
Deep Reinforcement Learning Based Joint Partial Computation Offloading and Resource Allocation in Mobility-Aware MEC System
2022-08-19 08:38:48LuyaoWangGuanglinZhang
China Communications 2022年8期
Luyao Wang,Guanglin Zhang,*
1 College of Information Science and Technology,Donghua University,Shanghai 201620,China
2 Engineering Research Center of Digitized Textile and Apparel Technology,Ministry of Education,Shanghai 201620,China
Abstract: Mobile edge computing (MEC) emerges as a paradigm to free mobile devices (MDs) from increasingly dense computing workloads in 6G networks. The quality of computing experience can be greatly improved by offloading computing tasks from MDs to MEC servers. Renewable energy harvested by energy harvesting equipments(EHQs)is considered as a promising power supply for users to process and offload tasks. In this paper,we apply the uniform mobility model of MDs to derive a more realistic wireless channel model in a multi-user MEC system with batteries as EHQs to harvest and storage energy. We investigate an optimization problem of the weighted sum of delay cost and energy cost of MDs in the MEC system.We propose an effective joint partial computation offloading and resource allocation(CORA)algorithm which is based on deep reinforcement learning(DRL)to obtain the optimal scheduling without prior knowledge of task arrival, renewable energy arrival as well as channel condition. The simulation results verify the efficiency of the proposed algorithm, which undoubtedly minimizes the cost of MDs compared with other benchmarks.
Keywords: mobile edge computing; energy harvesting; device-mobility; partial computation offloading;resource allocation;deep reinforcement learning
I. INTRODUCTION
The rapid growth of network traffic has put forward higher requirements for next-generation mobile communications technologies. The future 6G communication is envisioned to support pervasive Internet of Everything(IoE)applications. With the limited computational capacity and battery power,mobile devices(MDs) are unable to provide computation-intensive and time-critical services for the applications[1]. Mobile cloud computing is considered as a new solution to provide abundant cloud resources to deal with the explosive computational demands [2][3]. With the help of mobile cloud computing, the energy consumption for processing tasks is reduced by offloading computation-urgent tasks to the remote cloud servers.While the cloud servers are generally placed far away from the MDs, which leads to significant delay and serious network congestion when offloading tasks,undermining the satisfaction of quality of service(QoS)for users.
Differently from the conventional mobile cloud computing, the concept of mobile edge computing(MEC)emerges as an encouraging solution to provide cloud-like computing capacity via wireless links [4].The MEC system provides a range of delay-sensitive as well as computation-intensive application services to MDs by deploying edge servers directly at the base stations close to the users. In this way,both communication delay and energy consumption can be greatly improved. As a result, MEC offers a better quality of computation experience by means of offloading the computational tasks to MEC servers via wireless uplink[5].
Within the framework of MEC, the computation tasks requested from MDs can be either processed locally at MDs or offloaded to MEC servers to be executed.Nevertheless,extra cost including delay and energy consumption associated with task execution occurs during the communication between the MDs and the edge server through the wireless access. The cost is generally related to the offloading decision,i.e.,the more tasks are offloaded to MEC server, the more transmission delay and energy consumption are incurred. Additionally,the scenario of multi-user multitask brings additional challenge to make decisions for the system. We need to take the problem of computing resource sharing among all MDs into consideration for the reason that the computing resource of edge server is limited,which drastically affects the offloading cost as well.Therefore,it is of great significance to jointly make offloading decision and resource allocation in MEC system to achieve sustained computation performance[6].
In addition to developing reasonable strategies to reduce energy consumption,applying energy harvesting technology to communication systems is also one of the effective methods to increase energy efficiency.As an increasingly important part of green communication systems, energy harvesting equipments (EHQs)can collect renewable energy including solar radiation,human kinetic energy,wind energy and so on from the surrounding environment [7]. By integrating energy harvesting technology into the MEC system,it is possible to weaken the dependence of MDs on the battery energy supply or traditional grid,effectively solve the problem of insufficient power supply for MEC system,and achieve satisfactory computing performance.MEC with EHQ provides new opportunities for mobile computing,while the intermittent and randomness of renewable energy also bring new challenges to its implementation.
Many works have investigated computation offloading and resource allocation in MEC system with energy harvesting devices[8–10]. Most existing studies considered a quasi-static scene, where the MDs were assumed to be stationary during the procession cycle.While the mobility of MD can largely impact the wireless channel condition between MD and edge server.This motivates us to propose mobility-aware computation offloading framework in MEC system with energy harvesting. We consider an MEC system consisted of multiple MDs with uniform mobility model,each of which is powered by a battery as an EHQ to harvest renewable energy. The partitioning of computations between MDs and MEC server is elastic,which means that the tasks arriving at the MD can be offloaded to edge server partially. Besides, a resource allocation method is required to coordinate the competition among MDs with the limited computation resource of MEC server. Accordingly, we formulate an optimization problem of minimizing the total cost of the MDs including delay cost and energy consumption in MEC system, which focuses on jointly optimizing the partial offloading decision and computation resource allocation.
Taking advantages of the Markov property of the proposed problem, we can model it as a Markov decision process(MDP),then the problem above can be solved via reinforcement learning (RL) method such as Q-learning [11][12]. However, the algorithm is impractical when the state space is too large, which leads to the curse of dimensionality [13]. Based on the above discussion, we propose a deep reinforcement learning(DRL)based joint partial offloading and resource allocation (CORA) algorithm, which combines Q-learning with deep neural network (DNN),i.e.,Deep Q-Network(DQN),using a neural network as a nonlinear approximator to represent Q function[14]. The algorithm is shown to provide better performance than other benchmarks. The contributions are summarized as follows.
1) Taking the mobility of MDs into consideration,we present a joint partial computation offloading and resource allocation problem for multi-user MEC system with EHQs, where the task arrival,user mobility,renewable energy arrival as well as channel condition are uncertain. We aim at minimizing the weighted sum of the average cost of the system including processing delay,communication delay and energy consumption.
2) We propose a DRL based algorithm named CORA to address the joint partial computation offloading and resource allocation problem. We denote a binary action for the agent, which makes it more complex when applying the DNN to approximate the Q-value in DQN method. In addition, we define an effective reward function,which demonstrates the instant cost of the system and accumulates the past information simultaneously.
3) We verify the superiority of CORA algorithm compared to other three baselines numerically.Simulation results show the effectiveness of the proposed scheme in delay and energy cost decrease with varying system parameters.Additionally,it is shown that the parallel computing mode can achieve lower cost compared with the binary computation offloading strategy.
The remainder of the paper is organized as follows.We review some related works in Section II.The system model and optimization problem formulation are presented in Section III.We discuss the proposed DRL based CORA policy in Section IV.The simulation result is illustrated in Section Section V.The conclusion is summarized in Section VI.
II. RELATED WORKS
Recently, the paradigm of MEC has drawn considerable attention in both academia and industry. A large number of methods have been investigated to exploit the attainable benefits of MEC.
Especially, some of the researchers focused on the problem of task offloading decisions in MEC network.The authors in[15,16]studied the minimization problem of the energy consumption with delay constraints.From the perspective of minimizing the cost of computation offloading scheduling,[17]proposed a game theoretical analysis and provided a polynomial complexity algorithm. The authors in[18–20]have investigated the partial offloading in MEC system. In[21],both partial and binary computation offloading modes in wireless-powered MEC Networks are discussed.
Another key point in MEC is the scheme of computation resource allocation and lots of works have been done in this area. The authors in [22, 23] have analyzed the tradeoff between energy consumption and delay cost in multi-user MEC system. For mobile edge-cloud computing networks,[24]proposed an efficient framework to improve its profitabilities, considering the two cases of whether the edge and the cloud belonged to the same entity or not. Deploying unmanned aerial vehicles(UAVs)to provide MEC service, the authors in[25] jointly optimized UAVs’position and computing resource allocation with successive convex approximation.
As a promising technology in green communication,energy harvesting offers satisfactory QoS in Internet of Things. Many works have been focused on the application of energy harvesting in wireless communication. In [26], a scheme named integrated SS-EH was proposed, which incorporated spectrum sensing and energy harvesting,taking advantage of the incoming radio-frequency power. The authors in [27] considered a two-hop energy harvesting communication network with both online and offline knowledge about the energy arrivals. A nonlinear rectifier model was adopted in [28] to elaborately model the energy harvester,analyzing the output direct current power at the information decoding receiver.
The features mentioned above have motivated lots of researchers to focus on the combination of MEC and energy harvesting in recent literature. A multiuser MEC system with energy harvesting devices was considered in [8], in which each mobile user was equipped with an energy harvesting device to supply power for the batteries.The authors in[29]studied the minimization of the transmission energy consumption for wireless power transfer at the energy transmitters with the fully controllable energy supply from wireless power transfer in MEC system. The authors in[30] have investigated partial computation offloading in MEC system with energy harvesting technologies.
As motivated,taking the uniform mobility model of MDs into consideration, we aim at the minimization of a weighted sum of delay cost and energy cost of MDs in a multi-user MEC system with energy harvesting technology. Furthermore, we apply a DRL based optimal schedule while jointly considering the partial offloading decision and allocation of computation resources.
III. SYSTEM MODEL AND PROBLEM FORMULATION
In this section, firstly, the system model of our paper is introduced. Then we formulate the total cost minimization problem in terms of delay cost and energy cost.
3.1 MEC System and Computation Model
As shown in Figure 1, we consider a MEC system of multiple MDs and a MEC server. The MEC server is considered to be a small data center with powerful computing capability,which can be accessed by MDs through the wireless channels. And the set of MDs is denoted asN?{0,1,...,N}. Note that the MDs move within a bounded cellular area with the radius ofr,while the MEC server is at the center of the cellular area. The distance between theithMD and the edge server is,which obeys the uniform mobility model with the probability density function of
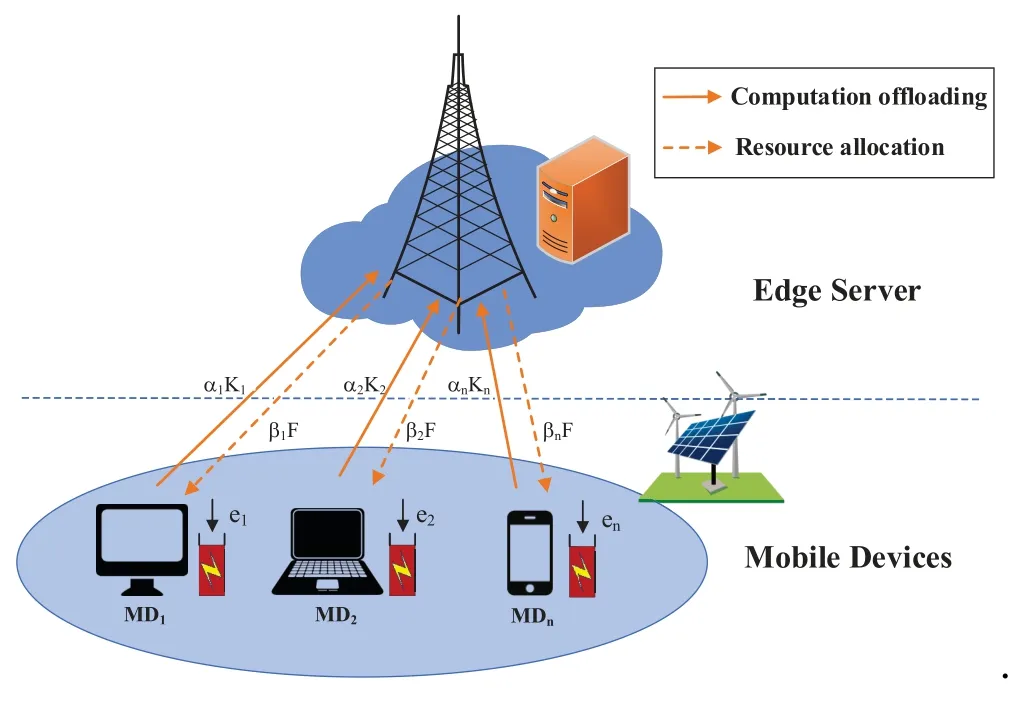
Figure 1. System model.

We assume a discrete time model which divides the procession cycle into a set ofT?{0,1,...,T}time slots. In each time slott, computation tasksrequested by the applications arrive at MDifollowing a Poisson process [32]. The arrival computation tasks can be processed either locally at MDs or partially offloading to MEC server.Generally, we assumestands for the computation input data size for task, which follows an i.i.d in[Ai,min,Ai,max]. We defineAi,minandAi,maxas the minimum and maximum computation input data size arriving at MDi,respectively.denotes the amount of required CPU cycles needed for executing the task,which is usually proportional to the size ofAnddenotes the constraint regarding the maximum delay of task. Computation offloading mainly consists of three steps: Firstly, the MDs upload data via wireless channels. Secondly, the MEC server processes the uploaded tasks with satisfying computing ability. Finally,the MDs download the computing results from MEC server. In this paper,we focus on the first two steps while ignoring the third step,for the reason that the size of workload data in the third step is much smaller than that in the first two steps[29].
We assume that the arrival tasks are generally divisible to be processed via different devices,which means the MD could offload part of the arrived workload to edge server to execute in each time slot,similar to the researches in [30, 33, 34]. We denote[0,1] as the proportion of computation tasks that MDioffloads to the edge server. Therefore, the amount of locally processed tasks is. Specifically, we have=0if all the workload is computed locally on the MDiand= 1 if MDidecides to offload all the tasks to the edge server through wireless access. We denoteas the computation offloading decision vector of all MDs.
We defineWas the total spectral bandwidth of uplink. The orthogonal frequency-division multiple access (OFDMA) is applied in the uplink for allocating each MD an orthogonal channel to avoid the interference among MDs. To simplify mathematical notation, we assume the operational frequency bandwidth is equally allocated to each MD for offloading tasks. Then according to the Shannon theorem [35],the achievable uplink data rate(in bps)for MDiis
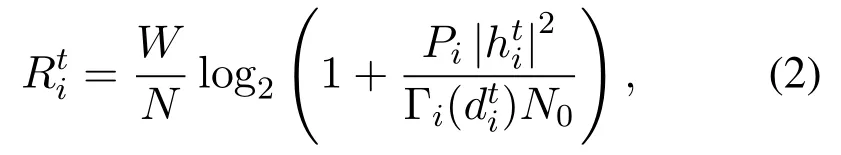
wherePiis the transmitting power of MDifor offloading tasks andN0denotes the noise power at the edge server. Taking a Rayleigh-fading model of the radio propagation between MDiand MEC server[36]into account,we defineas the square of the time-varying fading amplitudes,which follows an exponential distribution with a unity mean. Note thatrepresents the path loss obeying the free-space path loss model,wherefcandcare the carrier frequency and the speed of light, respectively,andκ ≥2 defines the path loss exponent.We assume that MEC server is endowed with the computational capability ofF(i.e.,CPU cycles/second). For the tasks offloaded to edge server,the edge server would allocate part of the computation resource to execute them. We define the resource allocation decision as[0,1]denotes the proportion of computation resource that is allocated to the offloaded tasks from MDi.
3.2 Time Delay Cost Model
The MEC system makes the decisions of resource allocation and computation offloading in each time slot.We denote the time delay cost in time slottasand model it into two parts as follows.
3.2.1 Local Execution Delay Cost
For the tasks executed locally in MDs, the time delay cost is mainly the execution delay cost due to the limited computational ability of MDs. We define the execution delay cost for MDito process tasks locally asand express it as follows:
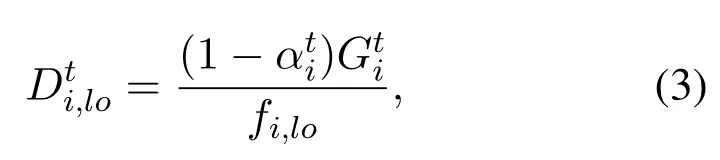
wherefi,lodenotes the computation capacity for MDi, which varies from different MDs. As can be seen,when all the workload is offloaded to edge server,i.e.,=1,the local execution delay cost of MDiis 0.
3.2.2 Offloading Delay Cost
For the workload offloaded to edge server, the time delay cost is mainly consisted of two parts: the transmission delay cost occurred when offloading tasks to edge server via the uplink,which depends on both the offloaded data size and current uplink wireless channel condition,i.e.,the achievable uplink data rate;the execution delay cost on MEC server related to the allocated computational resource and the required CPU cycles of offloaded tasks.
We define the transmission delay cost aswhich is given by

whereis the achievable uplink data rate, which is in connection with the uplink wireless channel condition and can be derived via Eq.(2). Furthermore, the execution delay cost for tasks offloaded to MEC server can be expressed as follows:
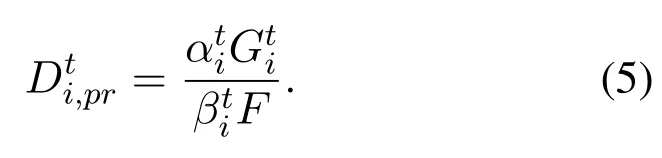
According to Eq.(4)and Eq.(5),the offloading delay cost for MDiis
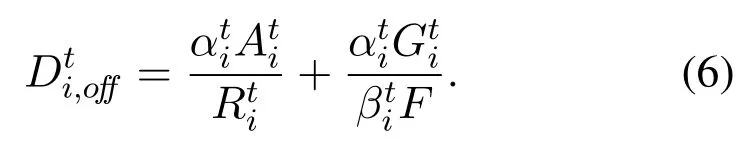
It is obvious that if all the tasks are locally processed in MDi,the offloading delay cost for MDiis 0.
Note that parallel computing is adopted in our model[18], in which the tasks can be processed in the MDs and the edge server in parallel to reduce completion delay cost. Consequently,the total delay cost of MDiequals to maximum of local delay cost and offloading delay cost,which is denoted as,as follows:
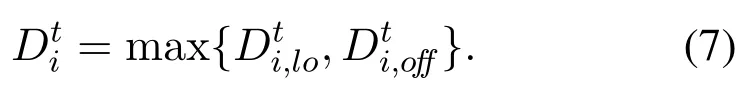
If all tasks are processed locally in MDi,the time delay cost equals to local execution delay cost. Accordingly,the time delay cost is equal to the offloading delay costif offloading all the workload to the edge server.
3.3 Energy Consumption Model
The total energy consumption of MDs consists of two parts: the local execution energy consumption and the energy consumption generated when computation is offloaded.
3.3.1 Local Execution Energy Consumption
For the tasks locally processed at MDi’s CPU, we haveas the local execution energy consumption,which can be expressed as follows:
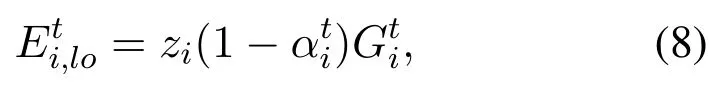
wherezistands for the unit energy consumption for per CPU cycle (joules per cycle) to accomplish the tasks locally.
3.3.2 Offloading Energy Consumption

Due to the fact that we aim at minimizing the cost of MDs in this paper and the MEC server is usually equipped with sufficient power supply,we neglect the execution energy consumption consumed by MEC server. Sometimes the MDiis idle when lots of tasks are processed in MEC server, and the corresponding idle energy cost is
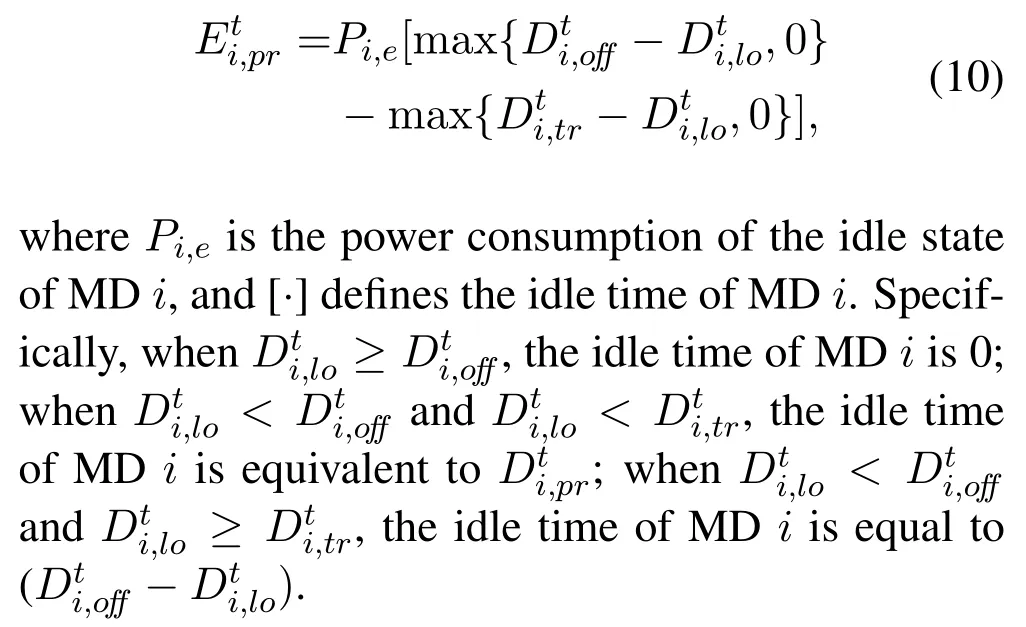
According to Eq. (9) and Eq. (10), the energy cost of MDigenerated by tasks offloading approach is
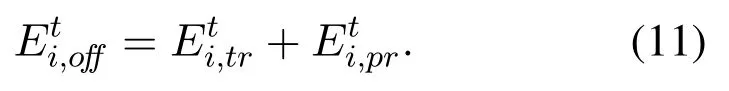
Then, the total energy consumption of MDiis the sum of local power consumption and the offloading energy consumption,as follows:
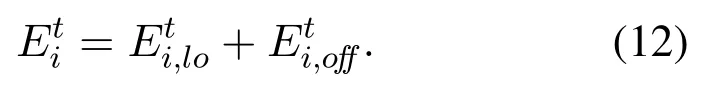
3.4 Battery and Energy Harvesting Model
By adopting energy harvesting techniques,we can obtain satisfying and sustained computation performance in MEC system. The EHQ can capture renewable energy such as solar energy to power the operations of the MDs. We denote the harvested energy asthat evolves according to the i.i.d random process and its maximum value isE. Generally,the harvested energy is dynamic on account of the changeable environment,which brings challenge to design an algorithm without the specific probability distribution of.
For the arrived renewable energy harvested by EHQ,only part of it denoted ascan be charged for the battery until its capacity supplying power for MDi. Note that the energy acquired by the MDicannot exceed the harvested renewable energy from the environment,as follows:

The energy harvested in the battery would supply for both local execution and computation offloading during next time slot. The battery level is defined as[0,B], whereBdenotes the battery capacity.Out of the consideration of security and stability of the MEC system,the total energy consumption is supposed to satisfy the following constraint:

Then the battery level in next time slot evolves as follows:
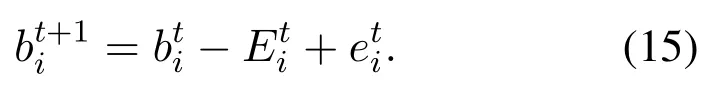
3.5 Problem Formulation
The joint computation offloading and resource allocation problem can be formulated as optimization problem aiming at minimization of the total cost of MDs in MEC system, which demands an online algorithm to solve on account of the uncertain task and renewable energy arrivals for future.
The cost of MDiis the sum of time delay cost and energy consumption cost, which can be expressed as follows:
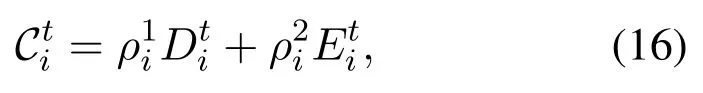
whereandare the relative weights of time delay and energy consumption.Note that similar to the studies in [37], we ignore the cost generated when MDs download the computation results from MEC server in the models above,for the reason explained in Subsection 3.1. Then the total cost of all MDs in MEC system denoted asCtcan be given by.
Consequently, jointly considering the decisions of computation offloadingα={αi,?i}and resource allocationβ={βi,?i}, the total cost minimization problem is formulated as:
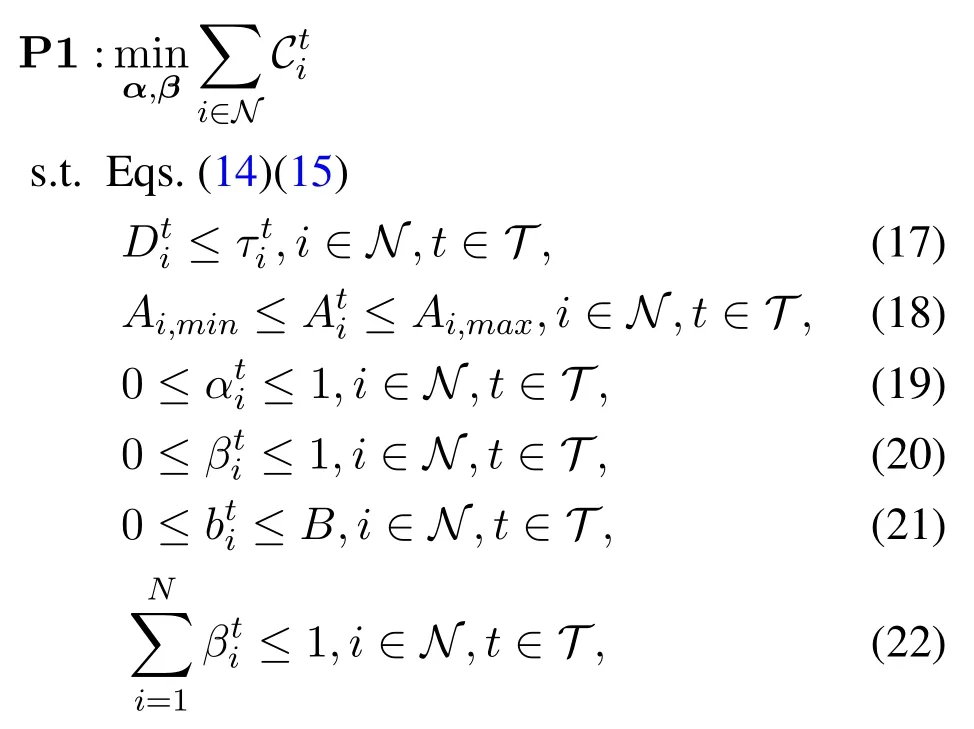
where Eq.(17)ensures that tasks are completed within the delay constraint;Eq.(18)and Eq.(21)indicate the bound of arrival tasks and battery level, respectively;Eq. (19) ensures that the number of offloading tasks won’t exceed the arrival tasks in MDi;Eq.(20)guarantees that the sum of computation resource allocated to each MD won’t exceed that of the MEC server;Eq.(22)states the total computing resource allocated to each user must not outstrip the computing capacity of the MEC server.
From the observation of the problem P1, it is obvious that both computation offloading and resource allocation decisions are continuous. Furthermore,the current battery level evolves depending on both the harvested energy and decisions. Consequently,the problem P1 is a non-linear non-convex problem,which cannot be solved by traditional convex optimizers.
IV. ONLINE DEEP REINFORCEMENT LEARNING POLICY
In this section, the DRL based CORA algorithm in MEC system is introduced. The formulations of key elements in the RL are described and the DQN based proposed problem is shown in detail.
4.1 Reinforcement Learning Algorithm
RL is a natural framework to make sequences of decisions, which has no direct guidance during the learning process. In RL,the agent obtains the best strategy by constantly interacting with the environment. The following learning scenario is considered: The agent acquires the statestat each time, which is the observation of the MEC environment. Then,the agent takes an actionataccording to a policyπ,after which a corresponding rewardrtis obtained and the system enters a new statest+1.
Generally, RL can be adopted to address the problems with the following characteristics: (1)The action taken by the agent depends on the current state of the system, and the current state of the system as well as the action taken determines the future state. (2) The agent can only get the information of the current state and the past actions. (3)The cumulative reward is optimized. (4)The system sometimes may be unstable.
The joint computation offloading and resource allocation problem we discussed has exactly the following four characteristics:(1)During the running time,tasks assignment and resource allocation vary with the arrival tasks,and the future battery level depends on both the current offloading strategy and arrival renewable energy. (2)The system is uncertain about the amount of future tasks arriving in MDs,while it can determine the amount of tasks arrived and strategies in the past.(3) The multi-user MEC system aims at minimizing the total cost of MDs. (4) The actual amount of the available harvested energy is non-stationary. Therefore, the problem we proposed can be solved by RL algorithm.
As we have discussed in Section III,the state space representing the state of the MEC system at the moment includes the following parts:the computation input data size for arrival tasks,,the total number of required CPU cycles to process the arrival tasks,, the battery level,,the distance between MDs and the edge server,,and the renewable energy harvested by EHQ,, and the fading amplitude of sub-channels,.In summary,the state can be given by
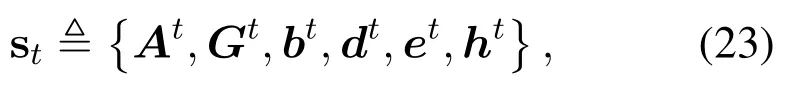
among whichAt,Gt,dt,etandhtare external states that are not related to the offloading strategy,whilebtevolves based on the joint computation offloading and resource allocation policy as well as harvested renewable energy.
During time slott,the agent chooses an action at ∈Aincluding the decisions of computation offloading and resource allocation according to the current state st ∈Sfollowing the policyπ. In this paper,the action is denoted as

We focus on optimizing the policy to minimize the total cost of MDs in MEC system, which is defined as Eq. (16). Out of the consideration that the reward function that guides the learning should be in accordance with the objective, which is a maximization problem generally, the reward function in our framework can be given by

which satisfies that the smaller the cost is,the greater the return is. However,the above function is not very efficient,due to the fact that the return is always negative,which makes the proposed policy perform conservatively during the learning process. In order to avoid conservative learning process, we introduce the concept of average cost in the reward function. Then the new reward function is defined as

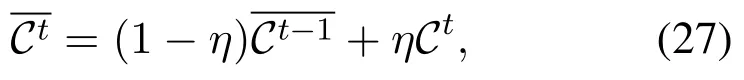
whereηis the weighting factor determining the importance of current cost.
We see from Eq. (26) that when the cost is higher than the average cost,the agent will get a negative reward,encouraging the agent to reduce the probability of the corresponding action, and vice versa. With the space, action and reward function defined, we attain the action value matrix Q in Q-learning algorithm by the following iteration:
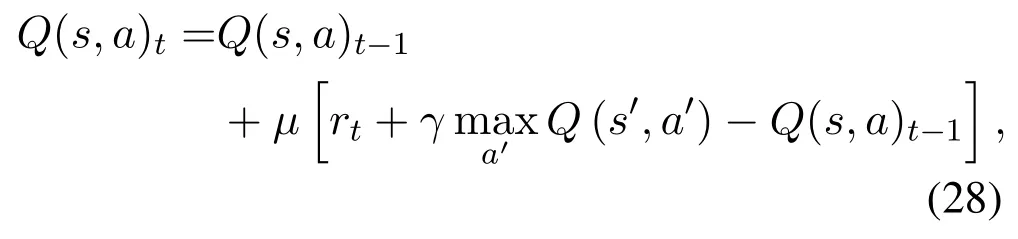
whereμis the learning rate in [0,1) determining the importance of new reward.γ ∈(0,1) denotes the discount factor weighting the immediate reward and future reward. Ands′,a′are the next state and action.Then we have the arbitrage policy based on Q-learning as
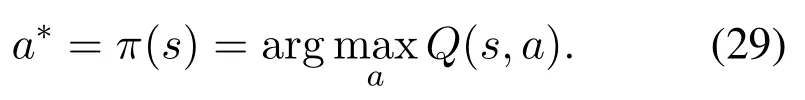
4.2 Deep Q-Network Based CORA Algorithm
Although Q-learning is an efficient method to solve MDP problem, it’s impractical when the state-action space is huge,just as the optimization problem in this paper. The reason is the state space grows exponentially with the numbers of MDs,which leads to an extremely large Q-matrix as well as a much longer converging time for the Q-function.

Algorithm 1. DQN based CORA algorithm.Input: At,Gt,bt,dt,et,ht Output: αt,βt 1: Initialize replay memory D to capacity M.2: Initialize the evaluation and target Q-networks with the same value of parameter w and w?.3: Initialize discount factor γ,learning rateμ,greedy ε.4: for episode=1,...,K do 5: The MEC system starts at the observable state s1 6: for time slot=1,...,T do 7: Select action at randomly with probability 1 ?ε, otherwise choose action at =arg max a Q(s,a;w)8: Take the action at,get the instant reward and derive the next state st+1 9: Store transition(st,at,rt,st+1)in memory D 10: Sample mini-batch size of transitions(sj,aj,rj,sj+1)in memory D 11:Set yj =images/BZ_101_373_1588_407_1633.pngrj for terminal sj+1 rj +γ maxa′Q(sj+1,a′;w?) otherwise 12: Calculate loss function L(w) and the gradient of L(w) with respect to w according to Eq.(30)and Eq.(32)13: Update w 14: Update w?=w every L steps 15: end for 16: end for
To tackle the problem,we propose a DRL based algorithm CORA, which incorporates Q-learning with DNN, i.e., DQN. Due to the fact that the RL with a nonlinear function approximator such as DNN is generally unstable, we adopt two key ideas proposed in [38] including a biologically inspired mechanism termed experience replay and a periodically iterative update of target Q-value.The formal key idea removes the correlations among the observation sequences as well as smooths over changes in the data distribution by sampling a mini-batch uniformly at random from experience replayD. The latter key idea reduces the correlations between the evaluation Q-value and the target Q-value via updating the parameters of the target Q-network periodically[39].
In DQN,a 5-layer full connected feed-forward neural network named evaluation network with parameterwis used to approximate Q-value as well as generate the current action,where each hidden layer has 20 neurons [40]. The input and output of the evaluation network are the statesand the action valueQ(s,a;w),respectively. Another neural network in DQN named target network with parameterw?has the same structure and initial parameter as evaluation network,which is used to stabilize the network. The detailed framework of DQN is shown in Figure 2.
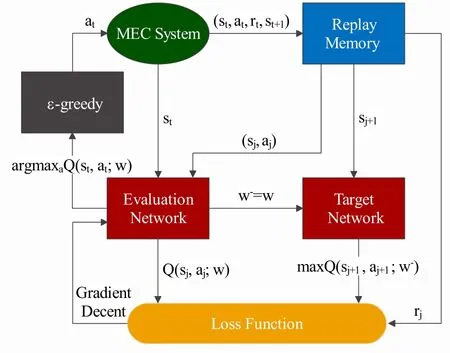
Figure 2. Detailed framework of DQN.
Generally, the CORA algorithm shown in Algorithm 1 works as follows: Firstly, the central controller obtains the observable state stof MEC system, and inputs it to the evaluation Q-network. After the Q-value of each available action is outputted,theε-greedy strategy is employed to select the current action. Specifically, usingε-greedy, the algorithm will randomly extract an action of computation offloading and resource allocation with the probability ofε ∈[0,1], and make the greedy decisionat=argQ(s,a;w)with the probability of 1?ε.After choosing an action,the rewardrtcan be obtained according to Eq.(26),and the system turns into the next statest+1. And the transition (st,at,rt,st+1) will be stored in replay memoryD. Then a minibatch of transitions(st,at,rt,st+1)from replay memoryDwill be randomly sampled as inputs of two Q-networks.Given the two Q-values outputted by Q-networks, we apply mean square error (MSE) method to obtain the loss function in our algorithm,as follows:
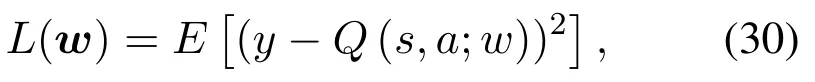
where
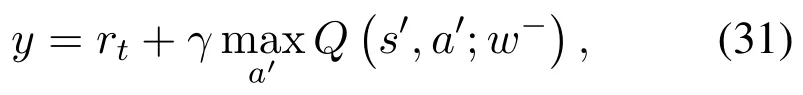
is the output of the target Q-network. AndQ(s,a;w)is the output of the evaluation Q-network,accordingly.Subsequently,a gradient descent strategy described as(32)is employed to update the parameterwof evaluation Q-network via minimizingL(w)in Eq.(30).
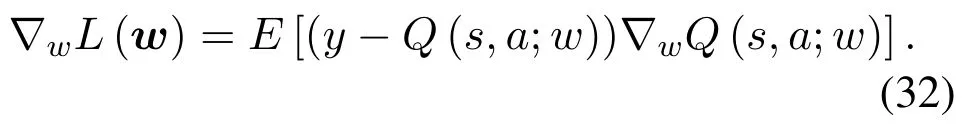
Note that the initial parameters of two Q-networks are the same,andwis updated step by step,whilew?is only updated everyLsteps by copyingw.
V. SIMULATION RESULTS
In this section,we verify the performance of the DQN based CORA algorithm through simulations,which is carried out with pytorch 1.3.1 and Python 3.7.0 ona computer with Windows 64 bits, 3.59 GHz AMD Ryzen 5 3600 6-Core Processor,and 16 GB RAM.We consider the MEC system with a edge server and three MDs, and the parameters of MEC system in simulations are set as follows.
The computation input data size of task arrivalin MDiis randomly distributed between 0 and 10 MB,and the expected number of CPU cycles required for per unit of task isψ=8×105. The harvested energyis uniformly distributed with the maximum valueE= 1 mJ. For simplicity, all MDs are supposed to have with the same computation capacity offi,lo=2.4 GHz,which actually varies among different MDs.According to the measurements reported in [41], the unit energy consumption for per CPU cycle to accomplish the tasks locally is set aszi=10?11(fi,lo)2. The computational capacity of MEC server that can be allocated to the MDs is set asF= 20 G CPU cycles per second. Without loss of generality,we setB= 2 mJ,r= 500 m,= 0.1,ε= 0.9 andη=0.01.For clarity,we list the main parameters used in the simulations in Table 1. Note that some parameters may be varied as variable parameters according to different evaluation scenarios.
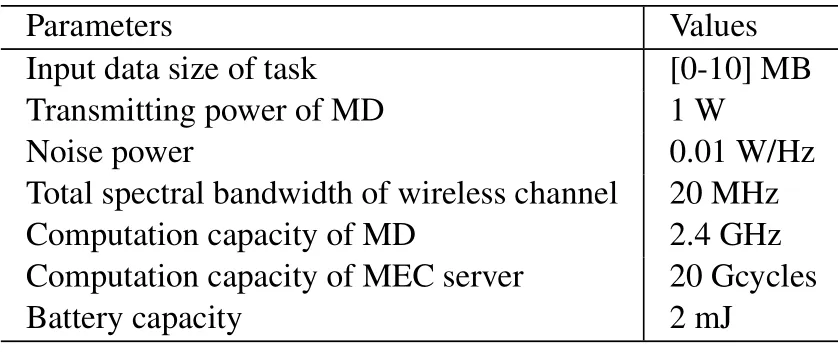
Table 1. System parameters.
5.1 Parameter Analysis
We plot the average total cost including delay and energy with different system parameters in Figure 3 including task arrival rate,transmitting power and mean value of fading amplitude.
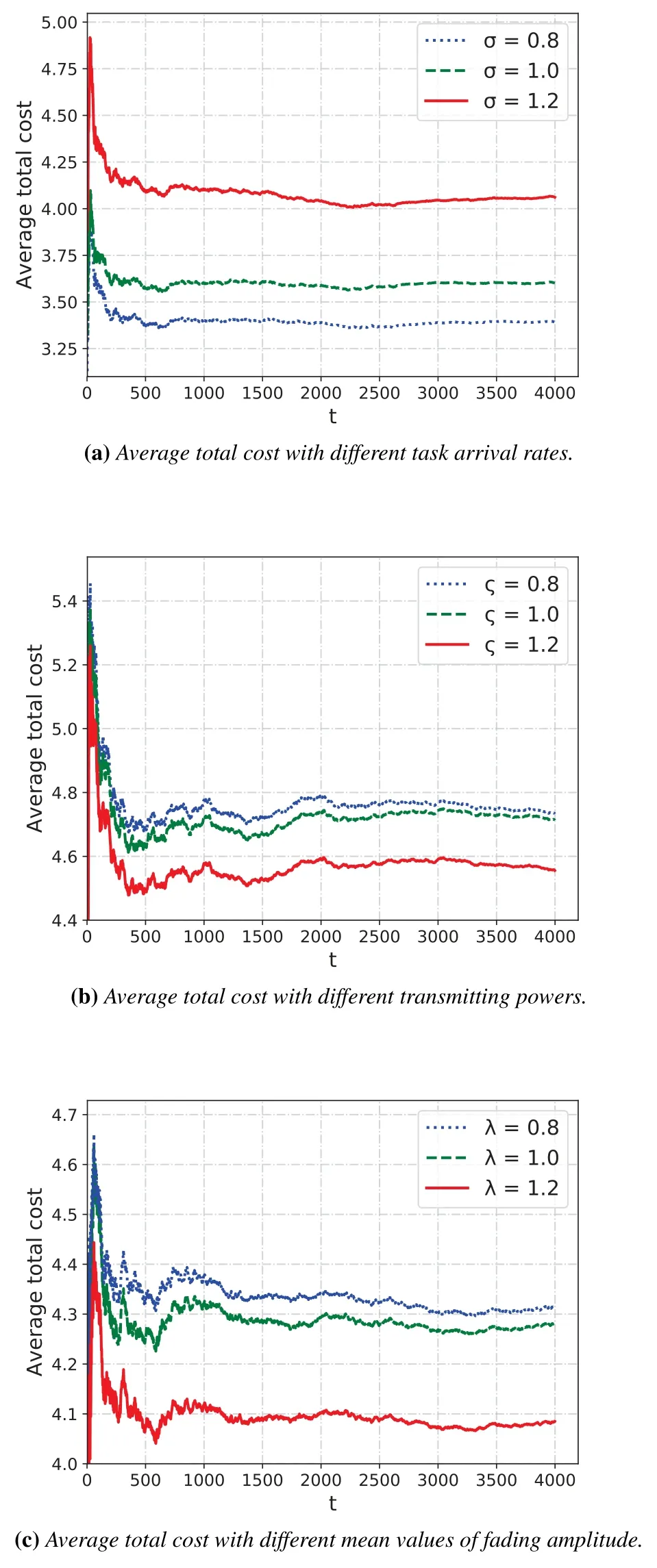
Figure 3. Average cost with different system parameters.
Figure 3a plots the average total cost with different task arrival rates,i.e.,the computation input data size for each MD, which is set as, whereσ= 0.8,1 and 1.2,respectively. We can see that as task arrival rate rises,the average total cost increases,because the greater the amount of computation input data size,the more CPU cycles required for task processing. As a consequence,more time and energy are needed during the execution.
Figure 3b plots the average total cost with different transmitting powers. The transmitting power of a MD is set as, where?= 0.8, 1 and 1.2, respectively. As can be seen in Figure 3b, the average total cost increases along with the decreasing transmitting power. This is due to the fact that the uplink data ratemonotonically increases with respect to transmitting poweraccording to Eq.(2),and the delay cost decreases as the uplink data rate increases. Despite the fact that the transmitting power consumptionis proportional to transmitting power,less total cost is consumed whenis larger on account of a small weight value ofin Eq.(16).
In Figure 3c,we plot the average total cost with different mean values of.For each sub-channel,we set the fading amplitude as, whereλ= 0.8, 1 and 1.2,respectively. It can be observed that as the fading amplitude rises,the total average total cost decreases.This is because that with the rise of fading amplitude,the uplink data rate for each MD would also increase,leading to a decreasing transmission delay cost.Figure 4 shows the relations between the learning rate and the convergence of our proposed CORA algorithm. The learning rate determines the speed of updating the weight parameterwin DQN. As can be observed in Figure 4, the learning process of DQN is faster with a larger learning rate of 0.01.
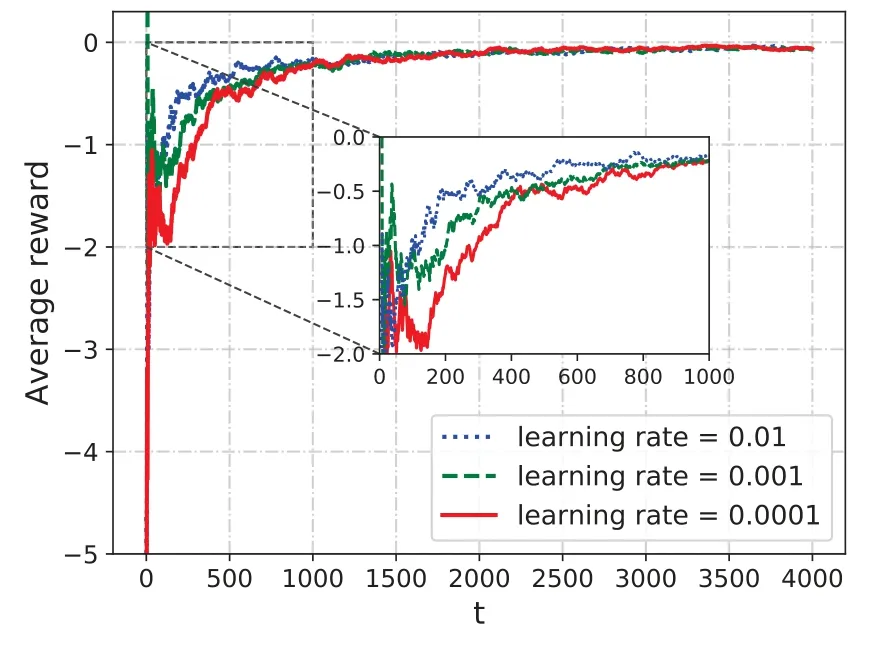
Figure 4. Convergence performance under learning rates.
5.2 Comparison Experiments
To further demonstrate the superiorities of proposed DQN based CORA algorithm,we specially introduce the following three schemes as benchmark methods for comparison, i.e., myopic scheme, greedy scheme and fixed scheme. They work as follows:
? Myopic Scheme: In this scheme, the system focuses on the short-term cost rather than the longterm cost, which means that only the cost of the current state is considered when the system decides to take an action.The system tends to utilize all available battery energy to obtain the minimum immediate cost at the current time slot,regardless of the temporal interrelationship between the future states and decisions.
? 0-1 Scheme: In this scheme, the tasks are not divisible, and the system makes a decision of whether offloading the tasks to edge server or not to maximize the reward function.
? Fixed Scheme: In this scheme, the system decides to offload a fixed proportion of tasks to MEC server in each time slot without concerns of the current amount of task arrivals and harvested energy.
To compare the performance of different methods,Figure 5 plots the average total cost, time delay and energy consumption of four algorithms. Figure 5a demonstrates that the average total cost decreases gradually when the MDs interact with the MEC system after more time slots and the average total cost of the DQN based CORA scheme outperforms the other three schemes, which is realized by relatively lower time delay and the lowest energy cost,as Figure 5b and Figure 5c, respectively. The reason is that the CORA scheme dynamically makes the joint computation offloading and resource allocation decisions among the MDs to match the task arrival and channel dynamics.
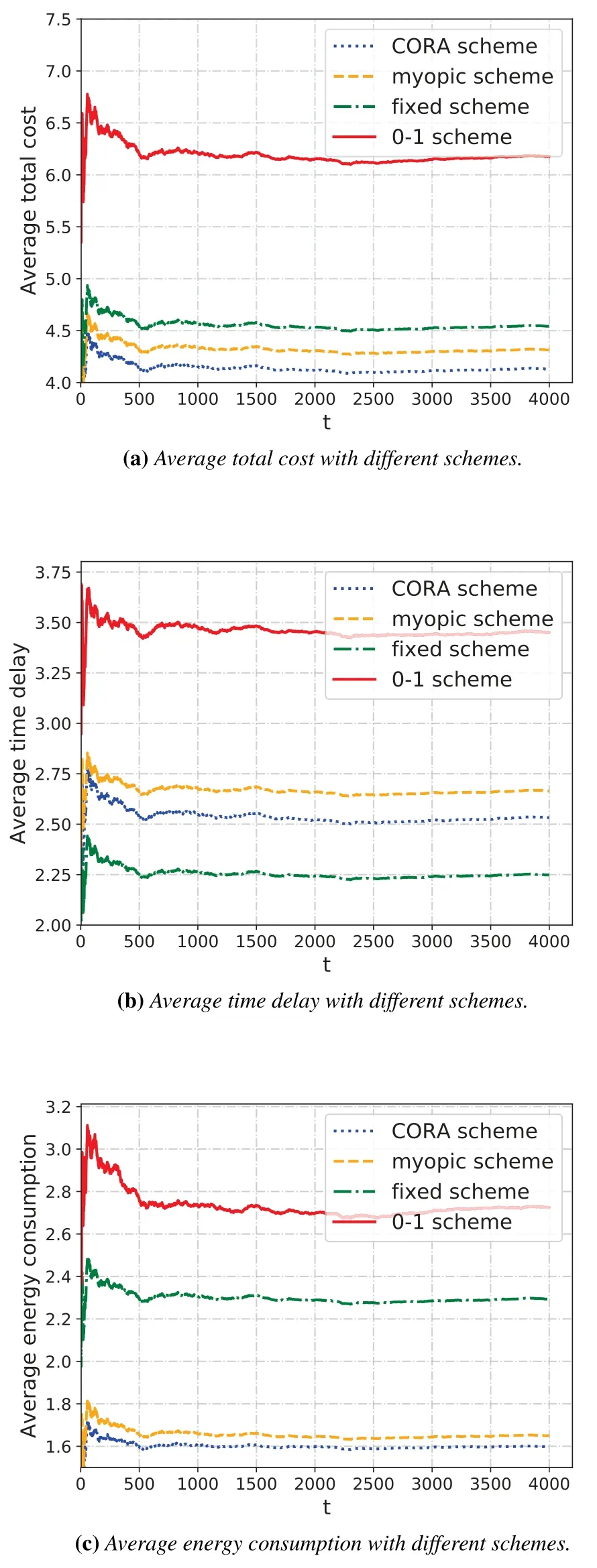
Figure 5. Average cost with different schemes.
Figure 6 reveals the relationship of the energy queue length with different schemes. As Figure 6 indicates,the energy queue length of the proposed DQN based CORA algorithm converges to a lager value than other methods. The result is largely on account of the fact that the CORA tends to adopt a relatively conservative strategy while interacting with MEC system to reserve sufficient energy supply for the future tasks,which keeps the system stable potentially.
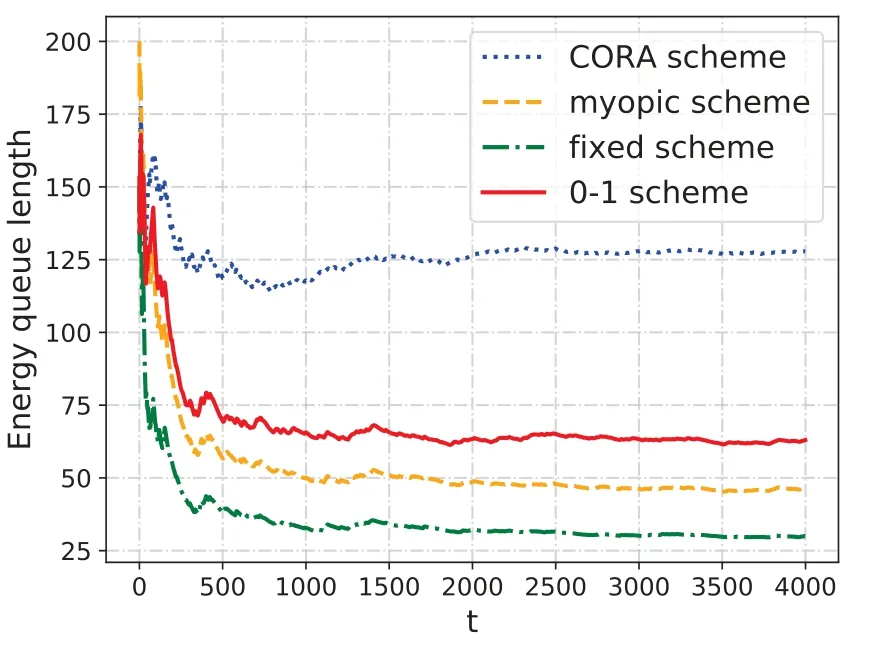
Figure 6. Energy queue length with different schemes.
We plot the average total cost of four algorithms with different parameters in terms of computation capacities of MDs and computation resources of edge server in Figure 7 and Figure 8.
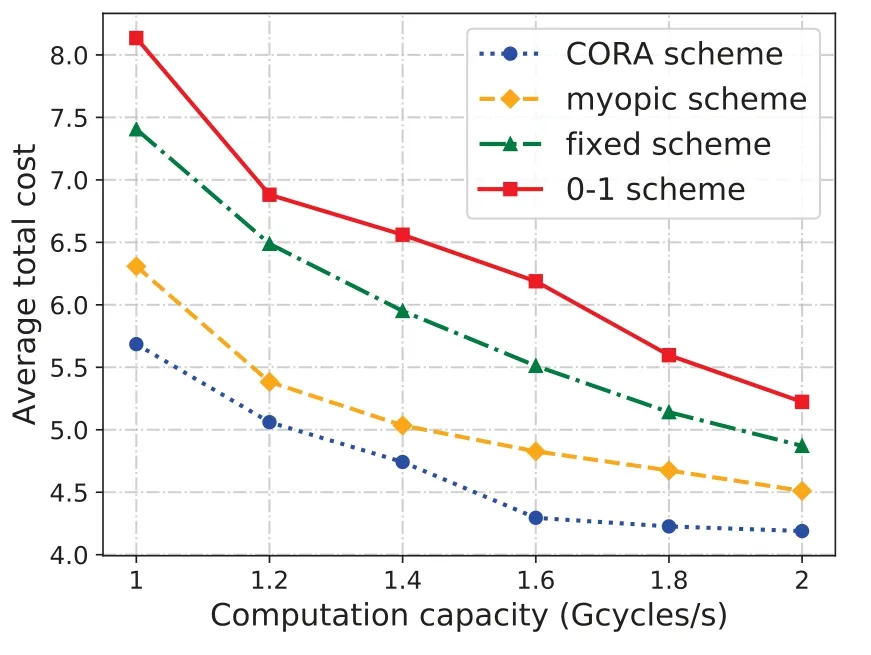
Figure 7. Average total cost versus computation capacity.
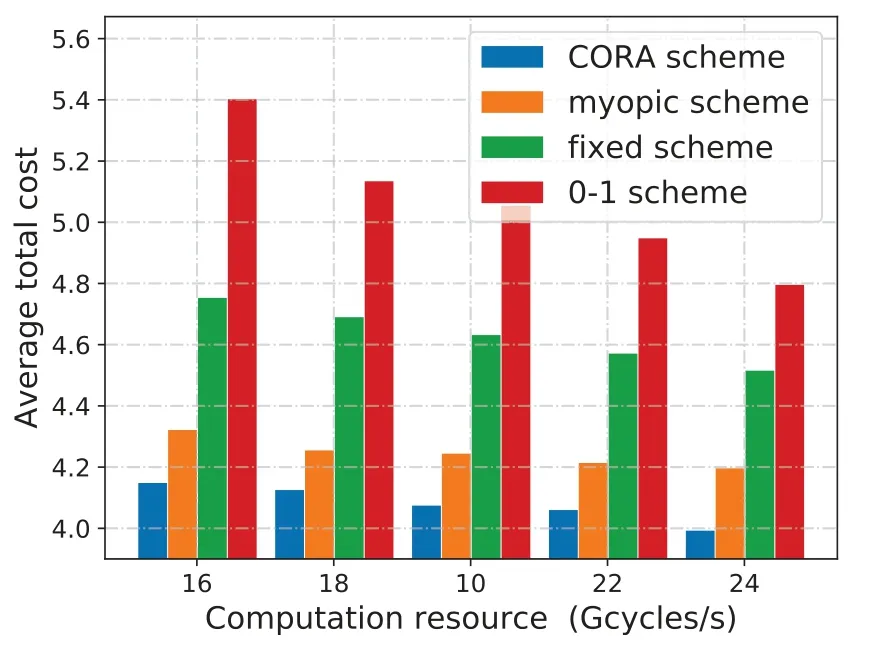
Figure 8. Average total cost versus computation resource.
Specifically,we consider the effect of different computation capacities of MDs to execute tasks locally in Figure 7. In this simulation,the computation capacity of MDsfi,loranges from 1 Gcycles per second to 2 Gcycles per second. In Figure 7, we plot the average total cost of CORA algorithm as well as other three benchmark methods. Due to the fact that larger computation capacity always leads to less local execution delay cost,the long-term average total cost of all four algorithms decreases. Nevertheless, the average total cost of the proposed DQN based CORA algorithm decreases relatively slowly compared with three benchmark methods, demonstrating that the CORA algorithm is able to make satisfying joint computation offloading and resource allocation decisions,which significantly reduces the total cost of MDs.
Furthermore,we simulate for computation resource of the edge serverFfrom 16 to 24 Gcycles per second.As Figure 8 shows, the rate curves of four schemes indicate that the average total cost of all schemes decreases with the increasing computation resource of edge server, because bigger computation resource leads to less execution delay cost for offloaded tasks.We see that our proposed algorithm generates less cost while having the same computation resource. What’s more,the average total cost under the four schemes decreases as computation resource increases. Compared to 0-1 scheme, fixed scheme and myopic scheme,the CORA scheme reduces the average total cost up to 20.7%, 13.0% and 3.3% when computation resource is 18 Gcycles per second,respectively.
VI. CONCLUSION
In this paper, the minimization problem of weighted sum of energy consumption, processing delay and communication delay of MDs in multi-user MEC system with EHQs was investigated. First,we proposed a partially task offloading scheme with a mobility model of MDs and formulated the joint computation offloading and resource allocation problem as a constrained optimization problem. As the problem can be described as an MDP, then we proposed a DRL based algorithm named CORA to solve the problem. Considerable numerical results shown the superior performance of CORA in decreasing the total cost in terms of energy consumption and delay of MDs,and the efficiency among multi-users.
Given that the edge server with insufficient storage capacity has difficulty in caching all services from remote cloud,an interesting direction for future work is to investigate the joint optimization problem of computation offloading, resource allocation and service caching in a three-tier multi-server MEC system.
ACKNOWLEDGEMENT
This work was supported in part by the National Natural Science Foundation of China under Grant 62072096,in part by the Fundamental Research Funds for the Central Universities under Grant 2232020A-12,in part by the International S&T Cooperation Program of Shanghai Science and Technology Commission under Grant 20220713000,in part by“Shuguang Program”of Shanghai Education Development Foundation and Shanghai Municipal Education Commission,in part by the Young Top-notch Talent Program in Shanghai, and in part by “the Fundamental Research Funds for the Central Universities and Graduate Student Innovation Fund of Donghua University” under Grant CUSF-DH-D-2021058.

- China Communications的其它文章
- Edge Intelligence for 6G Networks
- Register Allocation Compilation Technique for ASIP in 5G Micro Base Stations
- Joint Computing and Communication Resource Allocation for Edge Computing towards Huge LEO Networks
- Federated Reinforcement Learning with Adaptive Training Times for Edge Caching
- Paving the Way for Economically Accepted and Technically Pronounced Smart Radio Environment
- Arbitrary Scale Super Resolution Network for Satellite Imagery