
Rule induction based on rough sets from information tables having continuous domains
2019-12-20 02:41:58MichinoriNakataHiroshiSakaiKeitarouHara
Michinori Nakata ?, Hiroshi Sakai, Keitarou Hara
1Faculty of Management and Information Science, Josai International University, Gumyo, Togane, Chiba 283-0002, Japan
2Graduate School of Engineering, Kyushu Institute of Technology, Sensui 1-1, Tobata, Kitakyushu 804-8550, Japan
3Department of Informatics, Tokyo University of Information Sciences, 4-1 Onaridai, Wakaba-ku, Chiba 265-8501, Japan
Abstract:Information tables having continuous domains are handled by neighborhood rough sets.Two approximations in complete information tables are extended to handle incomplete information. Consequently, four approximations are obtained: certain and possible lower ones and certain and possible upper ones without computational complexity.These extended approximations create the same results as the ones from possible world semantics by using possible indiscernibility relations. Therefore, the extension is justified. In complete information tables two types of single rules that an object supports are obtained: consistent and inconsistent ones. The single rule has low applicability.To increase applicability, a series of single rules are brought into one combined rule with an interval value.In incomplete information tables four kinds of single rules are obtained. From them, four kinds of combined rules are obtained: certain and consistent, possible and consistent, certain and inconsistent, and possible inconsistent ones.A combined rule has higher applicability than the single rules from which it is assembled.
1 Introduction
We are required to cope with various types of data in computer science. When we focus on string data among them, data is broadly classified into discrete and continuous data. Rough sets,which Pawlak proposed [1], are used to bring out rules from data as an effective method. The framework is usually used to complete information tables with nominal attributes and produces lots of valuable results in many fields containing data mining and pattern recognition and so on. However, attributes with continuous values usually appear, when we describe objects in the real world.Furthermore, incomplete information ubiquitously exists in the real world. We cannot effectively utilise information generated in the real world if we do not deal with incomplete information in continuous domains. Therefore, extended versions of rough sets are proposed to handle incomplete information in continuous domains.
There are two methods to deal with attributes with continuous values. One method is to replace a continuous domain with a collection of intervals, which is called discretisation. Various types of discretisation are proposed [2, 3]. In the discretisation if values characterising objects are included in an interval, the objects are handled as indiscernible and the family of indiscernible classes is obtained [4]. How discretisation is made has a strong influence on the results. The other method is to use neighbourhood [5]. In this approach when the distance between two objects is within a specified threshold, they are handled as indiscernible. Results derived from using the neighbourhood gradually vary in response to changes of the threshold. We develop an approach using the neighbourhood.
We have some approaches to incomplete information in a continuous domain. One approach is to use the same way as that applied to nominal attributes by Kryszkiewicz [6]. The approach is most frequently used [7–10], but it produces poor results from loss of information [11, 12]. This is because the approach fixes the indiscernibility of an object characterised by incomplete information with another object. An object with incomplete information has two possibilities to another object. One possibility is that the two objects may have the same value; namely, it means they may be indiscernible. The other is that the two objects may have different values; namely, they may be discernible.Therefore, this fixing means taking into consideration only one of the two possibilities. To solve this problem, we use possible classes, as was mentioned in information tables consisting of discrete values [13, 14]. It is required to give a correctness criterion in order to justify the approach. To give the approach a correctness criterion, we study an approach using possible world semantics, as is studied by Lipski in the field of databases handling incompleteness of information [15, 16]. The approaches so far under possible world semantics use as possible worlds possible tables derived from an incomplete information table.Unfortunately, incompleteness of a value in continuous domains generates an infinite number of possible tables. Possible world semantics is unavailable as long as possible tables are used.In the first place, rough sets start from the indiscernibility relation on a set of attributes in an information table. We note that the number of possible indiscernibility relations is finite, even if the number of possible tables is infinite, because of a finite number of objects. We apply possible world semantics through possible indiscernibility relations to an incomplete information table with continuous domains.
Rule induction starts from lower and upper approximations.For example, let two values that characterise objects o and o′be 4.70 and 4.83 of attribute a and the two objects be in an approximation of a set specified by value v of attribute b. Single rules a=4.70 →b=v and a=4.83 →b=v are induced,which are supported by o and o′, respectively. Value 4.76 of attribute a is discernible with 4.70 and 4.83 under threshold 0.05.Here, suppose we are asked what rules an object with value 4.76 of attribute a supports. We have no answer from these single rules for this query. This means that the applicability of the single rules is low. We propose to bring a series of single rules into one combined rule to increase applicability.
The contents will be stated in the following order. In Section 2,an approach using indiscernible classes under rough sets based on neighbourhood is briefly mentioned in the case of a complete information table. In Section 3, we use possibly indiscernible classes to an incomplete information table. In Section 4, we use possible world semantics in incomplete information tables.Here,we focus on possible indiscernibility relations, not possible tables. It is shown that the approach using possible classes gives the same approximations as those obtained from possible world semantics.In Section 5, a series of single rules brings into one combined rule in a complete information table. In Section 6, how combined rules are generated is described in an incomplete information table.Last, conclusions are described in Section 7.
2 Neighbourhood rough sets handling complete information by using indiscernible classes
A dataset is given as a two-dimensional information table in which columns are attributes and rows are objects. The framework of an information table is (U,AT,{D(a)|a ∈AT}), where U is the whole set of objects, AT is the whole set of attributes, and D(a) is the domain of attribute a with ?a ∈AT:U →D(a).
The starting point in rough sets, proposed by Pawlak, is an indiscernibility relation [1]. The indiscernibility relation, denoted by RA, on set A ?AT in a complete information table is
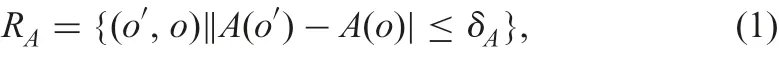
where(|A(o′)-A(o)|≤δA)=?a ∈A(|a(o′)-a(o)|≤δa),a(o)is the value that object o has in single attribute a and threshold δadenotes a range in which the two objects are indiscernible on a.
[o]Ais the indiscernible class for o on A ?AT
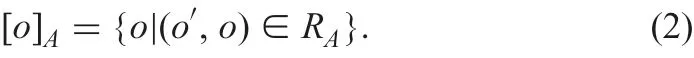
The indiscernible class is a tolerance one. Skowron and Stepaniuk extend rough sets by using the tolerance class [17]. Family FICAof indiscernible classes on A is
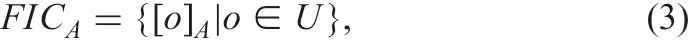
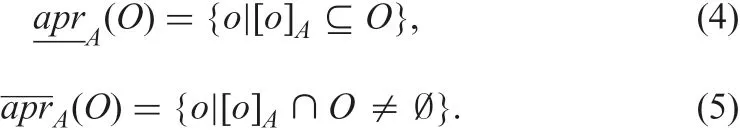
Proof:If δ1a≤δ2a,?o ∈are indiscernible classes of o under threshold δ1aand δ2a. So, this proposition holds.
Clearly, inclusion relationshipand complementarity propertyhold.
3 Neighbourhood rough sets handling incomplete information by using possibly indiscernible classes
When an information table contains incomplete information, it is called an incomplete information table. In incomplete information tables, a ∈AT:U →sawhere sais the union of intervals on domain D(a) of attribute a and sets of values over D(a). Single value v with v ?a(o) or v ∈a(o) is a possible one that may be the actual value.
We obtain lots of possibly indiscernible classes for an object from an incomplete information table. One of them is the actual indiscernible class. The family of possibly indiscernible classes for object o on set A ∈AT of attributes, denoted by F[o]A, is
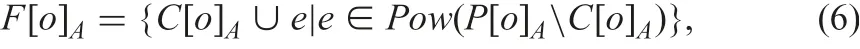
where Pow(P[o]AC[o]A) is the power set of (P[o]AC[o]A), and certainly indiscernible class C[o]Aand possibly one P[o]Aon A of object o are
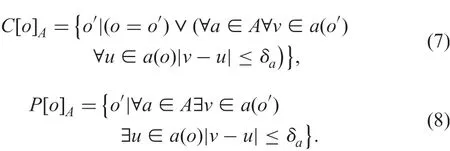
Clearly,C[o]A?P[o]A.Family F[o]Ais a lattice for inclusion.The minimum element is C[o]Aand the maximum element is P[o]A.
Example 1: Suppose incomplete information table IT1 is given in Fig. 1.
IT1 consists of five objects denoted by i with 1, ...,5.Attributes a and b take incomplete values for some objects. Using formulae (7)and (8), each certainly indiscernible class C[i]aand each possibly indiscernible class P[i]awith i=1, ...,5 on attribute a under δa=0.05 are as follows:
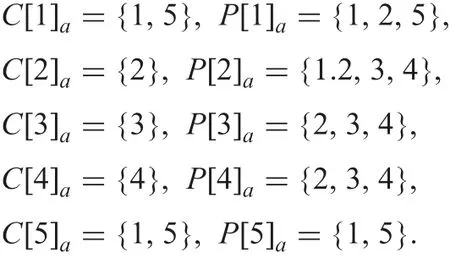
We cannot know the actual approximations under incomplete information. However, we can derive certain and possible approximations whose object certainly and possibly belongs to the actual ones, respectively, according to Lipski’s work for query processing to databases containing incomplete information[15,16].
Applying certainly and possibly indiscernible classes to set O of o bjects, certain and possible lower approximations of O for A,denoted by(O) and(O), are
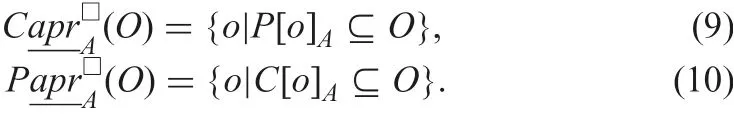
Similarly, certain and possible upper approximations, denoted byand(O), are

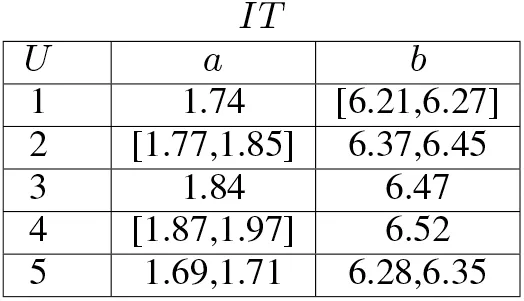
Fig. 1 Incomplete information table IT1
Example 2:Let set O of objects be{2,3,4}.Using Example 1 and formulae (9)–(12)
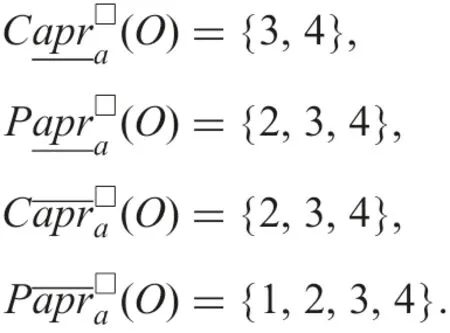
Similarly to the case of nominal attributes [14]
Proposition 2:
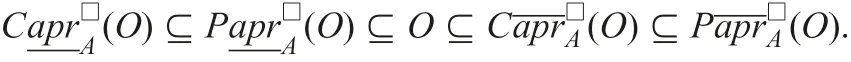
Using formulae (9)–(12), lower and upper approximations are as follows:
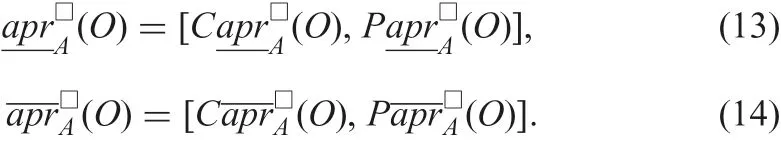
The approximations are expressed in an interval set in which the lower bound is the certain approximation and the upper bound is the possible one.
Example 3: Using Example 2 and formulae (13) and (14)
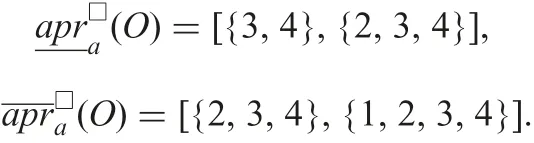
The relationship of the two approximationsandiswhich is the same as in the case of complete information tables.
Let O be restricted by W.Four expressions of approximations,certain and possible lower approximations and certain and possible upper ones, are
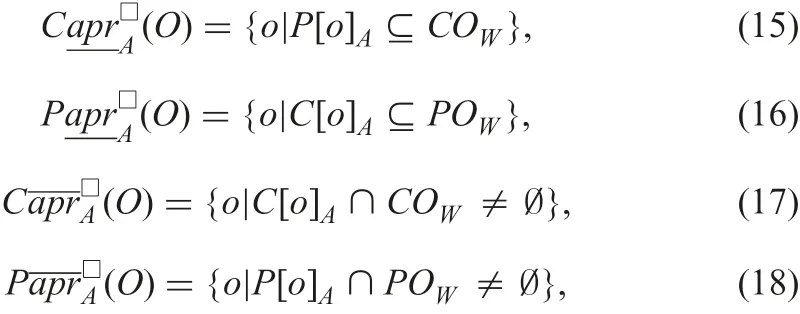
where

where CW(o)and PW(o)show that object o has to satisfy restriction W certainly and possibly. For example, when W is B=X, CW(o)and PW(o) are B(o)?X and B(o)∩X =?. And also when W is expressed by an interval using precise numerical values B(om) and B(on) with B(om)≤B(on)(=∧b∈B(b(om)≤b(on))), CW(o) and PW(o) are B(o)?[B(om),B(on)] and B(o)∩[B(om),B(on)]≠?.
Example 4:Let O be specified by values b(3)and b(4)in incomplete information table IT1 of Example 1. Using formulae (19) and (20),
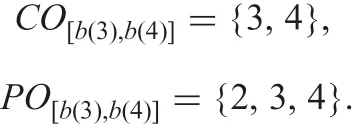
Certainly and possibly indiscernible classes of each object on a are ones in Example 1. Using formulae (15)–(18),
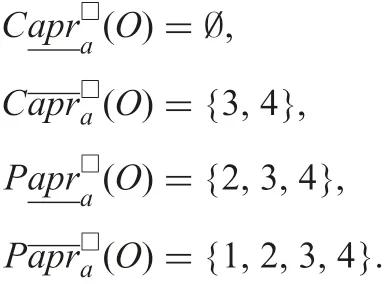
4 Obtaining rough sets from possible world semantics
In an incomplete information table with continuous domains, an infinite number of possible tables is produced on any continuous domain. Therefore, we cannot use possible world semantics.However, the number of possible indiscernibility relations is finite for a finite number of objects. We focus on this and apply possible world semantics to the indiscernibility relation on a set of attributes in an incomplete information table.
We have two kinds of indiscernibility relations from an incomplete information table. One is the certain indiscernibility relation. The others are possible indiscernibility relations. Certain indiscernibility relation CRAis
In this binary relation that is unique, a pair of objects in CRAis certainly indiscernible with each other on A. Such a pair is called a certain pair. On the other hand, we have lots of possible indiscernibility relations. The number of possible indiscernibility relations exponentially increases with the number of incomplete values. Family FPRAof possible indiscernibility relations is
where each element is a possible indiscernibility relation and Pow(MPPRA) is the power set of MPPRA, and MPPRAis
A pair of objects that is included in MPRAis called a possible pair.FPRAis a lattice for set inclusion. CRAis the minimum possible indiscernibility relation in FPRA, which is the minimum element,whereas CRA∪MPRAis the maximum possible indiscernibility relation, which is the maximum element. One of possible indiscernibility relations is the actual indiscernibility relation,although we cannot know it without additional information.
Example 5: In incomplete information table IT1 of Example 1,let threshold δabe 0.05 on attribute a. The set of certain pairs of indiscernible objects on a is
The set of possible pairs of indiscernible objects except the certain pairs is
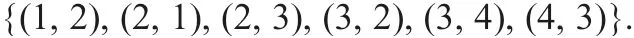
Using formulae (21)–(24), the family of possible indiscernibility relations and each possible indiscernibility relation on a are

These possible indiscernibility relations have the lattice structure for inclusion as shown in Fig. 2.
Possible indiscernibility relation pr1is the minimum one,whereas pr8is the maximum one.
The indiscernible class,denoted by[o]prA ,on set A of attributes for object o is derived from possible indiscernibility relation pr by formula (2)
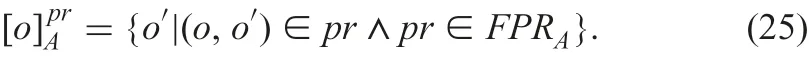
Proposition 3: If prk?prl, then?whereandare indiscernible classes of o under possible indiscernibility relations prkand prl.
Proof: Straightforward.
From this proposition, the family of indiscernible classes for an object is also a lattice for inclusion. By using [o]prA in formulae (4)and (5), two approximations of set O of objects in possible indiscernibility relation pr are
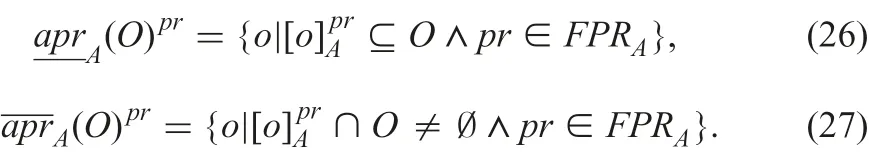
Proposition 4: If prk?prlfor possible indiscernibility relations prk,prl∈FPRA, thenaprA(O)prl.
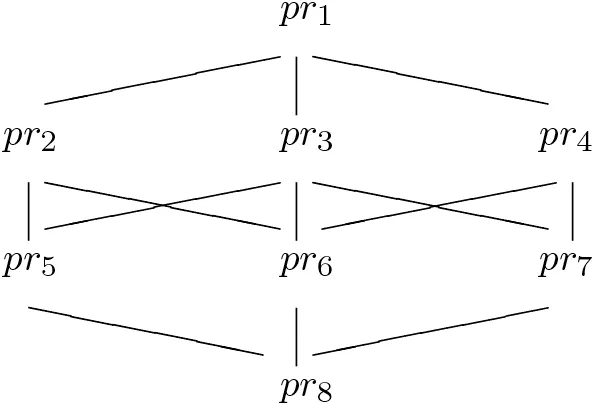
Fig. 2 Lattice structure for inclusion
Proof: The proof is straightforward from Proposition 3. □
This proposition shows that the sets of lower and upper approximations derived from possible indiscernibility relations are also lattices for set inclusion. We aggregate approximations under possible indiscernibility relations. Certain lower approximation
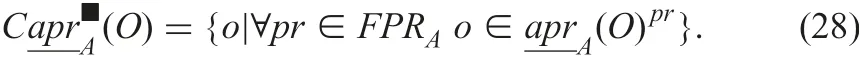
Possible lower approximationis
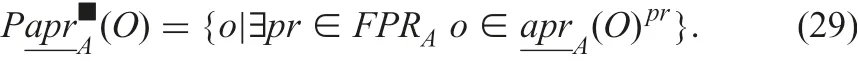
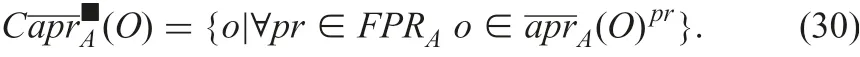
Possible upper approximation
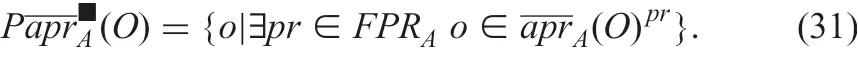
From Proposition 4, these approximations are transformed into the following formulae:
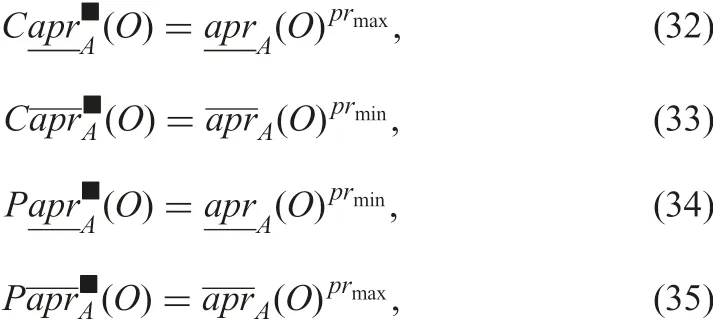
where prminand prmaxare the minimum and maximum possible indiscernibility relations. These formulae show that we can obtain the four approximations without computational complexity.
Example 6: Let set O of objects be {2,3,4} in Example 5. Using formulae (25)–(27), two approximations under each possible indiscernibility relation are
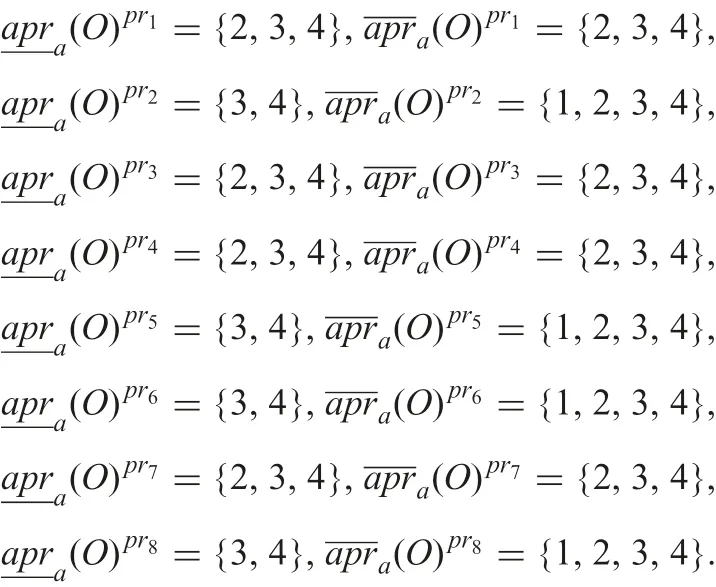
By using formulae (32)–(35)
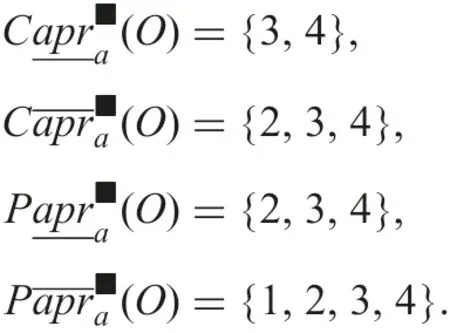
Furthermore, the following proposition is valid from formulae (32)–(35).
Proposition 5:
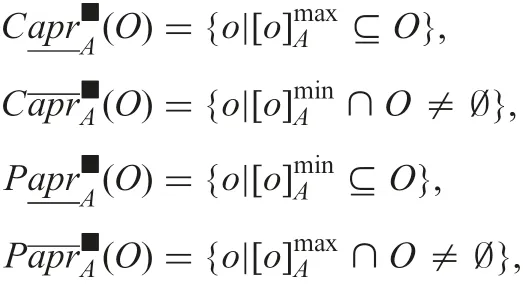
Proposition 6:
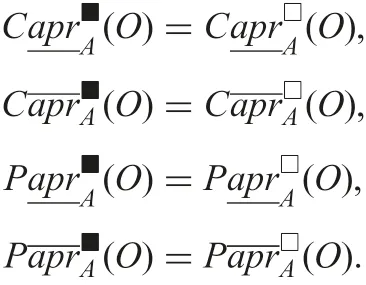
Proof: This proposition is straightforward from Proposition 5. □
This proposition shows that our extended approach using possibly indiscernible classes in Section 3 is justified. Namely, results from the extended approach using possibly indiscernible classes are the same as the ones from possible world semantics. A criterion for justification is formally represented as
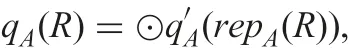
This kind of correctness criterion is applied to databases handling incomplete information [18–23].
5 Rule induction in information tables with complete information
Single rules are induced from the lower and upper approximations of O restricted by W.
The accuracy, which means the degree of consistency, is|[o]A∩O|/|O|.
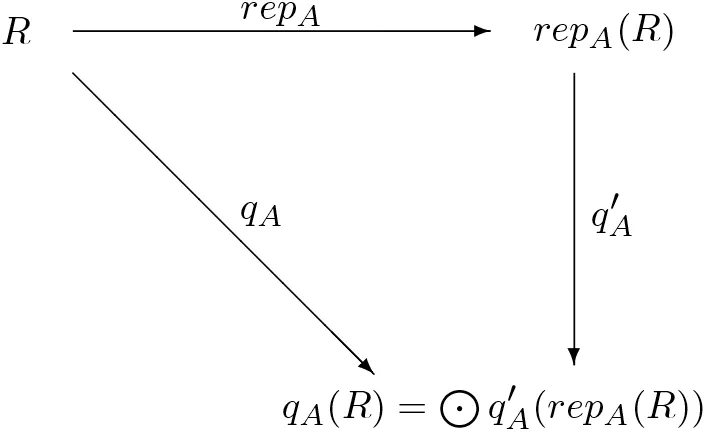
Fig. 3 Correctness criterion of extended method qA
In the case where attributes that characterise objects have continuous domains, single rules that individual objects in an approximation support usually have different antecedent parts. We obtain lots of single rules. To make rules more applicable, we bring a series of single rules into one combined one.
Let o ∈U be arranged in ascending order of a(o) and be given a serial superscript from 1 to |U|.(O) consist of collections of serially superscripted objects. For instance,(O)=(h ≤k). Let ol∈(O) support a single rule with antecedent part a=a(ol).
Then, single rules induced from collectionok-1,ok) can be brought into one combined rule having antecedent part a=[a(oh),a(ok)]. The combined rule has the accuracy calculated by minh≤s≤k|[os]a∩O|/|O|.
Proof:A single rule that is derived from(O)is also derived fromSo, this proposition holds.
Example 7:Let information table T0 in Fig.4 be obtained,where U consists of {1,2, ...,18,19}. Tables T1, T2, and T3 in Fig. 5 are created from T0.T1 where set{a,d}of attributes is projected from T0, T2 where {b,c} is projected, and T3 where {c} is projected.Besides, objects in T1, T2, and T3 are arranged in ascending order of values of attributes a, b, and c, respectively (Fig. 5).Indiscernible classes of each object under δa=0.05 are
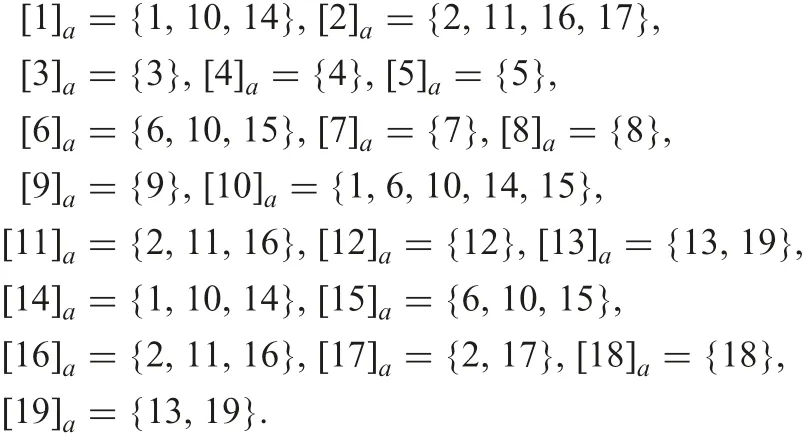
Under O restricted by d =x,O={1,2,5,9,11,14,16,19}.When O is approximated by objects specified by attribute a with continuous values. Using formulae (4) and (5), two approximations are
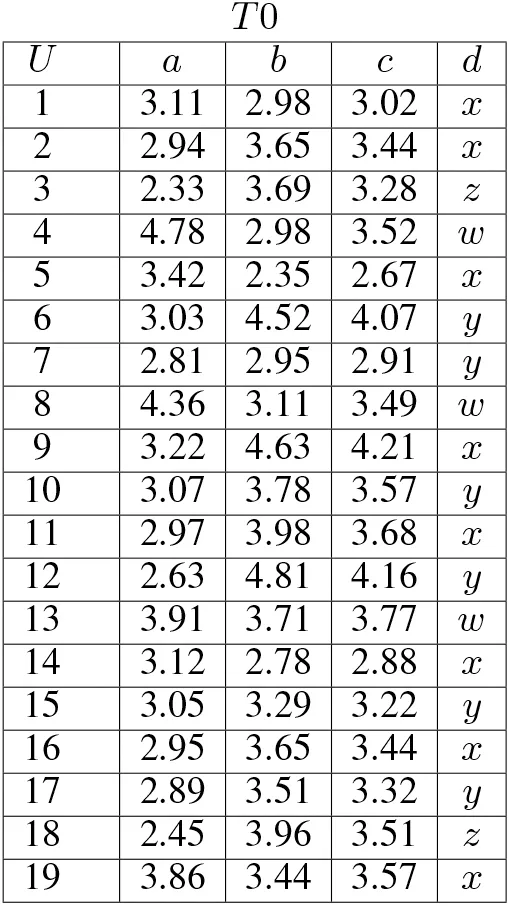
Fig. 4 T0 is an information table
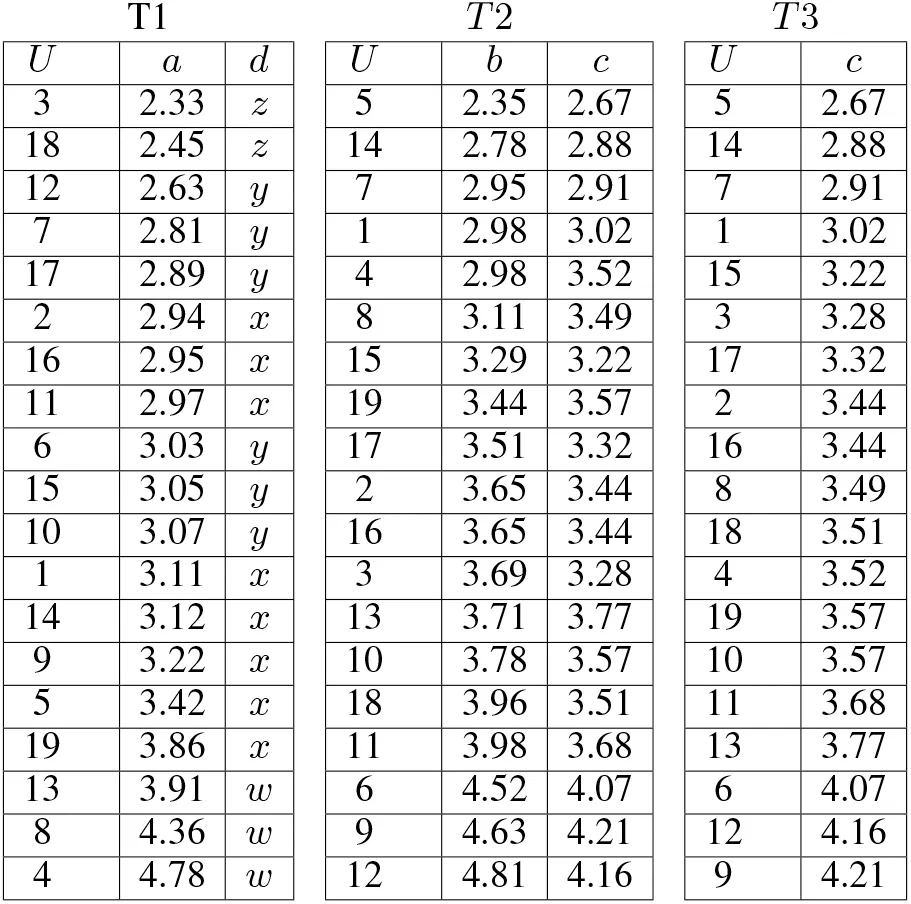
Fig. 5 Information tables T1, T2, and T3 are derived from T0
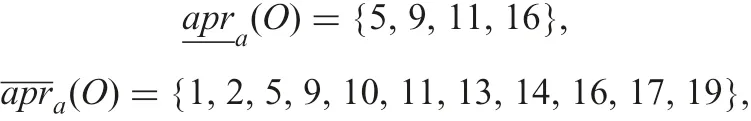
In information table T1, which is derived from T0, objects are arranged in ascending order of values of attribute a and are given a serial superscript from 1 to 19. The above lower and upper approximations are rewritten using the serial superscript as follows:From the lower approximation described by objects with superscripts, consistent combined rules are
a=[2.95,2.97]→d =x,a=[3.22,3.42]→d =x,from collectionsrespectively, where a(167)=2.95, a(118)=2.97, a(914)=3.22, and a(515)=3.42.From the upper approximation,inconsistent combined rules are
a=[2.89,2.97]→d =x,a=[3.07,3.91]→d =x,from collections515,1916,1317}, respectively, where a(175)=2.89, a(1011)=3.07, and a(1317)=3.91.
Subsequently,let O be restricted by c with the continuous domain.In information table T3 from T0, the objects are arranged in ascending order of values of c and are given serial superscripts from 1 to 19. Using lower bound c(155)=3.22 and upper bound c(810)=3.49, O=155,36,177,28,169,810We approximate O by objects specified by attribute b. Under δbbe 0.05,indiscernible classes of each object are
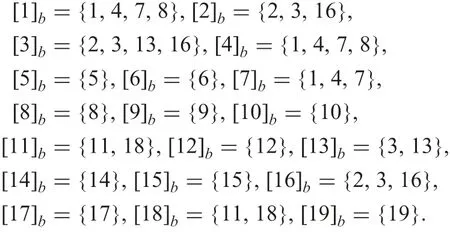
Using formulae (3) and (4), two approximations are
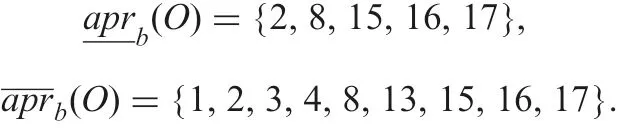
Using information table T2 where objects are arranged in ascending order of values of attribute b and are given serial superscript from 1 to 19, the above two approximations can be rewritten as follows:
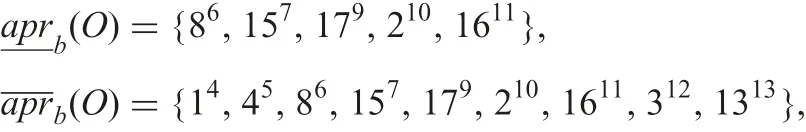
Consistent combined rules from collections andare
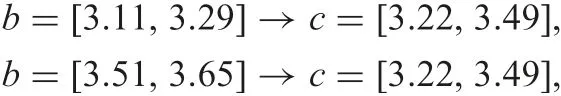
where b(86)=3.11, b(157)=3.29, b(179)=3.51, and b(1611)=3.65.Inconsistent combined rules from collections (14,45,86,157}and {179,210,1611,312,1313) are

where b(14)=2.98 and b(1313)=3.71.
This example shows that a combined rule has higher applicability than single rules.For example,from the above consistent combined rule b=[3.11,3.29]→c=[3.22,3.49],we can say that the object with value 3.17 of attribute b supports this rule, because 3.17 is in interval [3.11, 3.29]. On the other hand, from single rules b=3.11 →c=[3.22,3.49] and b=3.29 →c=[3.22,3.49],we cannot say what rule an object with 3.17 as a value of b supports under threshold 0.05, because 3.17 is discernible with both 3.11 and 3.29.
6 Rule induction in information tables containing incomplete information
When O is specified by restriction W,we can say for rule induction from objects in approximations as follows:

We create combined rules from them.
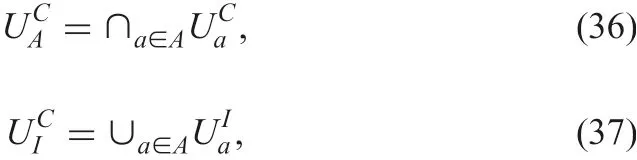
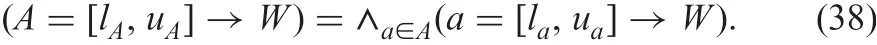
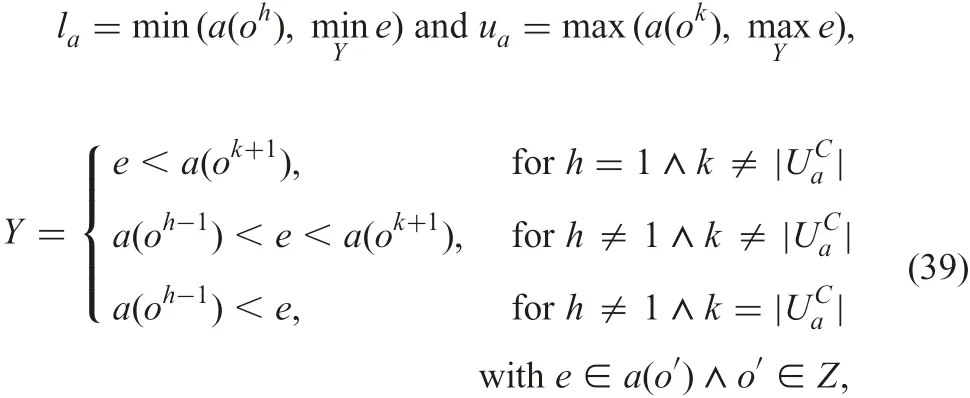
In the case of certain and inconsistent, possible and consistent,possible and inconsistent combined rules, Z is ((O)∩UaI),O)∩UaI), and ((O)∩UaI), respectively.
Proof:A single rule that derived from(O)is also derived from(O) because of(O)? So, this proposition holds.Proposition 9: Letbe the set of combined rules induced from(O) and Pr the set from(O). When O is restricted by W, if (A=[l1A,l2A]→W)∈Cr, then≤l1A,l2A(A=′′Proof:A single rule that derived from(O)is also derived from(O) because ofO)?(O). So, this proposition holds.
Proof:A single rule that derived from CaprA(O)is also derived from(O) because of(O)?(O). So, this proposition holds.
Proof: A single rule that is derived from(O) is also derived from(O) because of PaprA(O)?. So, this proposition holds. □
Example 8: Let O be restricted by d =x in IT2 of Fig. 6
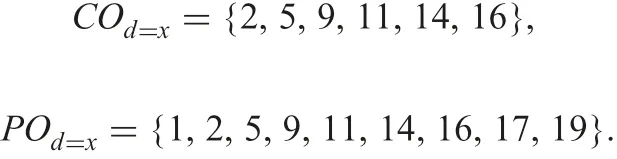
Each C[i]awith i=1, ...,19 is, respectively:
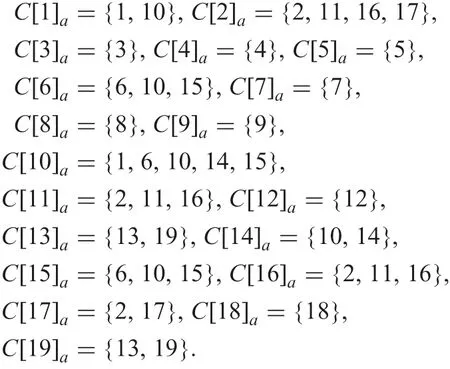
Each P[i]awith i=1, ...,19 is, respectively:

Four approximations are

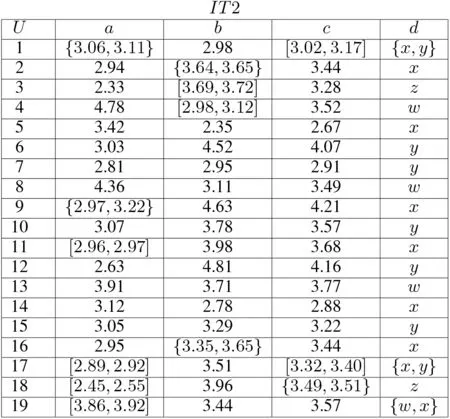
Fig. 6 Information table IT2 containing incomplete information
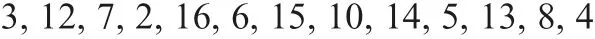
Applying serial superscripts to these objects
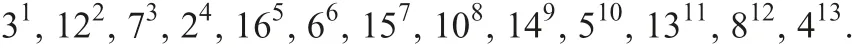
Using this expression, the four approximations are rewritten as follows:

Objects are divided into ones with a superscript and ones with only a subscript, ones having complete information and ones having incomplete information for attribute a, respectively:
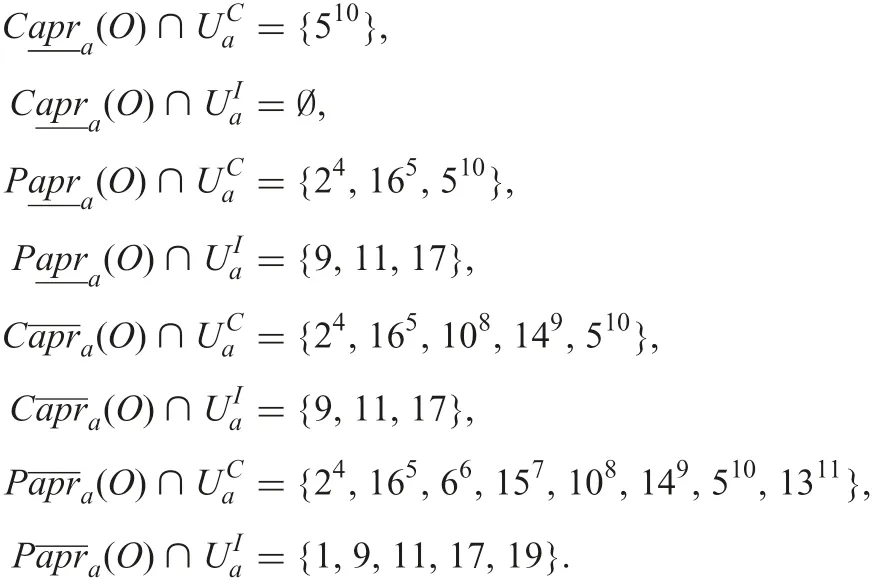
From these expressions and formula (39), four kinds of combined rules are created.A certain and consistent rule is
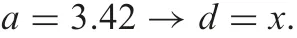
Possible and consistent rules are

Certain and inconsistent rules are
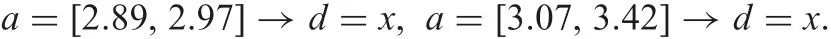
A possible and inconsistent rule is
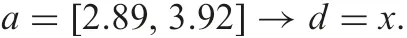
7 Conclusions
We have examined rough sets and rules induced from them in information tables containing continuous values by an approach based on neighbourhood.
First, we have briefly addressed lower and upper approximations in the case of a complete information table.
Second, we have coped with the case of an incomplete information table. Four approximations are obtained from the minimum and maximum possibly indiscernible classes. There is no difficulty of computational complexity, although the number of possibly indiscernible classes increases exponentially with the number of attribute values with incomplete information.
Third, we have shown lower and upper approximations obtained from using possible world semantics under possible indiscernibility relations, not possible tables, derived from an incomplete information table. Four approximations are obtained from the approach. A correctness criterion of any extended approaches is to give the same approximations as those obtained under possible world semantics. The four approximations from possibly indiscernible classes satisfy this correctness criterion.Therefore, the approach based on possibly indiscernible classes is justified.
Fourth, to increase applicability of rules, a combined rule has been proposed which are constructed from a series of single rules in a complete information table. The combined rule has an expression with an interval value. We obtain two kinds of combined rules, consistent and inconsistent ones, in a complete information table.
Fifth, we have constructed combined rules in an incomplete information table. We obtain four kinds of combined rules. They are certain and consistent, certain and inconsistent, possible and consistent, and possible and inconsistent combined rules. The combined rules have higher applicability than single ones.
8 References
[1] Pawlak, Z.: ‘Rough sets: theoretical aspects of reasoning about data’ (Kluwer Academic Publishers, Dordrecht, The Netherlands, 1991)
[2] Ali,R.,Siddiqi,H.M.,Lee,S.:‘Rough set-based approaches for discretization:a compact review’, Artif. Intell. Rev., 2015, 44, (2), pp. 235–263
[3] Yang, Y., Webb, I. G., Wu, X.: ‘Discretization methods’, in Maimon, O.,Rokachan, L. (Eds.): ‘Data mining and knowledge discovery handbook’(Springer, Berlin, Germany,2005), pp. 113–130
[4] Grzymala-Busse, J.W.: ‘Mining numerical data – a rough set approach’, Trans.Rough Sets, 2010, XI, pp. 1–13
[5] Lin,T.Y.:‘Neighborhood systems:a qualitative theory for fuzzy and rough sets’,Adv. Mach. Intell. Soft Comput., 1977, IV, pp. 132–155
[6] Kryszkiewicz,M.:Rules in incomplete information systems.Inf.Sci.,1999,113,pp. 271–292
[7] Jing, S., She, K., Ali, S.: ‘A universal neighborhood rough sets model for knowledge discovering from incomplete hetergeneous data’, Expert Syst., 2013,30, (1), pp. 89–96
[8] Yang,X.,Zhang,M.,Dou,H.,et al.:‘Neighborhood systems-based rough sets in incomplete information system’, Inf. Sci., 2011, 24, pp. 858–867
[9] Zenga, A., Lia, T., Liuc, D., et al.: ‘A fuzzy rough set approach for incremental feature selection on hybrid information systems’, Fuzzy Sets Syst., 2015, 258,pp. 39–60
[10] Zhao, B., Chen, X., Zeng, Q.: ‘Incomplete hybrid attributes reduction based on neighborhood granulation and approximation’. 2009 Int. Conf. on Mechatronics and Automation, 2009, pp. 2066–2071
[11] Nakata, M., Sakai, H.: ‘Applying rough sets to information tables containing missing values’. Proc. 39th Int. Symp. on Multiple-Valued Logic, Naha,Okinawa, Japan, 2009, Changchun, Jilin, China, 2009, pp. 286–291
[12] Stefanowski, J., Tsoukiàs, A.: ‘Incomplete information tables and rough classification’, Comput. Intell., 2001, 17, pp. 545–566
[13] Nakata, M., Sakai, H.: ‘Rough sets handling missing values probabilistically interpreted’, Lect. Notes Artif. Intell., 2005, 3641, pp. 325–334
[14] Nakata, M., Sakai, H.: ‘Twofold rough approximations under incomplete information’, Int. J. Gen. Syst., 2013, 42, pp. 546–571
[15] Lipski, W.: ‘On semantics issues connected with incomplete information databases’, ACM Trans. Database Syst., 1979, 4, pp. 262–296
[16] Lipski, W.: ‘On databases with incomplete information’, J. ACM, 1981, 28,pp. 41–70
[17] Skowron,A.,Stepaniuk,J.:‘Tolerance approximation spaces’,Fundam.Inform.,1996, 27, pp. 245–253
[18] Abiteboul, S., Hull, R., Vianu, V.:‘Foundations of databases’ (Addison-Wesley Publishing Company,Reading, Massachusetts, USA, 1995)
[19] Bosc, P., Duval, L., Pivert, O.: ‘An initial approach to the evaluation of possibilistic queries addressed to possibilistic databases’, Fuzzy Sets Syst.,2003, 140, pp. 151–166
[20] Grahne, G.: ‘The problem of incomplete information in relational databases’,Lect. Notes Comput. Sci., 1991, 554
[21] Imielinski, T., Lipski, W.: ‘Incomplete information in relational databases’,J. ACM, 1984, 31, pp. 761–791
[22] Paredaens, J., De Bra, P., Gyssens, M., et al.: ‘The structure of the relational database model’ (Springer-Verlag, Berlin, Germany,1989)
[23] Zimányi, E., Pirotte, A.: ‘Imperfect information in relational databases’,in Motro, A., Smets, P. (Eds.): ‘Uncertainty management in information systems: from needs to solutions’ (Kluwer Academic Publishers, Dordrecht,The Netherlands, 1997), pp. 35–87
 CAAI Transactions on Intelligence Technology2019年4期
CAAI Transactions on Intelligence Technology2019年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Influence of kernel clustering on an RBFN
- Neighbourhood systems based attribute reduction in formal decision contexts
- Fuzzy decision implications:interpretation within fuzzy decision context
- Survey on cloud model based similarity measure of uncertain concepts
- Rough set-based rule generation and Apriori-based rule generation from table data sets II:SQL-based environment for rule generation and decision support
- Rough set-based rule generation and Apriori-based rule generation from table data sets:a survey and a combination