
DNN-Based Speech Enhancement Using Soft Audible Noise Masking for Wind Noise Reduction
2018-09-06 06:25:52HaichuanBaiFengpeiGeYonghongYan3
China Communications 2018年9期
Haichuan Bai*, Fengpei Ge Yonghong Yan3
1 Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics, Chinese Academy of Sciences,Beijing 100190, China
2 University of Chinese Academy of Sciences, Beijing 100049, China
3 Xinjiang Laboratory of Minority Speech and Language Information Processing, Xinjiang Technical Institute of Physics and Chemistry,Chinese Academy of Sciences, Urumqi 830011, China
Abstract: This paper presents a deep neural network (DNN)-based speech enhancement algorithm based on the soft audible noise masking for the single-channel wind noise reduction. To reduce the low-frequency residual noise, the psychoacoustic model is adopted to calculate the masking threshold from the estimated clean speech spectrum. The gain for noise suppression is obtained based on soft audible noise masking by comparing the estimated wind noise spectrum with the masking threshold. To deal with the abruptly time-varying noisy signals, two separate DNN models are utilized to estimate the spectra of clean speech and wind noise components. Experimental results on the subjective and objective quality tests show that the proposed algorithm achieves the better performance compared with the conventional DNN-based wind noise reduction method.
Keywords: wind noise reduction; speech enhancement; soft audible noise masking; psychoacoustic model; deep neural network
I. INTRODUCTION
Single-channel speech enhancement methods are widely used in the voice communication systems to improve the quality of speech signals in telecommunication terminals and audio recording devices, such as tablet computers,smartphones, voice recorders, digital cameras and intelligent man-machine interaction equipment. However, in the real acoustic environment, the perceived quality and intelligibility of the enhanced speech signals are still greatly deteriorated by the non-stationary background noise, especially the wind noise when recording in the open air.
The wind noise is usually generated by the turbulent air flow around the user’s head, the recording devices or other obstacles. For a breeze less than five meters per second, the long-term average wind noise level can be up to 110dB in Sound Pressure Level (SPL) [1],which causes serious negative impacts on the sound quality for the voice communication.Frequency analysis and measurements show that the spectrum of the wind noise is dominant at the low frequencies, and rolls off as the frequency increases [2]. Besides, the wind noise exhibits the serious non-stationary characteristics because the wind often rises and changes unpredictably [3]. So, removing wind noise without speech distortion is a challenging task for voice communication.
This paper presents a deep neural network (DNN)-based speech enhancement algorithm based on the soft audible noise masking for the single-channel wind noise reduction.
Traditional single-channel speech enhancement methods, such as spectral subtraction and spectral weighting, usually depend on the spectrum estimation of noise components.Many algorithms [4-7] were proposed based on tracking the time-varying noise signals,but the accurate spectrum estimation of wind noise cannot be obtained because of its non-stationary characteristics. The mismatch between the estimated and real wind noise causes the performance degradation of speech enhancement, and leads to the undesired residual noise. Hence, some special algorithms are designed for wind noise reduction (WNR).In [8], the reference templates were used to estimate the spectral envelope of wind noise,and the enhanced speech was obtained by subtracting the estimated wind noise spectrum from the noisy signal. M Schmidt [9] proposed a WNR method based on non-negative sparse coding, which relied on the wind noise dictionary estimated from an isolated noise recording. In [10], the time-domain adaptive post-filtering algorithm was proposed to detect and attenuate the acoustic effect of wind noise in speech signals. B King [11] proposed a method which adopts a coherent modulation comb filter to enhance the harmonic structure of speech components in the wind noise condition. To improve the auditory quality and intelligibility of the enhanced speech, C M Nelke, et al., presented several frameworks to enhance the single-channel speech signals degraded by wind noise [3, 12-14]. In [3], the algorithms of speech bandwidth extension were introduced into the WNR task to synthesize the low-frequency spectrum of speech components. In [12] [13], signal centroids and binary masks were separately exploited to estimate the noise short-term power spectrum, and spectral weighting was performed to enhance the speech signals. Additionally, C M Nelke, et al., proposed a more elaborate WNR system [14] to employ the binary mask to eliminate the time-frequency bins which represents severe wind noise information, and the missing speech components were reconstructed using a pre-trained codebook that stores the acoustic knowledge. As one of the most popular machine learning methods, the deep neural network (DNN) model [15] has been applied to represent the highly non-stationary characteristics of the wind noise. By incorporating the speech and noise power estimation processes in the spectral weighting framework, the DNN-based enhancement algorithm achieves the promising performance for the single-channel WNR in the off-line processing manner.
The DNN model is powerful to estimate the wind noise and speech component, by using large amounts of data recorded in the specific environment. However, some residual wind noise remains in the low-frequency region below 3 kHz where the spectrum of wind noise overlaps with the voiced speech. Especially in the low signal-noise ratio (SNR) condition, the residual noise is easily perceived by human ears and the auditory quality and intelligibility of the enhanced speech signals are deteriorated. In this paper, we propose a novel DNN-based speech enhancement framework for WNR in order to suppress the audible residual wind noise with the perceptual model-based method. A psychoacoustic model is employed to compute the masking threshold from the estimated speech spectrum, and the soft audible noise masking (SANM) principle is brought into the spectral weighting algorithm by using the masking threshold and the estimated spectrum of wind noise. To deal with the rapidly time-varying signals, both of the speech and noise spectrum are estimated based on the DNN models. The proposed framework can effectively suppress the residual wind noise in the low-frequency region.
The rest of this paper is organized as follows. Firstly, the principle of SANM algorithm for speech enhancement is described in Section 2. In Section 3, we present the proposed WNR framework. The experiments and results are shown in Section 4. Finally, we give the conclusion in Section 5.
II. THE ALGORITHM OF SOFT AUDIBLE NOISE MASKING
The main objective of SANM for speech enhancement [16] is to choose an appropriate amount of attenuation based on the psychoacoustic model to make balance between the amount of audible noise reduction and the amount of distortion introduction to the clean speech. In this section, we brie fly describe the SANM principle.
The speech signal recorded in wind noise condition can be described by the additive signal model as follows:
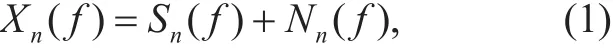
where Xn(f), Sn(f), Nn(f) represent the shorttime Fourier spectrum of noisy signals, clean speech and wind noise. n and f are the indices of frame and frequency bin.
For the speech enhancement algorithms based on spectral weighting, a non-negative gain gn(f) is introduced to the noisy speech spectrum Xn(f) to suppress the noise components. The spectrumof the enhanced signal can be presented as,
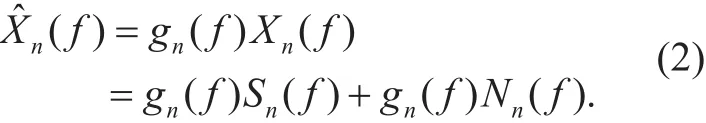
Under the independent assumption between clean speech and wind noise, gn(f)Sn(f)and gn(f)Nn(f) represent the distorted speech components and the residual wind noise components in the enhanced speech, respectively,and the SANM method intends to minimize the following cost function,
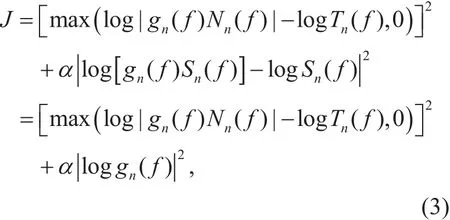
where Tn(f) is the masking threshold calculated from the speech spectrum Sn(f) by using the psychoacoustics model. This cost function not only penalizes the speech distortion but also reduces the residual wind noise above Tn(f).The parameter α ≥ 0 can be adopted to control the relative importance of two parts in the cost function. To simplify the optimization process, we assume that Tn(f) is irrelevant to gn(f).Then, the optimized suppression gain gn(f)based on SANM that minimizes the above cost function can be derived as follows,
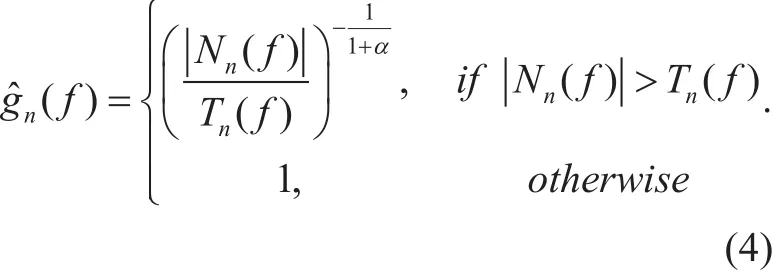
If the amplitude spectrum of residual wind noise is lower than the masking threshold of speech for one frequency bin, no suppression will be applied to the noisy spectrum; otherwise, the amount of attenuation will be determined by the noise-to-mask ratio for each frequency bin. It is noteworthy that the parameter α ≥ 0 can be used to control the performance of the speech enhancement. Larger values of α will achieve less speech distortion but more audible wind noise. Thus, α should be carefully tuned manually or automatically, according to the real applications. In the proposed system, α is empirically set as 1.
III. THE PROPOSED WIND NOISE REDUCTION FRAMEWORK
In the light of SANM principle, we present the proposed DNN-based WNR system using SANM (denoted by SANM-DNN) in this paper, as shown in figure 1. The input noisy speech signals are sampled at 16kHz and are separated into 32-ms frames with 16-ms overlap. Then, the noisy speech signals are transformed into the frequency domain via shorttime Fourier transform (STFT) with Hamming window. Then, the 257-dimensional amplitude spectrum of noisy signals |Xn(f)| is fed to two DNNs to separately estimate the spectra of wind noise and speech. Since both the clean speech and wind noise are characterized by a high degree of non-stationary, DNN-based estimators will be useful to track the rapidly-changing speech and noise components frame by frame. Next, a psychoacoustic model is used to calculate the masking threshold Tn(f)from the estimated amplitude spectrumof clean speech. The suppression gainfor each frequency bin is derived from the resulting masking threshold and estimated amplitude spectrum of wind noiseaccording to SANM. Finally, the complex spectrum of noisy signals is directly weighted byand the enhanced speech signal can be obtained via inverse STFT, windowing and overlap-add. In the next subsections, the detailed algorithms of DNN-based spectrum estimation and masking threshold calculation are described.
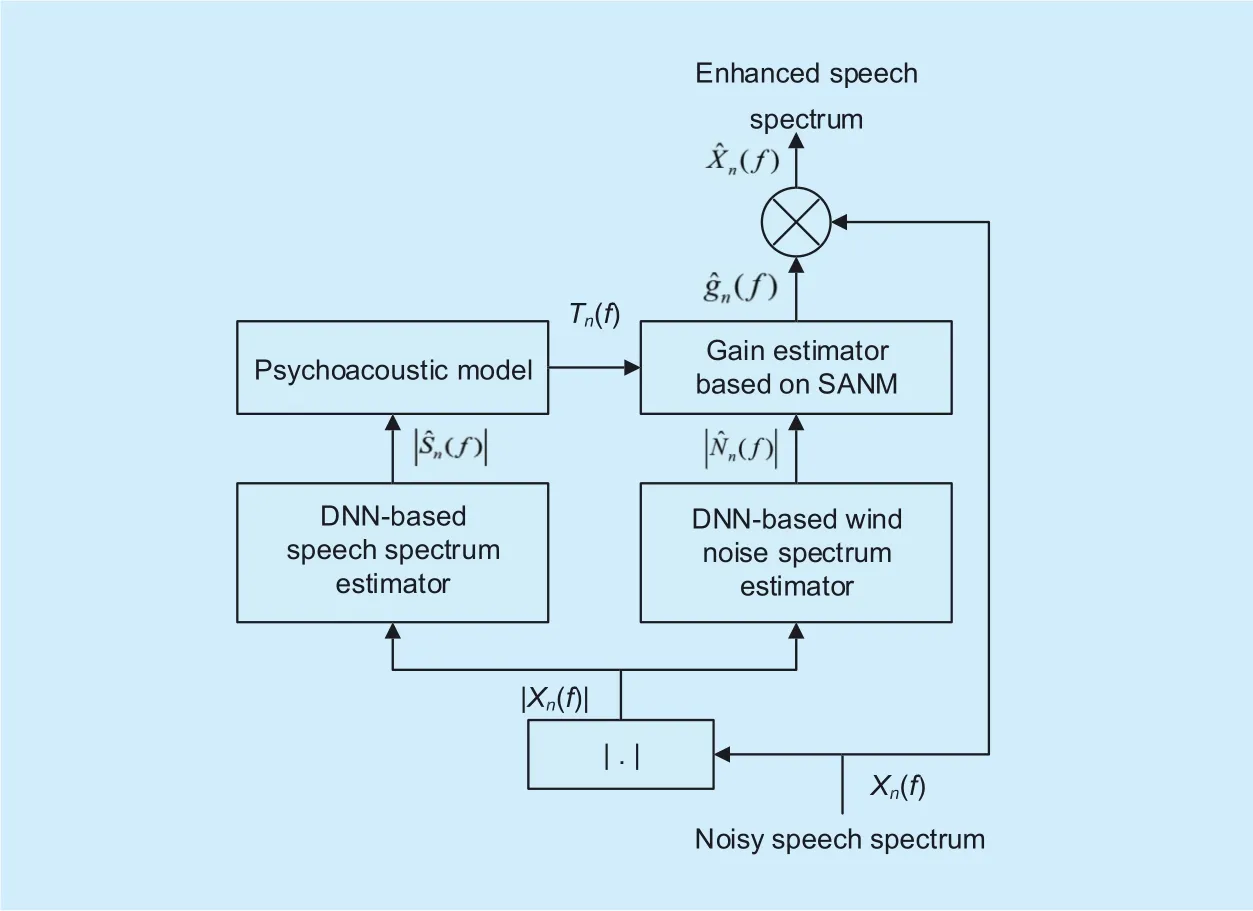
Fig. 1. Block diagram of the proposed SANM-DNN system.
3.1 DNN-based estimators of speech and wind noise
The solution of SANM shown in (4) requires the knowledge of the amplitude spectrum of wind noise signal |Nn(f)| and the masking threshold Tn(f) which is derived from the amplitude spectrum of target speech signal |Sn(f)|.In the real WNR task, |Nn(f)| and |Sn(f)| are unknown in general and need to be estimated from the known noisy speech spectrum Xn(f).
It is possible to directly estimate the amplitude spectra of speech and wind noise using the DNN model. However, it is well known that they can be better achieved from the noisy spectrum if we first estimate a set of masks,because masks are well constrained and are invariant to the energy changes of the input noisy speech. Then, the amplitude spectra of speech and wind noise can be respectively reconstructed in the following fashions,
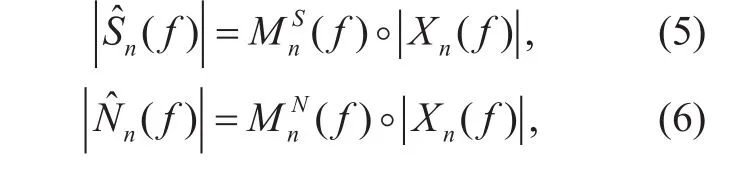
where ° represent the element-wise product operator, and MnS(f) and MnN(f) are the masks corresponding to the speech and wind noise components for each frequency bin. In the proposed method, the “ideal amplitude mask”(IAM) is adopted as the soft time-frequency mask for estimating the amplitude spectra, and is defined as,

Since the IAM takes the amplitude spectra rather than complex spectra of signals into consideration, there are no sum-to-one constraint between MnS(f) and MnN(f). However,in practice, we need to add another constraint that the values of these masks are restricted in the range between 0 and 1, in order to avoid DNN to estimate the unbounded values. In addition, since speech and wind noise are completely unrelated in the time-frequency domain, two separated DNNs are adopted in the proposed method to separately estimate MnS(f) and MnN(f), based on the parallel training corpus of clean speech, wind noise and mixed signals.
Additionally, to reduce the computation complexity, the feed-forward DNNs (FNN)are used to produce the speech and wind noise masks as
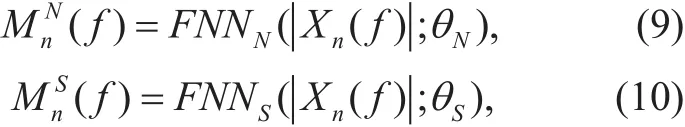
where θNand θSare the network parameters for the FNNs, and can be optimized to minimize the mean square error between the target amplitude spectrum and the amplitude spectrum reconstructed by using the estimated masks[17]. Thus, the objective functions are defined as,
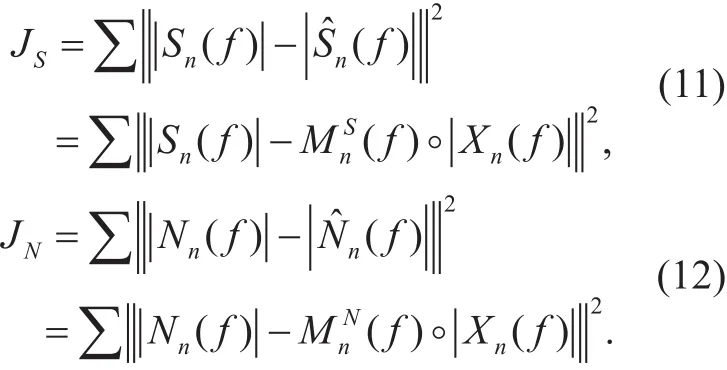
3.2 Masking threshold calculation
Since the true clean speech spectrum is not available in the WNR task, the masking threshold Tn(f) can be calculated from the estimated amplitude spectrumof clean speech by using the psychoacoustics model [18].
Here, two main properties of human auditory system are involved: absolute threshold of hearing and auditory masking. The absolute threshold of hearing Tath(f) can be well approximated by the following non-linear function,
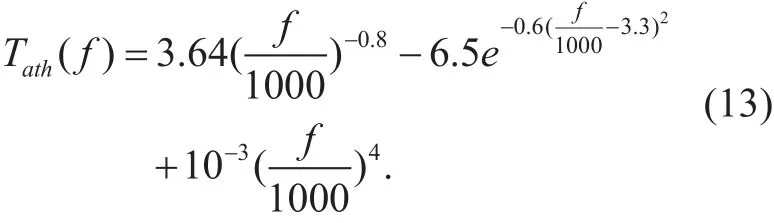
The frequency components whose energy level is below Tath(f) can be discarded, since they do not contribute in improving the perceptibility of the signal.
In addition, the auditory masking effect of clean speech is mainly determined by the spectral peaks in the low-frequency region for the WNR task, thus only the tonal masking analysis method described in [19] is employed to estimate the spectral masking threshold from

Next, the contribution of each masker to the overall masking threshold is evaluated. The spread of masking effects is modeled via the following function,
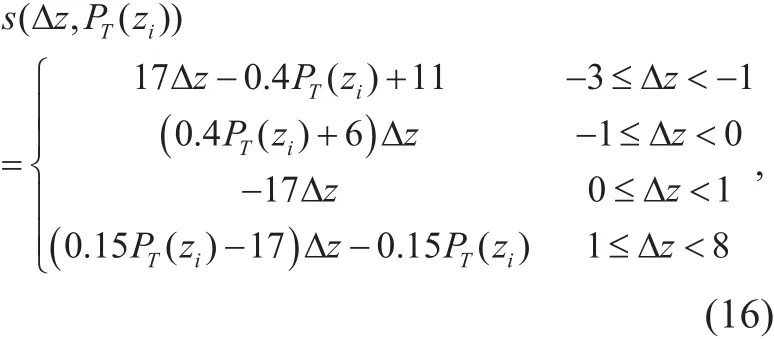
where Δz=zj-ziis the Bark frequency separation between the masker ziand the maskee zj.The individual masking threshold for each tonal masker is calculated as,
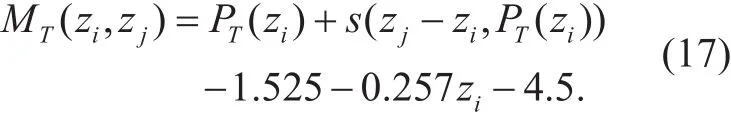
The individual masking thresholds for each sub-band, which is equally separated on the Bark scale. are computed using all the maskers. The global masking threshold per subband is computed by summing the individual masking thresholds form each masker along with the absolute threshold of hearing on the Bark scale, Tath(zj), as follows,
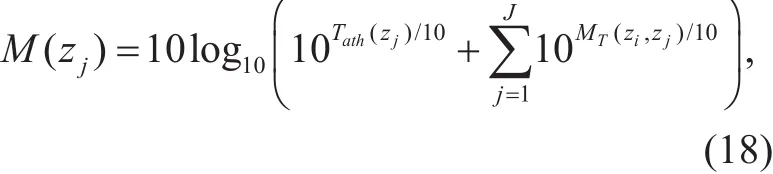
where J is the number of sub-band.
Finally, the global masking threshold is transferred back to the amplitude spectrum domain as Tn(f).
IV. EXPERIMENTS AND RESULTS
The proposed SANM-DNN WNR system was evaluated in terms of the log spectral distortion (LSD) [20], the perceptual evaluation of speech quality (PESQ) [21] scores, spectrogram analysis, as well as subjective preference tests, in comparison with two referential methods: (1) the DNN-based speech enhancement method without SANM (Direct DNN); (2)the DNN-based speech enhancement method using SANM with the true masking threshold (SANM-DNN-TM). For the Direct DNN method, IAM corresponding to the speech component is first estimated from the noisy speech amplitude spectrum via the feed-forward DNN, by minimizing the mean square error between the true clean speech spectrum and speech spectrum reconstructed by using the estimated masks as (11). Then, the amplitude spectrum of speech was directly reconstructed by weighting the noisy amplitude spectrum with the masks, without considering the perceptual model. The SANM-DNN-TM method adopts the similar principles as the proposed SANM-DNN method, except that the true speech spectrum is used to calculate the masking threshold for suppressing the residual noise. The details of the subjective and objective evaluation are given as follows.
4.1 Experimental setup
The proposed and referential methods were tested with wind noise collected outdoors by a microphone without any wind screen on a windy day with wind speeds up to 15 m/s.The clean speech samples are selected from TIMIT dataset [22], and the signal levels are adjusted to -26 dBov. For training and validation data, the randomly selected noise samples were added to 3000 and 300 utterances of clean speech with the SNRs of -5, 0, 5, 10 dB.For test data, another 100 utterances of clean speech were added to the wind noise samples in different SNR conditions and 500 utterances of noisy speech were obtained for evaluating the performance of the WNR systems.For training, validation, and test data, disjoint speakers and disjoint wind noise samples were used so that the accuracy and generalization of the proposed method could be evaluated more objectively and fairly.
For the network con figuration, we adopted 4 hidden layers with 1024 nodes in all the networks used in the proposed and referential systems, and all the weights were trained by using a stochastic gradient descent algorithm.The RBM-based pre-training method [23] was introduced for more stable performance, and the number of epoch and the learning rate for pre-training was set to 10 and 0.0005. For further fine-tuning, the number of epoch, learning rate, the momentum rate, and mini-batch size were set to 30, 0.1, 0.9, and 128, respectively.In addition, the batch normalization [24] was also adopted for each hidden layer.
4.2 Objective measurement
The objective quality of the enhanced speech signals was evaluated in terms of LSD and PESQ scores.
LSD between the clean and enhanced speech signals was selected as the objective measurement for comparing the enhancement performance between the proposed and referential methods. LSD measurement is computed directly from the FFT power spectra as,
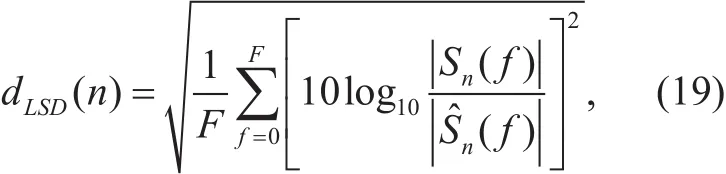
where dLSD(n) is the LSD value of the nth frame, and |Sn(f)| andare the amplitude spectra of the clean and enhanced speech signal, respectively. F is the number of frequency bins. Before computing the LSD values, all the data needed to be temporally aligned. The resulting LSD values were averaged over all the frames for each test samples and the mean LSD was used as the distortion measure. Table 1 shows the LSD values of the speech signals enhanced by the proposed and referential methods with different SNR conditions. The proposed SANM-DNN method obtained better performance than the referential Direct DNN method in terms of LSD measure, but was inferior to the SANM-DNN-TM method which adopts the true speech spectrum in the SANM algorithm. In addition, in different SNR condition, SANM-DNN-TM exhibits the slight difference of LSD measure. This indicates the performance of wind noise spectrum estimator is not significantly degraded by the SNR condition, and if we can achieve a better speech spectrum estimator in the low SNR condition the WNR method based on SANM will exhibit more powerful ability to reduce the noise component.
PESQ is widely adopted as an objective measure for evaluating the perceptual quality of speech signal, and exhibits a high correla-tion with subjective evaluation scores. PESQ scores is calculated by comparing the enhanced speech with the clean speech and ranges from -0.5 to 4.5. The higher PESQ scores,the less artifacts for the enhanced speech.Table 2 shows the PESQ scores of the speech signals enhanced by the proposed and referential methods with different SNR conditions.Similar to the result of LSD measure, for all the SNR conditions, the proposed SANMDNN method obtained higher scores of PESQ than the referential Direct DNN method, but was inferior to the SANM-DNN-TM method.
4.3 Spectrogram analysis
In addition, the performance of the proposed SANM-DNN method, the referential Direct DNN method, and the SANM-DNN-TM method was further compared in terms of spectrogram analysis. The selected test signal was a clip of female speech with the length of almost 5 s. The spectrograms of clean speech,noisy speech with the SNR of 0dB, the enhanced speech by different WNR methods were illustrated in figure 2. It can be found that the wind noise is dominant at the low-frequency region and corrupts the voiced segment of original speech. The referential Direct DNN method can effectively enhance the speech components and restore some harmonic structure from the noisy speech, but some residual wind noise remains between the low-frequency harmonics and leads to audible artifacts. By using the proposed SANM-DNN method, the residual wind noise is further suppressed. It is noteworthy that since the true speech spectrum is adopted in the SANM algorithm to suppress the wind noise, the SANM-DNN-TM method can restore the speech spectrum more accurately.
4.4 Subjective preference tests
The subjective quality of the proposed SANMDNN method and referential Direct DNN method was assessed by using the pair-wise subjective preference tests. The subjective tests were arranged in a quiet room, and 10 listeners were invited to take part in the tests.Three utterances of noisy speech were selected from the test dataset for each SNR condition.The listeners were asked to choose which signal they preferred from two presented test items or to indicate no preference in each test case. They were also allowed to repeat the test samples with no time limitation before giving answers. The results of the subjective tests are shown in table 3. It is found that the signalsenhanced by the proposed SANM-DNN method are preferable over the signals enhanced by the Direct DNN method in terms of subjective listening quality. In addition, some listeners provided the comments that the enhanced speech by the proposed method sounded more subjectively comfortable although some remaining noise still can be perceived in the low-SNR conditions.

Table I. LSD values of the enhance speech signals.
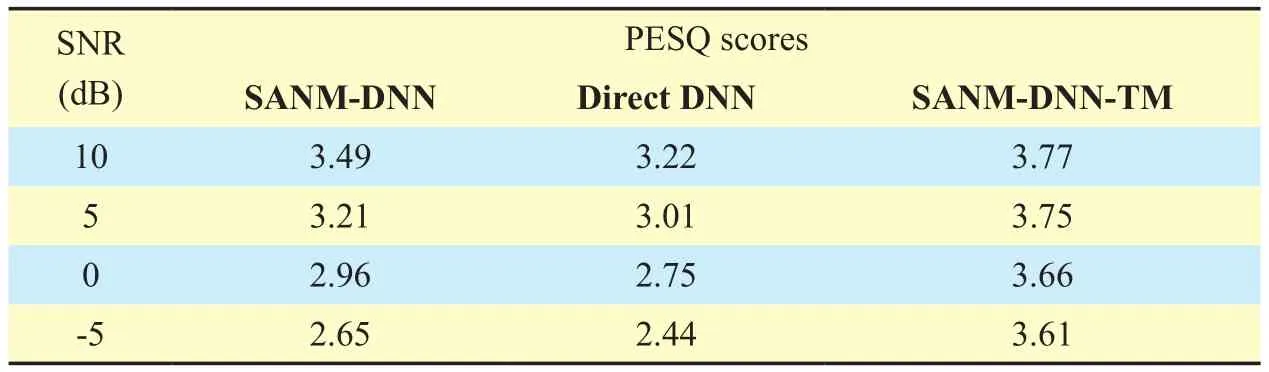
Table II. PESQ scores of the enhance speech signals.
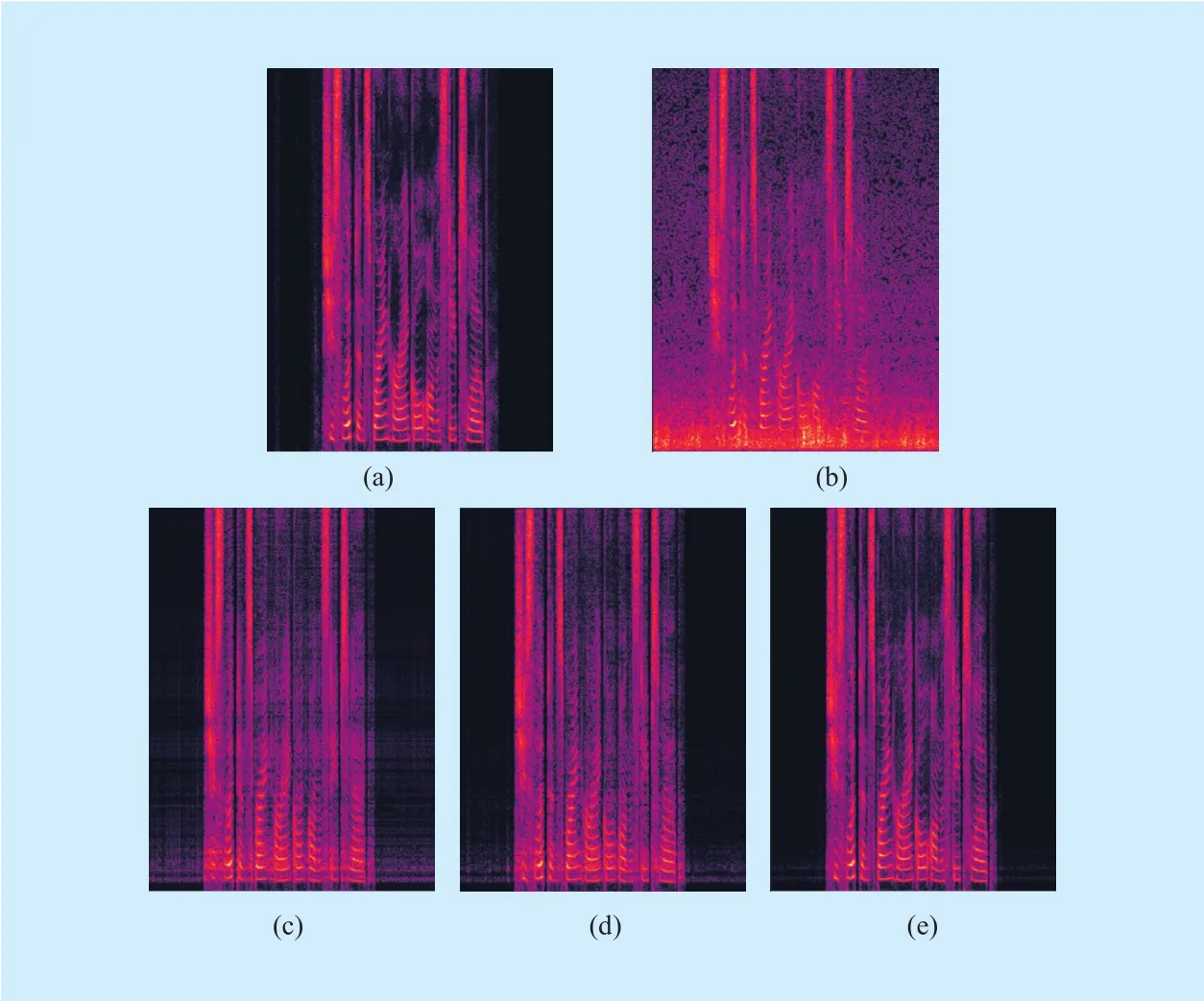
Fig. 2. Spectrograms of the speech signals.
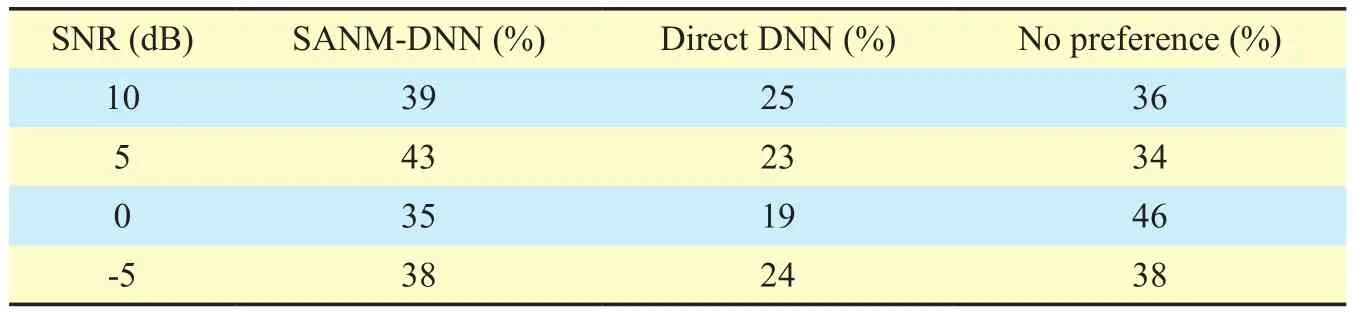
Table III. Results of the subjective preference tests.
V. CONCLUSION
In this paper, we proposed a DNN-based speech enhancement framework for WNR using the soft audible noise masking. A psychoacoustic model was employed to compute the masking threshold from the estimated speech spectrum, and the SANM principle was brought into the spectral weighting algorithm by using the masking threshold and estimated wind noise spectrum. To deal with the rapidly time-varying signals, both of the speech and noise spectra were estimated based on deep neural networks. The objective and subjective evaluation results show that the proposed WNR framework improves the performance compared with the conventional DNN-based WNR methods.
ACKNOWLEDGEMENT
This work is partially supported by the National Natural Science Foundation of China(Nos.11590772, 11590770), the Pre-research Project for Equipment of General Information System (No.JZX2017-0994/Y306).

- China Communications的其它文章
- Delay-Based Cross-Layer QoS Scheme for Video Streaming in Wireless Ad Hoc Networks
- An MAC Layer Aware Pseudonym (MAP) Scheme for the Software De fined Internet of Vehicles
- Asymptotic Analysis for Low-Resolution Massive MIMO Systems with MMSE Receiver
- Golay Pair Aided Timing Synchronization Algorithm for Distributed MIMO-OFDM System
- Joint Non-Orthogonal Multiple Access (NOMA) &Walsh-Hadamard Transform: Enhancing the Receiver Performance
- 8-Weighted-Type Fractional Fourier Transform Based Three-Branch Transmission Method