
Rough set-based rule generation and Apriori-based rule generation from table data sets II:SQL-based environment for rule generation and decision support
2019-12-20 02:40:14HiroshiSakaiZhiwenJian
Hiroshi Sakai ?, Zhiwen Jian
Graduate School of Engineering, Kyushu Institute of Technology, Sensui 1-1, Tobata, Kitakyushu 804-8550, Japan
Abstract: This study follows the previous study entitled ‘Rough set-based rule generation and Apriori-based rule generation from table data sets: A survey and a combination’, and this is the second study on ‘Rough set-based rule generation and Apriori-based rule generation from table data sets’. The theoretical aspects are described in the previous study, and here the aspects of application, an SQL-based environment for rule generation and decision support, are described. At first, the implementation of rule generator defined in the previous study is explained,then the application of the obtained rules to decision support is considered. Especially, the following two issues are focused on, (i) Rule generator from table data sets with uncertainty in SQL, (ii) The manipulation in decision support below: (ii-a) In the case that an obtained rule matches the condition, (ii-b) In the case that any obtained rule does not match the condition. The authors connect such cases with decision support and realised an effective decision support environment in SQL.
1 Introduction
Recently, there are several table data sets that store instances of previous occurrences.Data mining techniques allow us to investigate instances in table data sets, and we know trends and characteristics of data sets. In addition, rule-based decision support seems to be a very active research field. In fact, we found over 7700 papers from the Scopus system [1] by a keyword ‘rule-based decision support’.The Scopus system also responded the amount of papers in some research areas, and we had the following composition ratios, 35%in computer science, 24% in engineering, 13% in medicine, and 11% in mathematics, 5% for decision-making science, 5% for social science,4%for business and management,3%for biological science etc. In these papers, fuzzy sets and rough sets seem to be very important.
Several fuzzy frameworks are proposed in [2–8], and rough setbased frameworks are also proposed in [9–14]. The authors in this paper also developed a rough set-based framework, and termed it rough sets non-deterministic information analysis (RNIA) [15–17].RNIA is a framework for handling not only tables with definite information (which we term DISs: Deterministic Information Systems) but also tables with indefinite information (which we term NISs: Non-deterministic Information Systems). NIS was proposed by Pawlak [12] and Or?owska and Pawlak [18] for handling information incompleteness.
When NIS was proposed, the research purpose was to establish effective question-answering from tables with information incompleteness. However, we are here focusing on rule generation from NISs and decision support based on the obtained rules.RNIA framework maintains logical aspects. In other words,the core rule generation algorithm termed the NIS-Apriori algorithm [16, 19] is sound and complete [20, 21] for minimal rules. Therefore, this algorithm does not miss any minimal rule.Any minimal rule is certainly generated by this algorithm. This is assured theoretically. There seems less data mining algorithm with such logical properties.
In the RNIA framework, we define certain rules and possible rules based on possible world semantics [20, 21]. These definitions seem to be natural and standard, but the amount of possible worlds may exceed 10100in the Mammographic data set and the Congressional Voting data set [22]. It will be impossible to examine the constraints depending upon more than 10100cases sequentially. Even though this examination seems to be difficult,the NIS-Apriori algorithm provides a solution to this problem.Namely this algorithm is independent from the amount of the possible worlds [15, 16]. Without such property, it will be hard to compute rules defined by the possible world semantics.
The main issue in this paper is to propose three phases(i),(ii),(iii)in Figs. 1 and 2 and its prototype system in SQL.
(i)Rule generation phase:We specify two threshold values α and β and generate rules. We will know the trends and characteristics of the data set. Theoretical discussion and the novelty about rule generation phase are described in the twinned paper [23], and we trace rule generation process by using the Lenses data set in UCI machine-learning repository [22] for showing the overall flow.
(ii)Search phase for the obtained rules:For the specified condition part,if a rule matches the specified condition part,we have the rule’s decision part as the decision.(Since we usually consider β >0.5 as a constraint, we have one decision for the specified condition part.)(iii) Question-answering phase: If there is no rule with the same condition part, all implications with the condition part are searched, and we conclude one decision from the searched results with support(τ) and accuracy(τ).
If phase (ii) is applicable to the specified condition part, the execution of decision making is much faster than the execution in phase (iii). Therefore, it is useful to apply phase (ii), but there is a possibility that there is no rule which matches the specified condition part. Therefore, it is necessary to prepare phase (iii).Phase (iii) may take time to execute, but this phase responds all implications with the specified condition part and support(τ),accuracy(τ) values. That is all information for decision making from the table data set.
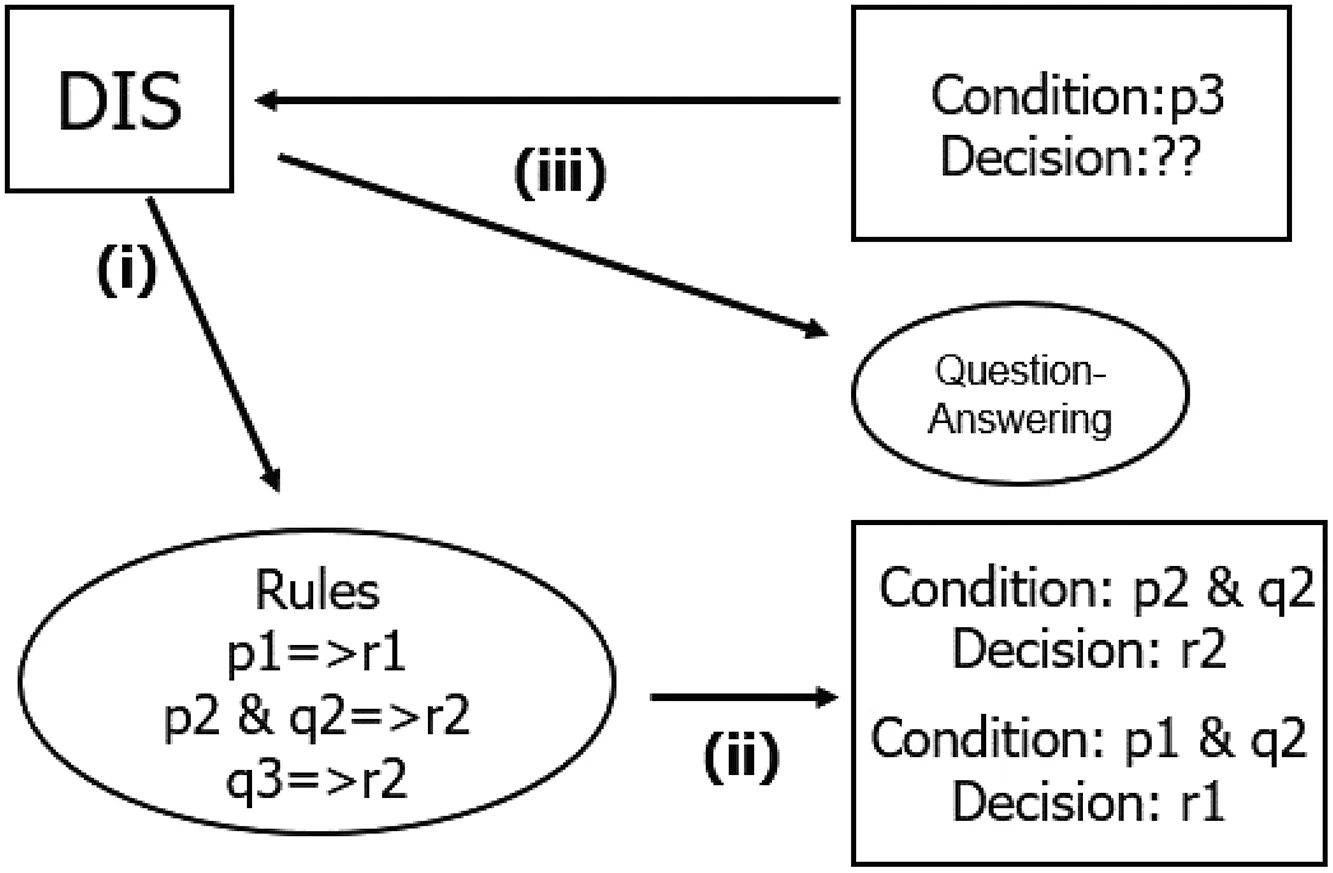
Fig. 1 Chart of three phases in decision support inDIS

Fig. 2 Chart of three phases in decision support in NIS
This paper is twinned with the previous paper entitled ‘Rough set-based rule generation and Apriori-based rule generation from table data sets: A survey and a combination’ [23]. Thus, in order to avoid the duplication, we may omit some definitions and issues in this paper. We will mainly describe the rule generator in SQL and the application of the obtained rules to decision support. This paper is organised as follows: Section 2 describes rules and the rule generator in DISs, and Section 3 describes rules and the rule generator in NISs. Section 4 clarifies the problem on decision support functionality in DISs and NISs, and investigates decision support procedures in SQL. Section 5 concludes this paper.
2 Rules from DISs and rule generator in SQL
This section focuses on rule generation from DISs. We especially handle the Lenses data set as an example of DIS.
2.1 Rules from DISs
The Lenses data set stores the symptoms on eyes and diagnosis for patients. This table data set consists of 24 objects (tuples), four attributes: age, spec, asti, and tear, one decision attribute class with three attribute values 1 (hard contact lenses), 2 (soft contact lenses), and 3 (no contact lenses).
Each attribute value can be regarded as a classified value; so, it may be difficult to consider the variance of the average value or statistics. With such a table data set, we will consider rule-based decision support. The Lenses data set in Fig. 3 is an example of DIS, and each attribute value is one value. There is no missing value [24].
A pair [A,valA] (an attribute A and its attribute value valA) is called a descriptor. For the decision attribute Dec and a set CON of condition attributes, we term a formula τ:∧A∈CON[A,valA]?[Dec,val] an implication. For specified threshold values 0 <α,β ≤1, we say τ is (a candidate of) a rule, if τ satisfies the next two criterion values [6, 10, 13, 25].

Fig. 3 Some instances of the Lenses data set
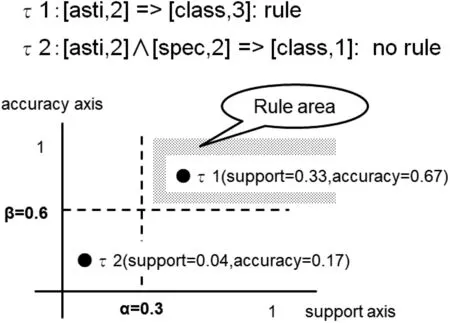
Fig.4 Rules(defined by support ≥0.3 and accuracy ≥0.6)plotted in the plane
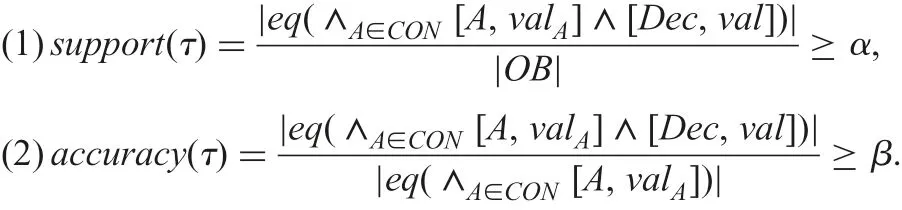
Here, OB is a set of objects, eq(?) is an equivalence class defined by the formula ?, and |?| is the cardinality of a set ?. If|eq(∧A∈CON[A,valA])|=0, we define both support(τ)=0 and accuracy(τ)=0. For an implication τ1:[asti,2]?[class,3] in Fig. 4,
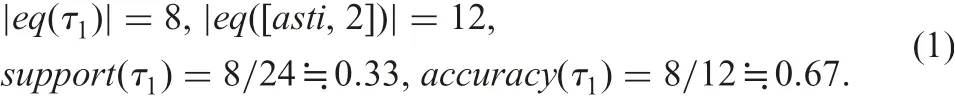
Since τ1is located in the rule area,we see this τ1is a candidate of a rule. Similarly, for an implication τ2:[asti,2]∧[spec,2]?[class,1],

As for τ2, it is not located in the rule area; so, we see it is not a candidate of a rule. The support(τ) value means the occurrence ratio of the implication τ. If τ occurs frequently, this τ is reliable.On the other hand, the accuracy(τ) value means the consistency ratio of τ. If the accuracy(τ) value is higher, this τ is more reliable, too.
2.2 Rule generator in SQL for DISs
We employed the DIS-Apriori algorithm,which is closely described in the twinned paper. In this sub-section, we trace the following procedure apriv2 by using the Lenses data set. This trace will be useful explanation of rule generation.
In each table data set,the number of attribute values and the names of attribute are different.We at first translate each table to a table of the rdf format[26–28].Fig.5 shows a part of the rdf table.In this rdf table, each attribute name is handled as a value instead of attribute name. In SQL procedure, we need to specify conditions by using attribute names. So, if we employ the original table directly, the procedure depends upon such attribute names. Namely, we need one procedure for each original table. However, in the rdf table we can employ only three fixed attribute names, i.e. object, attrib, and value. Actually, we implemented the DIS-Apriori algorithm in SQL by using this rdf table. We termed this procedure apriv2 and tapri below:

Fig. 5 Part of the rdf table from the Lenses data set
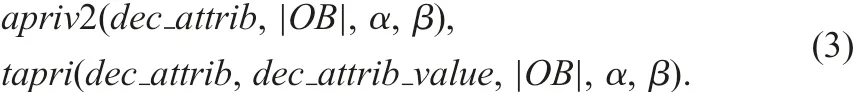
In the procedure tapri, we can specify a decision attribute value(a target attribute value). Fig. 6 is the process of rule generation.We execute a procedure by ‘call procedure_name’ statement in the SQL prompt ‘mysql>’. The lenses_rdf procedure generates an rdf table, and apriv2 generates tables. Rules are stored in tables rule1, rule2, and rule3, and some temporary tables are remained.In the following, we describe the role of some temporary tables.
Now, we trace the execution by using the Lenses data set. The apriv2 procedure takes three steps.
DIS_Step 1) Generation of tables con1, deci, rule1, and rest1.In the table rule1, each rule in the form of [A,a]?[Dec,val] is stored.
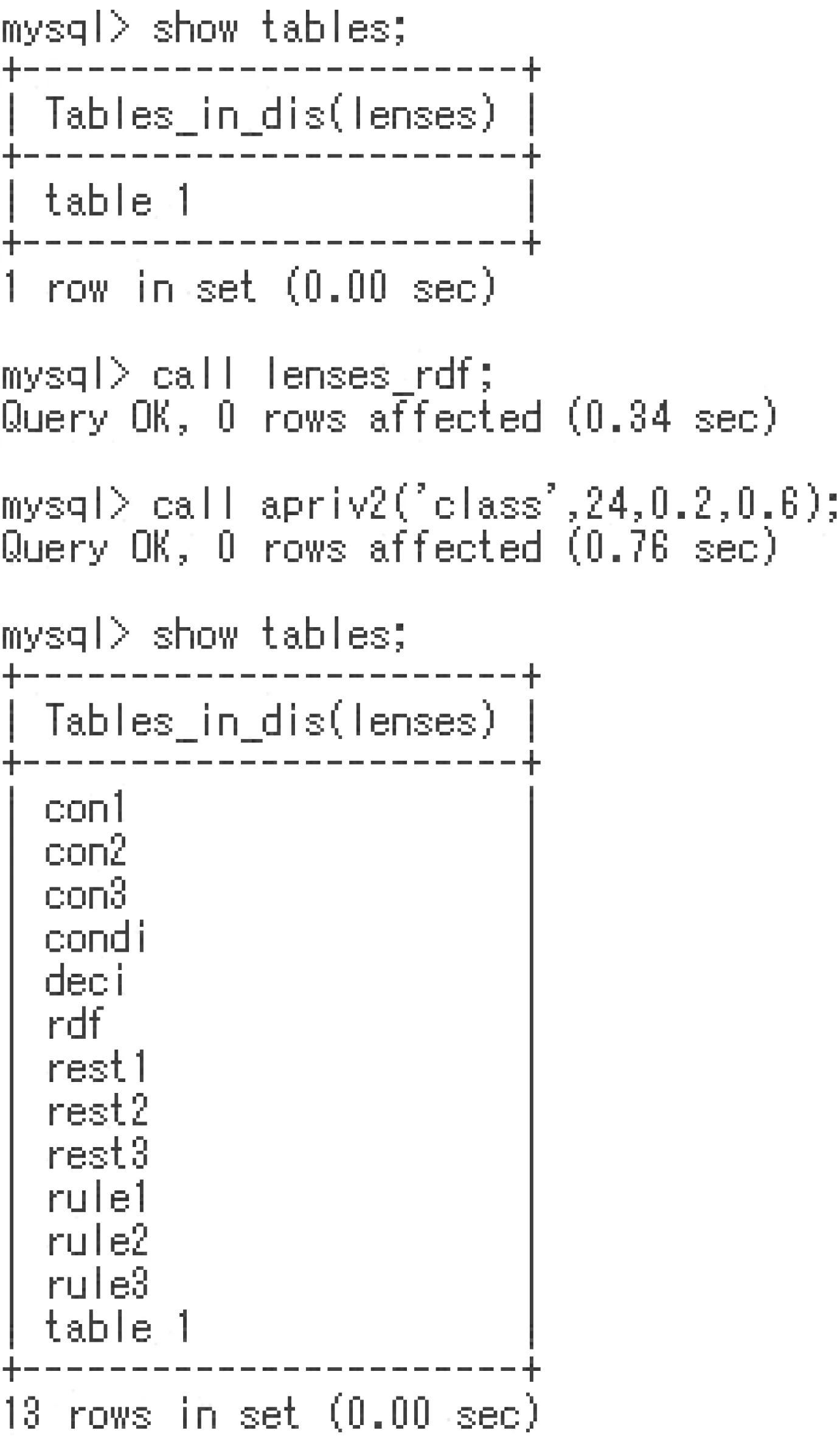
Fig. 6 Process of rule generation (support(τ)≥0.2 and accuracy(τ)≥0.6)
DIS_Step 2)Generation of tables con2,rule2,and rest2.In the table rule2,each minimal rule in the form of[A,a]∧[B,b]?[Dec,val]is stored.
DIS_Step 3) Generation of tables con3, rule3, and rest3. In the table rule3, each minimal rule in the form of [A,a]∧[B,b]∧[C,c]?[Dec,val] is stored.
In DIS_Step 1, apriv2 generates the table con1 in Fig. 7. The condition descriptors satisfying support ≥α are stored in the table con1. The total number |OB|=24 and α=0.2 are specified; so,if a descriptor occurs more than five (≥24×0.2=4.8) times,this descriptor satisfies the constraint support ≥α. Thus, apriv2 handles such a descriptor, and we say such a descriptor is a considerable descriptor. The apriv2 procedure ignores other descriptor whose occurrence is less than four times. Actually, the descriptor [class, 1] occurs four times, and [class, 1] is not stored in the table deci. Therefore, we have no rule whose decision part is [class, 1].
The apriv2 procedure combines each descriptor in tables con1 and deci, and examines 18 (=9×2) implications. If an implication τ satisfies the constraint, this τ is added to the table rule1. If τ satisfies support(τ)≥0.2 and accuracy(τ)<0.6, this τ is added to the table rest1 in Fig. 8. We say such an implication is a considerable implication.
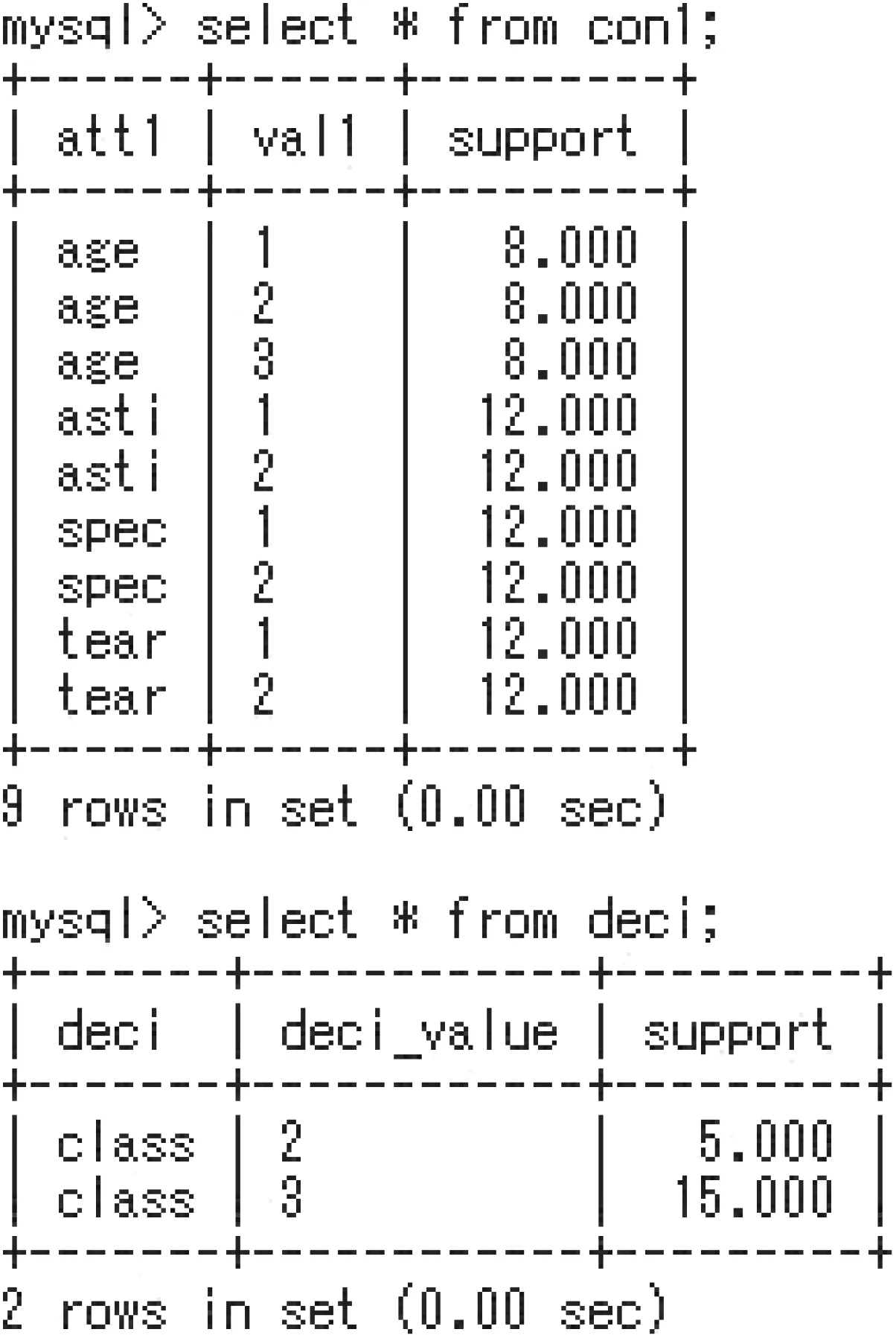
Fig.7 Considerable descriptors in con1 and deci.Each descriptor occurs more than five times
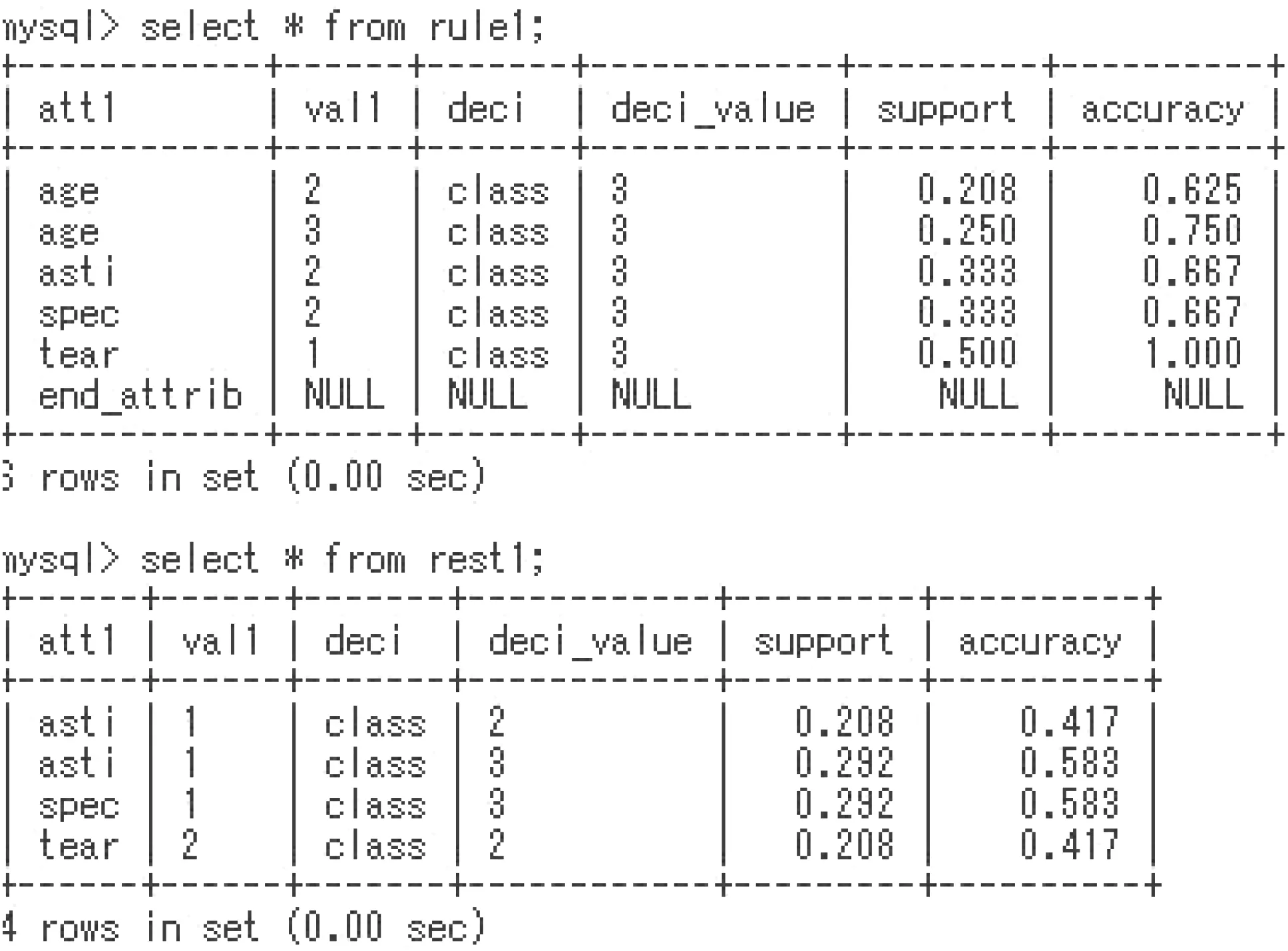
Fig.8 Obtained rules and four considerable implications in the table rest1
In DIS_Step 2, apriv2 picks up considerable implications in rest1 and generates considerable implications in con2. Similarly,apriv2 generates two tables rule2 and rest2 in Fig. 9. Since rest2 is empty, the rule generation process substantially finishes in this step.
As we have described in the twinned paper, there is no missing minimal rule by the procedure apriv2. We had totally 6 implications satisfying support(τ)≥0.2 and accuracy(τ)≥0.6.Fig.10 is a part of apriv2 in SQL.This part generates the table rule1.
3 Rules from NISs and rule generator in SQL
This section focuses on rule generation from NISs. We especially handle the Credit Approval data set in UCI machine learning repository [22] as an example of NIS.
3.1 Rules from NISs
This table data set consists of 690 objects (tuples), 15 attributes:a1, a3, ..., a15, one decision attribute a16with two attribute values 1 and 2.
In the Credit Approval data set, there are 67 missing values expressed by the ‘?’ symbol in Fig. 11. The criterion values support(τ) and accuracy(τ) are affected by the value assigned to‘?’ symbol [15, 24]. Of course, rules depend upon the missing values; so, rule generation from such table data sets [11, 12, 18,21] is different from rule generation from DISs. We have dealt with this problem in RNIA.

Fig. 9 Considerable implications in con2, rule2, and rest2

Fig. 10 Part of the procedure for generating the table rule1
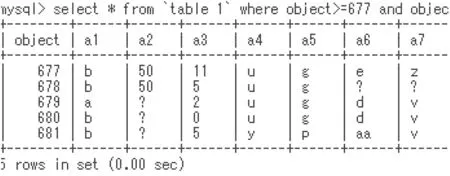
Fig. 11 Part of instances in the Credit Approval data set
We introduced the concept of derived DISs to NIS.If we replace each ‘?’ symbol with a possible value, then we have one DIS. We termed such a DIS a derived DIS. An example of NIS and derived DISs is given in the twinned paper [23]. We employ the usual definition of a rule in DIS [13], and extended it to a certain rule and a possible rule in NIS below [15, 16]:
A rule in DIS) An implication τ is a rule in DIS, if τ satisfies support(τ)≥α and accuracy(τ)≥β for the given α and β.
A certain rule in NIS)An implication τ is a certain rule,if τ is a rule in each derived DIS from NIS for the given α and β.
A possible rule in NIS) An implication τ is a possible rule, if τ is a rule in at least one derived DIS from NIS for the given α and β.
Generally, it will be hard to generate certain rules and possible rules, if there are a huge number of possible worlds.In the Mammographic data set, the number of possible worlds exceeds 10100. However, we have proved the following [16, 19]and described them in the twinned paper.
(i) There exists a derived DIS which causes both the support(τ)value and the accuracy(τ) value to be minimum. We term such values minsupp and minacc for τ.
(ii) There exists a derived DIS which causes both the support(τ)value and the accuracy(τ) value to be maximum. We term such values maxsupp and maxacc for τ.
(iii) There is a method, which does not depend upon the amount of possible worlds, to calculate minsupp, minacc, maxsupp, and maxacc for τ. The formulas are in the twinned paper.
(iv) An implication τ is a certain rule if and only if minsupp(τ)≥α and minacc(τ)≥β.An implication τ is a possible rule if and only if maxsupp(τ)≥α and maxacc(τ)≥β.
(v) The complexity of NIS-Apriori is more than twice of complexities (or linear-order time complexity) of the DIS-Apriori algorithm. Since the DIS-Apriori algorithm is an adjusted Apriori algorithm, the NIS-Apriori algorithm will be linear-order time complexity of the Apriori algorithm by Agrawal. Even though the NIS-Apriori algorithm can handle rules defined by possible worlds, which increase exponentially, the NIS-Apriori algorithm can escape from the exponential time-order complexity.
In the subsequent sections, we employ the above results and realise a rule generator from NISs. Furthermore, we realise some decision support procedures by using the obtained rules.
3.2 Rule generator in SQL for NISs
For rule generation from NISs, we realised procedures step1, step2,and step3 below:

In step1, the DIS-Apriori algorithm with the minsupp and minacc values is called for certain rule generation, and then the DIS-Apriori algorithm with the maxsupp and maxacc values is called for possible rule generation. In step2 and step3, the similar procedure is executed. Fig. 12 shows the generated tables. Tables c??store certain rules and tables p??store possible rules. Fig. 13 shows certain rules in c1rule and possible rules in p2rule. In the procedure tstep?, we can specify a decision attribute value (a target attribute value).

Fig. 12 Generated tables by procedures step?
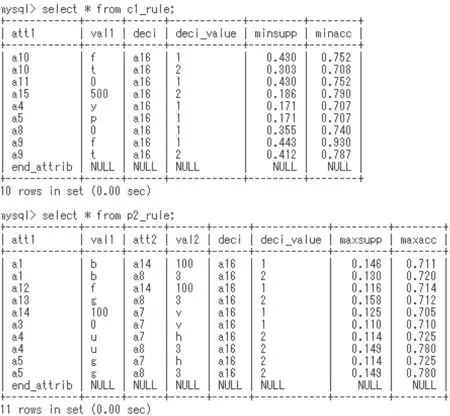
Fig. 13 Generated minimal rules (support(τ)≥0.1, accuracy(τ)≥0.7)from the Credit Approval data set
4 Decision support environment in SQL
In Sections 2 3, we described rule generator for DISs and NISs,respectively, and clarified phase (i) in Figs. 1 and 2. This section considers phases (ii) and (iii) in Figs. 1 and 2, namely the environment for decision support by the obtained rules.
4.1 Redundancy between rules
We say that an implication A ∧B ?C is redundant to the implication A ?C. After obtaining rules, we see them logical implications in propositional logic. If A ?C holds, A ∧B ?C automatically holds, because (A ∧B ?C) = (A ?C)∨(B ?C).Thus, we see (A ∧B ?C) is a rule, if A ?C is recognised as a rule. (If we consider large numbers of descriptors in the condition part, the constraint support ≥α may not be satisfied. So,actually such an implication may not be a rule.) We employ this redundancy concept, and generate rules with the minimal condition part (minimal complex) in [24]. Otherwise, there will be large numbers of redundant rules to one rule, like A ∧B ?C,A ∧D ?C, A ∧E ?C, ..., to a rule A ?C. We are interested in rules with minimal condition part.

Fig. 14 Application of sd_rule1 and sd_rule2 to the Lenses data set. The first line in the table means the query,and the number 999.000 is meaningless
In Fig.14, an implication [tear,1]?[class,3]is a rule, and we automatically see(any descriptor)∧[tear,1]?[class,3]is a rule.In decision support, we need to pay attention to this redundancy.
4.2 Decision support environment for DISs: phase (ii)
For decision support in DISs, we realised procedures sd_rule1,sd_rule2, and sd_rule3 below:
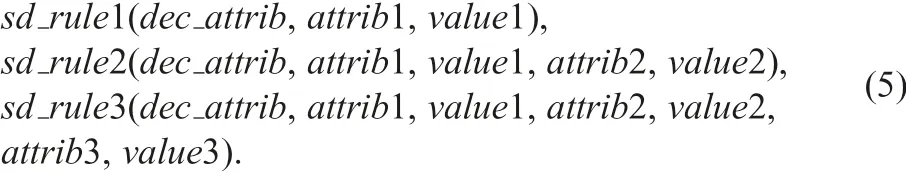
These procedures search rules stored in tables rule1, rule2, and rule3. Let us consider Figs. 6 and 8. For such tables, we apply sd_rule1 and sd_rule2 in Fig. 14.
The first query is ‘to decide decision for [tear, 1] by the obtained rules’. Since τ:[tear,1]?[class,3] is stored in rule1,the decision [class, 3] is obtained by using τ. The second query is ‘to decide decision for [spec,1]∧[tear,1] by the obtained rules’. In this case, τ′:[spec,1]∧[tear,1]?[class,3] is redundant to τ; so, the decision by τ is obtained. In rule2, there is no rule with [spec,1]∧[tear,1] as the condition part.
The role of the described procedures may not be important for small number of rules. However, if we employ lower α and lower β values,we have large number of rules.To examine the constraints manually seems to be ineffective.In such case,the realised sd_rule1,sd_rule2, and sd_rule3 become very important.
4.3 Decision support environment for NISs: phase (ii)
For decision support in NISs, we realised procedures sn_rule1,sn_rule2, and sn_rule3 below:
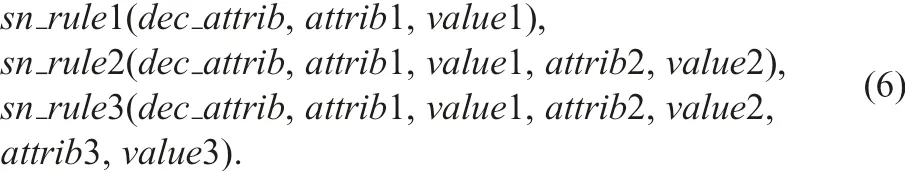
The procedures sn rule1,sn rule2,and snrule3 are almost the same procedures of sd rule1, sd rule2, and sdrule3. Three procedures search rules stored in tables c1rule, c2rule, c3rule, p1rule,p2rule, and p3rule. Let us consider Figs. 12 and 13. For such tables, we apply snrule1 and snrule2 in Fig. 15.

Fig. 15 Application of sn rule1 and sn rule2 to the Credit Approval data set. The first line in the table means the query
The first query is ‘to decide decision for [a5,p] by the obtained rules’. Since τ:[a5,p]?[a16,1] is stored in c1rule and p1rule, the decision [a16,1] is obtained by using τ. We know the degree of τ by minsupp(τ), minacc(τ), maxsupp(τ), and maxacc(τ). The second query is ‘to decide decision for[a5,g]∧[a7,h] by the obtained rules’. In this case, rules with[a5,g] and [a7,h] are not stored in c1rule nor p1rule, and a rule with [a5,g]∧[a7,h] is stored in p2rule. Even though the support value may not be enough, we will probably conclude[a16,2].
Like this, the proposed and implemented procedures will be effective for decision support. The procedures search the obtained rules in tables; so, it takes less execution time. However, if the condition does not match the obtained rules, we have no information for the condition.
4.4 Decision support environment for DISs: phase (iii)
In order to recover the case that the condition does not match the obtained rules in DISs, we implemented the procedures srdf 1,srdf 2, and srdf 3 below:
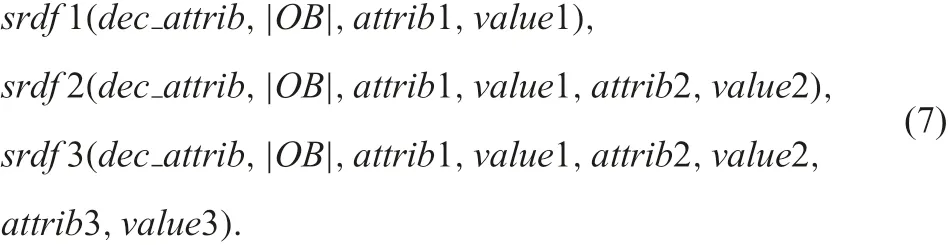
Each procedure in the formulas (7) searches the rdf table instead of tables with the obtained rules. Therefore, it takes more execution time than that by sd rule1, sd rule2, and sdrule3. However, we have all information about the specified condition.
In Fig.16,the procedure sdrule2 is executed at first,and we have no information on the condition [age,1]∧[spec,1]. Namely, any implication related to [age,1]∧[spec,1]?[class,val] is not stored in rule1 nor rule2. In this case, we execute srdf 2 procedure,and have the table srdf 2.This is all information about the condition[age,1]∧[spec,1]. Criterion values are not so characteristic,but if necessary we will probably have the decision [class,3].
4.5 Decision support environment for NISs: phase (iii)
Similarly to the previous subsection,we implemented the procedures snrdf 1, snrdf 2, and snrdf 3. Each procedure in the formulas (8)searches the nrdf table instead of tables with the obtained rules.Therefore, it takes more execution time than that by sn rule1,sn rule2, and snrule3. However, we have all information about the implication with the specified condition.
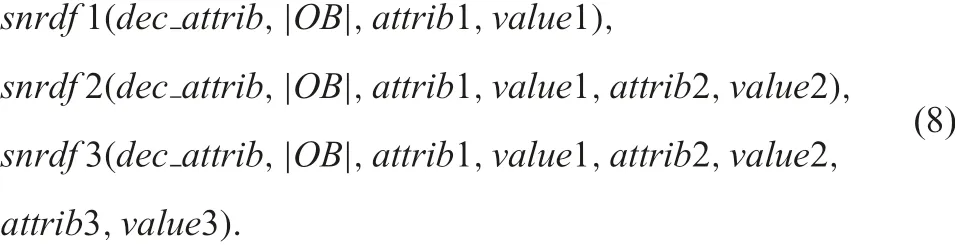

Fig. 16 Application of sd rule2 and srdf 2 to the Lenses data set
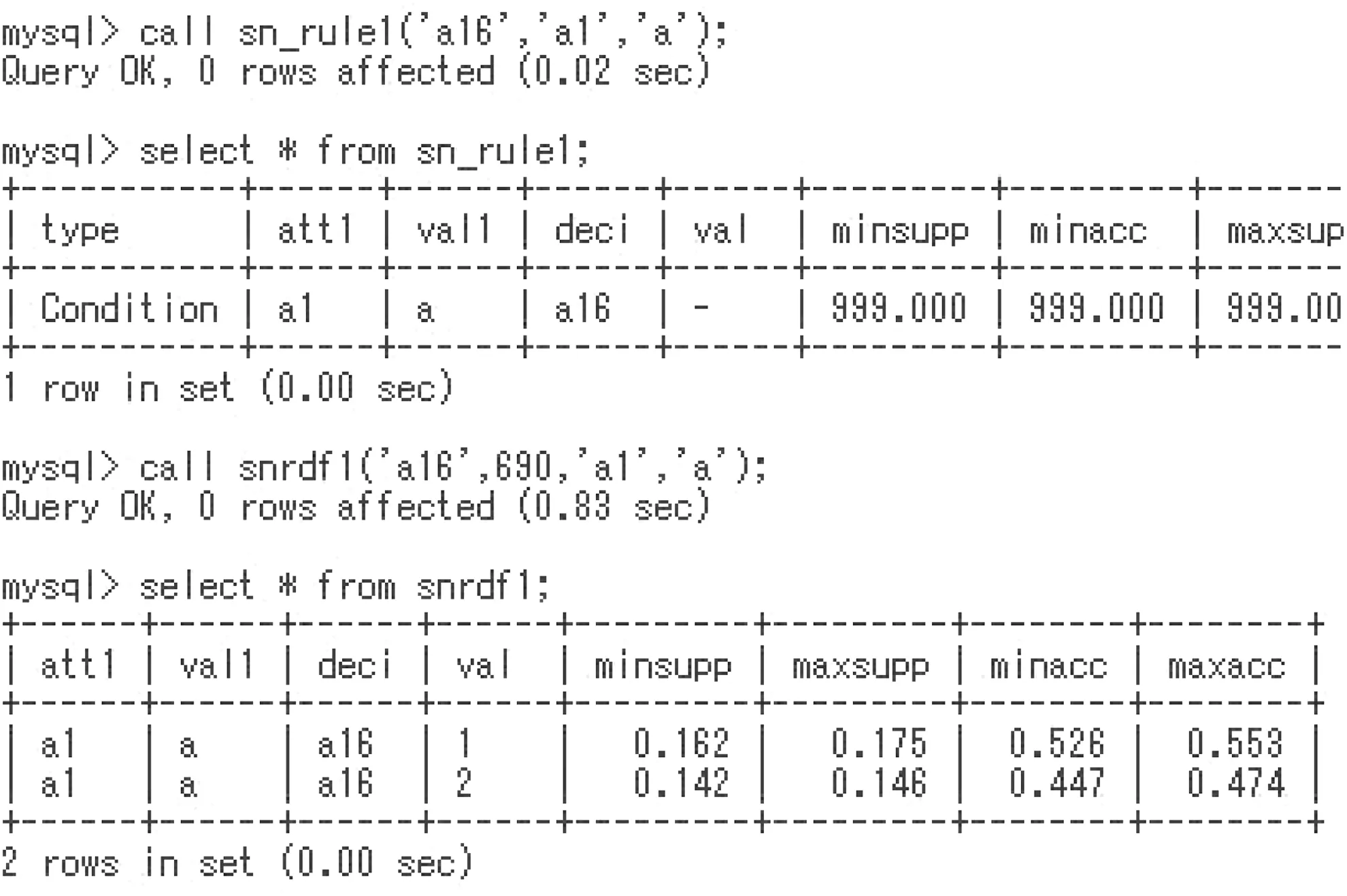
Fig.17 Application of sn rule1 and snrdf 1 to the Credit Approval data set
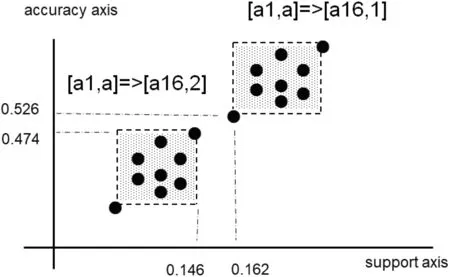
Fig. 18 Locations of the implications plotted in the plane
In Fig. 17, the procedure snrule1 is executed at first, and we have no information on the condition [a1,a]. Namely, any rule[a1,a]?[class,val] is not stored in c1rule nor p1rule. In this case, we execute snrdf1 procedure, and have the table snrdf1. This is all information about the condition [a1,a]. Criterion values are not so characteristic,but we will probably have the decision[a16,1].
Fig.18 shows the relation on two implications in the table snrdf1.In this case, the following holds:
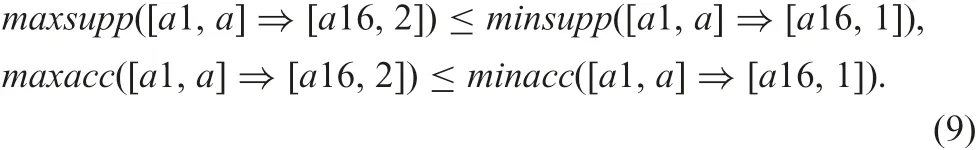
Even though they do not satisfy the constraint of a rule,[a1,a]?[a16,1] takes better criterion values in any possible case. Thus, we will have a decision [a16,1], if we need to have one decision.
4.6 Decision support in DISs: A case of the phishing data set
This subsection shows an example on the Web Phishing data set in UCI machine learning repository [22]. This data set stores characteristics of web sites. This data set consists of 1353 objects,9 condition attributes, and one decision attribute Result with three attribute values 1 (Legitimate), 0 (Suspicious), -1 (Phishy). The apriv2 procedure generated 21 rules for support(τ)≥0.1 and accuracy(τ)≥0.7. It took about 400 s. Fig. 19 shows decision support by using the obtained results.
In Fig. 19, the table srdf2 shows all cases for the condition[URLof Anchor,1]∧[webtraffic, -1]. The sum of accuracy values is 1. From srdf2, we will have the decision [Result, -1](Phishy). In sdrule2, this implication is stored as a rule.
4.7 Decision support in NISs: A case of the congressional voting data set
This subsection shows an example on the Congressional Voting data set. This data set stores congressional voting in US congress. This data set consists of 435 objects, 16 condition attributes, and one decision attribute a1 whose attribute values are rep(ublic) political party and dem(ocrat) political party.
The step1 procedure generated 18 certain rules in c1rule and 21 possible rules in p1rule for support(τ)≥0.3 and accuracy(τ)≥0.7. It took 18.71 s. Similarly, step2 did two certain rules in c2rule and eight possible rules in p2rule. It took 17.43 s. No rule was generated by step3. The certain rules satisfy support(τ)≥0.3 and accuracy(τ)≥0.7 for each of more than 10100derived DISs. Especially, two certain rules [a5,n]?[a1,dem] and[a5,y]?[a1,rep] are very strong. If we have a person’s answer to the attribute a5, we will easily conclude his supporting party by using two tables in Fig. 20.
4.8 Discussion about the decision support functionality
We applied the implemented procedures to the obtained tables, and we had one curious case in Fig. 21. In Fig. 21, both [a12,f] and[a4,u] conclude [a16,1], but [a12,f]∧[a4,u] concludes[a16,2]. This seems to confuse us.
The reason was the definition of rule. The constraint was support(τ)≥0.2 and accuracy(τ)≥0.5, and the accuracy value seems to be lower. In possible rule generation, we calculate the maxacc(τ) value in the most suitable case for τ. Therefore,we have two inconsistent possible rules in Fig. 22, i.e.[a12,f]∧[a4,u]?[a16,1] (maxsupp=0.206, maxacc=0.504)and [a12,f]∧[a4,u]?[a16,2] (maxsupp=0.209, maxacc=0.507). This is not wrong, and such case may occur based on the definition of possible rules. Actually, we changed the condition to accuracy(τ)≥0.7, and such curious cases were solved.

Fig. 19 Application of sd rule2 and srdf 2 to the Web Phishing data set
In decision support, the application of phases (ii) and (iii) in Figs. 1 and 2 will be effective. In the RNIA framework, rules and decisions are evaluated by the criterion values support and accuracy. The proposed and implemented procedures provide all information on support(τ) and accuracy(τ). However, if there is less difference on the support and accuracy values like in Figs. 21 and 22, it may be difficult to have one decision. We may need other criterion values in such cases.

Fig.20 If his response is‘no’to the attribute a5,he will support democrat party.If his response is‘yes’to the attribute a5,he will support republic party
5 Concluding remarks
This paper clarified rule-based decision support in RNIA, and reported its prototype system in SQL. The definition of the certain rules and the possible rules seems to be natural, however there is less software tool for handling them, because the rules are defined by all derived DISs whose number may exceed 10100.Without effective property, it will be hard to obtain rules. The NIS-Apriori algorithm affords a solution to this problem, and we implemented the prototype termed NIS-Apriori in SQL. This algorithm takes the core part for handling the uncertainty, and we applied it to decision support environment. Rule generation and decision support based on NISs have not been investigated previously; therefore, each research related to the NIS-Apriori algorithm and NISs will be novel research.
In the application of the obtained rules, we proposed some procedures and implemented them in SQL. If we have large number of rules, it will be hard to examine phase (ii) in Figs. 1 and 2 manually. We gave a solution to this problem. Actually, to search tables with rules is less time-consuming, but we cannot have one decision for any condition always. Probably, in most case, we have no information. Thus, we realised procedures to search either rdf or ndrf tables. The implemented procedures will be effective for decision support.

Fig. 21 Curious case in the Credit Approval data set

Fig. 22 Application of snrdf1 and snrdf2 to the Credit Approval data set
This paper described the actual executions whose theoretical aspect was presented in the twinned previous paper entitled‘Rough set-based rule generation and Apriori-based rule generation from table data sets: A survey and a combination’.
6 References
[1] Elsevier, Scopus system. Available at https://www.scopus.com, accessed December 2018
[2] Dubois,D.,Prade,H.:‘Rough fuzzy sets and fuzzy rough sets’,Int.J.Gen.Syst.,1990, 17, (2–3), pp. 191–209
[3] Jensen,R.,Shen,Q.:‘Fuzzy-rough sets assisted attribute selection’,IEEE Trans.Fuzzy Syst., 2007, 15, (1), pp. 73–89
[4] Minutolo, A., Esposito, M., De Pietro, G.: ‘A fuzzy framework for encoding uncertainty in clinical decision-making’, Knowl.-Based Syst., 2016, 98,pp. 95–116
[5] Shen, K.Y., Sakai, H., Tzeng, G.H.: ‘Comparing two novel hybrid MRDM approaches to consumer credit scoring under uncertainty and fuzzy judgments’,Int. J. Fuzzy Syst., 2019, 21, (1), pp. 194–212
[6] Skowron, A., Rauszer, C.: ‘The discernibility matrices and functions in information systems’, in S?owiński, R. (Ed.): ‘Intelligent decision support –handbook of advances and applications of the rough set theory’ (Kluwer Academic Publishers, the Netherlands, 1992, 1st edn.), pp. 331–362
[7] Zadeh,L.:‘Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic’, Fuzzy Sets Syst., 1997, 90, (2), pp. 111–127
[8] Zarikas,V.,Papageorgiou,E.,Regner,P.:‘Bayesian network construction using a fuzzy rule based approach for medical decision support’,Expert Syst.,2016,32,(3), pp. 344–369
[9] Kadziński,M.,S?owiński,R.,Szelag,M.:‘Dominance-based rough set approach to multiple criteria ranking with sorting-specific preference information’,Studies in Comput. Intell., 2016, 606, pp. 55–171
[10] Komorowski,J.,Pawlak,Z.,Polkowski,L.,et al.:‘Rough sets:a tutorial’,in Pal,S.K.,Skowron,A.(Eds.):‘Rough fuzzy hybridization:a new method for decision making’ (Springer, German, 1999, 1st edn.), pp. 3–98
[11] Nakata, M., Sakai, H.: ‘Twofold rough approximations under incomplete information’, Int. J. Gen. Syst., 2013, 42, (6), pp. 546–571
[12] Pawlak, Z.: ‘Systemy informacyjne: podstawy teoretyczne (in Polish)’ (WNT Press, Poland, 1983, 1st edn.)
[13] Pawlak, Z.: ‘Rough sets: theoretical aspects of reasoning about data’ (Kluwer Academic Publishers, Dordrecht, The Netherlands, 1991, 1st edn.)
[14] Zhang,Q.,Xie,Q.,Wang,G.:‘A survey on rough set theory and its applications’,CAAI Trans. Intell. Tech., 2016, 1, (4), pp. 323–333
[15] Sakai, H., Ishibashi, R., Nakata, M.: ‘Rules and apriori algorithm in non-deterministic information systems’,Trans.Rough Sets,2008,9,pp.328–350
[16] Sakai, H., Wu, M., Nakata, M.: ‘Apriori-based rule generation in incomplete information databases and non-deterministic information systems’, Fundam.Inform., 2014, 130, (3), pp. 343–376
[17] Sakai, H.: ‘Software tools for RNIA (rough non-deterministic information analysis) web page’. http://www.mns.kyutech.ac.jp/sakai/RNIA/, accessed December 2018
[18] Or?owska, E., Pawlak, Z.: ‘Representation of nondeterministic information’,Theor. Comput. Sci., 1984, 29, (1–2), pp. 27–39
[19] Sakai, H., Nakata, M., Watada, J.: ‘NIS-Apriori-based rule generation with three-way decisions and its application system in SQL’, Inf. Sci., 2018 (online published https://doi.org/10.1016/j.ins.2018.09.008)
[20] Kripke, S.A.: ‘Semantical considerations on modal logic’, Acta Philosophica Fennica, 1963, 16, pp. 83–94
[21] Lipski, W.: ‘On semantic issues connected with incomplete information databases’, ACM Trans. Database Syst., 1979, 4, (3), pp. 262–296
[22] Frank, A., Asuncion, A.: ‘UCI machine learning repository’. University of California, School of Information and Computer Science, Irvine, CA. Available at http://mlearn.ics.uci.edu/MLRepository.html, accessed December 2018
[23] Sakai, H., Nakata, M.: ‘Rough set-based rule generation and apriori-based rule generation from table data sets: A survey and a combination’, CAAI Trans.Intell. Tech., 2019 (online published https://digital-library.theiet.org/content/journals/10.1049/trit.2019.0001)
[24] Grzyma?a-Busse, J.: ‘Data with missing attribute values: generalization of indiscernibility relation and rule induction’, Trans. Rough Sets, 2004, 1,pp. 78–95
[25] Agrawal, R., Srikant, R.: ‘Fast algorithms for mining association rules in large databases’. Proc. Int. Conf. VLDB’94, Chile, September 1994,pp. 487–499
[26] Kowalski, M., Stawicki, S.: ‘SQL-based heuristics for selected KDD tasks over large data sets’. Proc. FedCSIS, 2012, Wroclaw, Poland, September 2012,pp. 303–310
[27] ?le?zak, D., Sakai, H.: ‘Automatic extraction of decision rules from non-deterministic data systems: theoretical foundations and SQL-based implementation’. Proc. DTA2009 Springer CCIS, Jeju, Korea, December 2009,64, pp. 151–162
[28] Swieboda, W., Nguyen, S.: ‘Rough set methods for large and spare data in EAV format’. Proc. IEEE RIVF, Ho Chi Minh City, Viet Nam, February 2012,pp. 1–6
 CAAI Transactions on Intelligence Technology2019年4期
CAAI Transactions on Intelligence Technology2019年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Influence of kernel clustering on an RBFN
- Neighbourhood systems based attribute reduction in formal decision contexts
- Rule induction based on rough sets from information tables having continuous domains
- Fuzzy decision implications:interpretation within fuzzy decision context
- Survey on cloud model based similarity measure of uncertain concepts
- Rough set-based rule generation and Apriori-based rule generation from table data sets:a survey and a combination