [103] used two common covariance functions and a composite covariance function of GPR was introduced to realize a better assessment by analyzing some important features. The experimental results showed that GPR model can achieve a high prognosis performance, and the composite covariance function can improve the prediction precision.
7)Discussions:Among all the aforementioned developed non-stationary systems fault prognosis methods, both the MM method and HMM method require sufficient training data for modeling. In contrast, the SVM method is efficient for both small and large datasets regarding real-time analysis. Note that the SMC can deal with nonlinear and non-Gaussian noise situations, as well as multivariate and non-standard posterior distributions. What is more, HMM and SMC can also perform fault prognosis and RUL estimation for dynamic and nonlinear systems as described in Sections IV-A and IV-B,respectively. And more researches are needed to make the GPR be able to process and train online data as well as handle high dimensional data. In conclusion, detailed advantages and disadvantages of non-stationary systems fault prognosis methods have been listed in Table VI.
F. Summary
After a systematic review of the data-based process prognosis methods through various practical problems, a detailed conclusion of different data-based prognosis methods and some additional instructions are given in this part.
In general, the data in industrial systems often shows multiple distribution characteristics, such as dynamic variable relationships, nonlinear data correlations, non-Gaussian data distribution and time-varying multimode characteristics.Under this background, a lot of works have been proposed for solving the above specific problem till now for both the continuous and discrete systems. Nevertheless, a predominant fault prognosis method should be able to handle the two or more data distribution characteristics in industrial processes simultaneously. In recent decades, there were already many works given to dispose multiple data characteristics of the industrial processes. Hence, though we have divided the process prognosis methods into different classes based on different industrial processes and reviewed the corresponding the prognosis methods, some of them may interweave with each other among different classes. And the systematic survey of various data-based fault prognosis methods is given in Fig. 5.
V. Research Challenges and Future Trends
The purpose of fault prognosis for industrial systems can now be regarded as achieving the CBM, which determines the maintenance plan of the system based on the predicted health status [104]. With the increased complexity of industrialsystems and the improvement of stability requirements, the data-driven fault prognosis methods may exhibit new research trends and challenges. In this part, the research challenges and future trends of data-based methods for fault prognosis are illustrated based on the context of above sections.

TABLE VI Comparisons of the Fault Prognosis Methods for Non-Stationary Systems
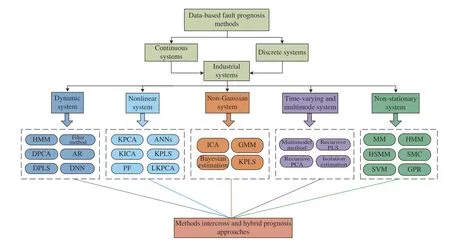
Fig. 5. Systematic view of different data-based prognosis methods.
A. Research Challenges
Though lots of research works have been carried out to date,aiming at reducing model complexity and improving the prediction accuracy and applicable ability of data-based fault prognosis methods in real-world industrial systems. Most of the prognosis techniques reviewed in this work can meet these requirements. However, there are still some research challenges that are worth continuing and in-depth study,which are listed and analysed as below.
1)Feature Extraction Techniques:With the growing of database scale and the development of data collection and storage devices, the field of fault prognosis in industrial systems is beginning to focus on big data analysis methods.What is more, with the improvement of complication and automation level for modern industrial systems, multiple measurement variables must be monitored simultaneously to ensure high-precision fault prognosis. However, not every detected variable is related to faults. The existence of a large number of measurement variables will inevitably lead to increased computational complexity and degraded model performance. As a preprocessing skill, the feature extraction method can help extract variables containing more health status information to improve the efficiency of fault prognosis. Therefore, it is gradually becoming an indispensable step in the implementation process of fault prognosis.
Another application of feature extraction is to convert measurement data into the form that facilitates health assessment. The feature extraction method owns irreplaceable effect, especially when dealing with signals that are versatile and difficult to process, such as vibration. However, due to the characteristics of this signal, it is susceptible to time-varying noise during the monitoring process, which is not conducive to accurate fault prognosis. Therefore, reducing or filtering out the effects of these noises during feature extraction may become an important research direction. Extracting multiheterogeneous information therein can achieve fault diagnosis and prognosis, which is beneficial to the reliability of industrial systems.
In summary, the function of the feature extraction method is to obtain the variables in the monitoring data that have contributed to fault analysis. However, this does not mean that simply extracting the fault-related variables will definitely improve the accuracy of fault diagnosis and prognosis [25].And in some cases, the single feature extraction algorithm of conventional multivariate statistical analysis often appear to be powerless. Improved algorithms based on system measurement data characteristics and the types of prediction model with more flexible forms may become a promising development tendency [105]–[107]. Specifically, the merit and demerit, applied ranges of feature extraction algorithm should be analyzed, the integration forms of feature extraction methods and fault prognosis model should be explicit and things like these. Therefore, we have every reason to believe that more elaborate feature extraction methods will emerge as the promising research topic in the near future.
2)Combined Prognostic Models:Recently, though various data-based fault prognosis methods have received great success, each of these approaches has certain application scope. Hence, a method working well under one process situation may not be efficient under another situation. That is to say, the effectiveness of each method mainly depends on the data characteristic of different industrial systems and there is no conclusive evidence that a certain method will prevail over all others in all cases. Specially, for the processes that have multiple operating situations, it is reasonable to combine several prognosis methods together for complementarity effects. In this case, the fault prognosis performance can be improved by taking advantages of different methods, and the weakness of each method can also be offset. In recent years,this kind of methods have received more and more attention due to their synergy properties [108]–[111].
Since the integration of different data-driven prognosis approaches introduced above is totally dependent on historical data, if the process data are not available, the practicability of the method will be greatly reduced. Even if such data can be fully saved and provided, the pure data-driven integrated approaches still suffer from some bottlenecks in complex environments, such as being unable to incorporate the expertise experience and the system mechanism knowledge.Based on this, the integration of expert knowledge and mechanism knowledge to build the hybrid prognostic models is in badly need now [112], [113]. Hence, more investigations still need to be carried out for enhanced prognosis results,especially on the model combination mechanism analysis and local performance analysis for different approaches.
3)Multi-Source Information Fusion:As far as we know, the current data-based prognosis model just incorporates the ordinary process data, such as velocity, temperature and so on.However, there are various measurement devices installed in modern industrial processes, which may bring abundant data information for fault prognosis. For example, both the color,brightness, geometric, shape feature provided by image sensors and the different sounds provided by voice sensors can be used to analyze the operating conditions, then combined with the machine learning algorithm to realize fault prognosis and state estimation.
On other hand, the above single aspect of data information may be unable to fully reflect or understand the operating conditions of the entire production process. It is necessary to combine the conventional process data with the new sensor to obtain more comprehensive operation data for the fault prognosis [114]. Hence, the multi-source information fusion method based on mechanism, process data and expert knowledge for abnormal condition prediction is worthy of study in the future, which is beneficial to realize long-term prediction with high accuracy.
4)Long-Term Fault Prognosis:Apart from the comparing the prognosis accuracy of different prognostic techniques, the prediction step is also one of the core issues regarding fault prognosis, and the fault prognosis methods can be divided into short-term prognosis and long-term prognosis according to the size of prediction step. The short-term or one-step-ahead prognosis is unable to set aside enough lead time for taking the maintenance operations. Hence, the long-term prognosis is still necessary before a prognostic system is completed,especially for the systems with the components that are difficult to produce or replace, or the faults that are easy to cause catastrophic consequence.
In addition, actual industrial systems are complex and have countless uncertainty factors that can affect the prognosis accuracy, it is not unrealistic to maintain a higher accuracy and a longer prediction step simultaneously. Generally speaking,the longer the prediction step is, the lower the prediction accuracy is, and vice versa. Hence, more efforts should be made in keeping a balance between the prediction accuracy and prediction step according the characteristics of different industrial systems and ultimately, the prognostic performance in real-world industries can be significantly improved.
5)Towards Industry 4.0:Industry 4.0 tends to improve the level of intelligence in manufacturing industry, to establish a smart factory with adaptability, resource efficiency and ergonomics, and to integrate customers and business partners in business processes and value processes [115]. Thus, the process data analysis for improving decision-making level is a key step to adapt the manufacturing policies against the around-the-clock changing economic conditions. As far as we know, product quality or process based databases have already been combined in the last few years to establish predictive models for process control, monitoring and optimization, and the common techniques include the soft sensors and inferential model [116]–[118].
With the coming of Industry 4.0 era, both the unstructured and structured data will become more and more accessible from the industry process. And from the view point of Shewhart’s theory, some special causes are unpredictable due to the systematization of variations, which is concentrated on“Systems Health”. Nevertheless, fault prognosis is strongly associated with “ Systems Health”. That is to say, fault prognosis may benefit from the disciplines, such as industrial process monitoring (IPM) and reliability and maintenance (R *M). Therefore, the various forms of interactions between them are still necessary in the arrived Industry 4.0 era.
6)Big Data Perspective:In recent years, the rise of big data has led to a great development of data-driven fault prognosis.However, it generally has the character of large amount of data and low value density. It is difficult to obtain results efficiently while processing these data directly. Meanwhile,low value density data can be considered as less complete evolution data available in the field of fault prognosis. A large amount of historical data may also adversely affect the result during the fault prognosis process. Ge [119] proposed a datadriven modeling framework to deal with the problem of plantwide faulty data analysis. After a series of feature extraction and variable selection methods, an offline model is established to process online monitoring data. The offline model can be evaluated and updated by the online process. It may become an important development direction. An offline model is established to process online measurement data after a series of feature extraction and variable selection methods. Then the offline model is evaluated and updated by the online process.The method can effectively reduce the computational complexity of online fault analysis process and is a reliable way to deal with large-scale data.
Big data created enormous challenges not only for feature extraction, but also for model evaluation. In order to reduce the false alarm rate caused by various special factors in the industrial system monitoring process, it is necessary to obtain a plurality of different measurement variables at the same time. The existence of these measurement variables can effectively expand the monitoring range of the health status.However, especially for large-scale industrial systems, these variables will inevitably impose a heavy burden on the complete fault prognosis process. A large number of monitoring variables will delay the prediction of failure even if it undergoes preprocessing. With the development of computer technology, more and more distributed technologies are being applied to deal with large-scale data problems.Distribute large amount of data across multiple servers and process simultaneously, which can speed up the calculation[120]. Similarly, a large-scale industrial system fault prognosis problem can be solved by using each server to process a monitoring data subblock [121]. However, this method has a very high cost performance, so the fault prognosis of distributed computing processing big data may become the important future research hotspot, which is still underway.
B. Future Trends
The data-driven based fault prognosis methods have been developed widely in the past decades due to the increase in the stability requirements of industrial systems. This part will illustrate the future trends of this research topic through the different databases and the details are shown as below.
1)Trends Analysis: Figs. 6 and 7 show the number of papers about data-driven fault prognosis and publications of fault prognosis applications in the light of Engineering Village database and Web of Science database, respectively. We can obtain the following two trends from this two figures. On the one hand, the research of data-driven fault prognosis technology shows a clear upward trend during 2008–2018,which proves that fault prognosis is a promising domain worthy of study. On the other hand, the engineering applications have taken up the largest proportion over the past years. That means the content of this paper is a frontier subject with theory and practical significance, and it will continue to maintain in the leading position.
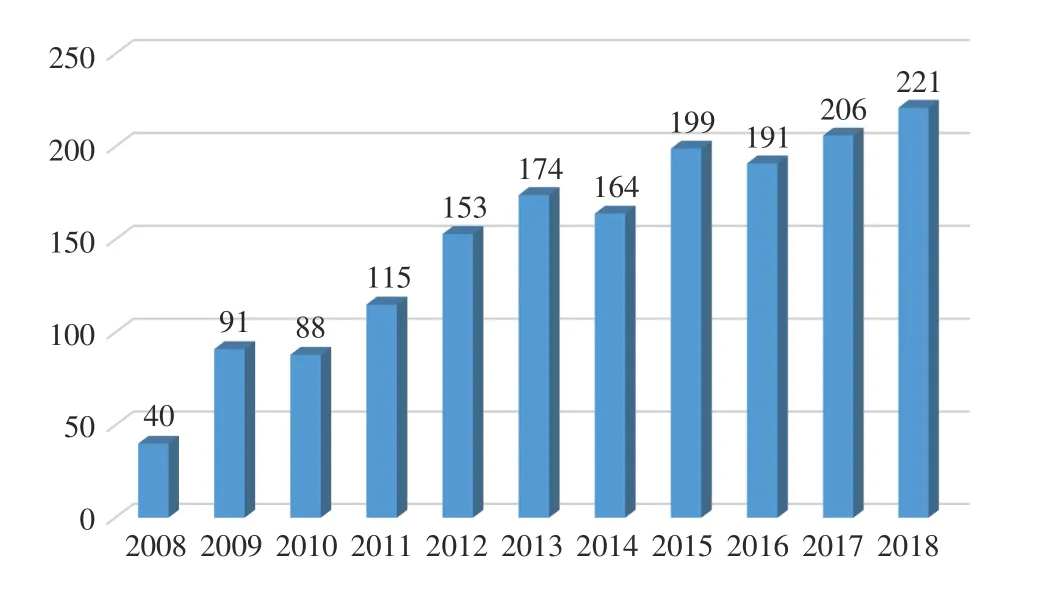
Fig. 6. The papers of fault prognosis published each year during 2008–2018.
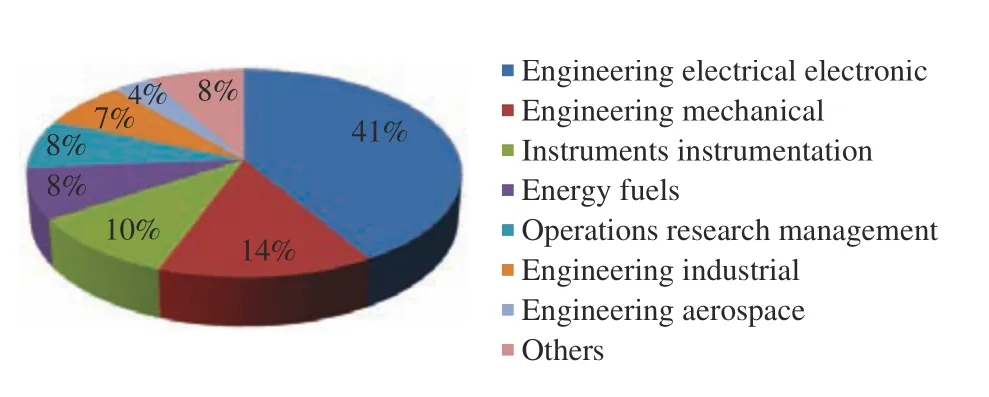
Fig. 7. Total publications of fault prognosis applications in different subject areas for the 2008–2018 period of time.
2)Trends Prediction: According to the analysis above, we have reason to believe that the data-driven fault prognosis technology will become more and more widely applied in industrial systems, and various industrial processes have begun to use this technology for intelligent maintenance since the modern industry is involving higher volume of data and more information, becoming more and more complicated.
VI. Conclusion
With the development of CBM, the data-driven fault prognosis will be one of the most important research directions. In this paper, we offer a review for the realization and development of fault prognosis. Some issues of the datadriven fault prognoses are firstly introduced, such as the common fault prognosis methods, the relationship between fault prognosis and fault diagnosis. We also summarize the current research status of data-driven fault prognoses to show their main contributions and weakness as well as the comparisons between them. What is more, this paper summarizes the research challenges that may be faced in the current industrial systems regarding fault prognosis and looks forward to the possible development directions for future researches.
We have entered the age of big data, and a large number of intelligent algorithms have been provided and the industrialization level is improved, which will put forward higher requirements for the long-term stability of industrial systems. As a consequence, the real-time maintenance strategy using historical data, specifically tailored for industrial systems deserves further and deeper explorations.We hope that this review will be useful for researchers and developers to understand the enormous perspectives,applications, challenges of the data-driven fault prognosis methods. And we believe that data-driven fault prognosis will create big evolution in industrial system maintenance in the near future.
 IEEE/CAA Journal of Automatica Sinica2020年2期
IEEE/CAA Journal of Automatica Sinica2020年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Artificial Intelligence Applications in the Development of Autonomous Vehicles: A Survey
- Review of Antiswing Control of Shipboard Cranes
- Research Progress of Parallel Control and Management
- Influence of Data Clouds Fusion From 3D Real-Time Vision System on Robotic Group Dead Reckoning in Unknown Terrain
- Effect of a Traffic Speed Based Cruise Control on an Electric Vehicle’s Performance and an Energy Consumption Model of an Electric Vehicle
- Proximity Based Automatic Data Annotation for Autonomous Driving