
Boosting Unsupervised Monocular Depth Estimation with Auxiliary Semantic Information
2021-07-26 06:54:38HuiRenNanGaoJiaLi
China Communications 2021年6期
Hui Ren,Nan Gao,Jia Li
State Key Laboratory of Media Convergence and Communication;Key Laboratory of Acoustic Visual Technology and Intelligent Control System,Ministry of Culture and Tourism(Communication University of China);Beijing Key Laboratory of Modern Entertainment Technology(Communication University of China);School of Information and Communication Engineering,Communication University of China.No.1,Dingfuzhuang Street,Chaoyang District,Beijing,100024,China.
Abstract:Learning-based multi-task models have been widely used in various scene understanding tasks,and complement each other,i.e.,they allow us to consider prior semantic information to better infer depth.We boost the unsupervised monocular depth estimation using semantic segmentation as an auxiliary task.To address the lack of cross-domain datasets and catastrophic forgetting problems encountered in multi-task training,we utilize existing methodology to obtain redundant segmentation maps to build our cross-domain dataset,which not only provides a new way to conduct multi-task training,but also helps us to evaluate results compared with those of other algorithms.In addition,in order to comprehensively use the extracted features of the two tasks in the early perception stage,we use a strategy of sharing weights in the network to fuse cross-domain features,and introduce a novel multi-task loss function to further smooth the depth values.Extensive experiments on KITTI and Cityscapes datasets show that our method has achieved state-of-the-art performance in the depth estimation task,as well improved semantic segmentation.
Keywords:unsupervised monocular depth estimation;semantic segmentation;multi-task model
I.INTRODUCTION
Depth is the distance between the object and the camera in the natural scene,and is widely used in computer visual tasks such as 3D reconstruction and augmented reality.Some classic tasks such as image segmentation[1]and object detection[2]can be effectively improved by introducing depth information.The monocular depth estimation task performs pixellevel regression to predict depth values on the corresponding objects in the color image.At present,a large number of RGB-D datasets are publicly available,and deep learning-based algorithms are mainstream solutions to the problem of depth estimation.However,depth estimation is an ill-posed problem,which means the scenes with perspective conditions will be projected onto the same color image,that is,one color map corresponds to multiple depth maps.To cope with this issue,the supervised depth estimation model uses a ground truth with the real depth value as the target[3].However,it is difficult to obtain the depth ground truth because it requires professional equipment or approaches to annotate.Conversely,unsupervised learning-based methods do not require depth labels,and they mainly use the relationship between multi-view maps[4]or continuous image frames[5]to effectively integrate multi-view geometric information into the deep learning model.
In their study[6],Godard et al.proposed left–right consistency as a loss function of the unsupervised depth estimation.This novel loss function is also called construction loss,and it can guarantee the consistency between color images with different perspectives,which are reconstructed based on the predicted depth map.Moreover,the accuracy of the depth maps are improved continuously in the process of optimizing the reconstructed image.This form of loss function has also been applied in many subsequent studies[7,8].“If the neural network understands the basic semantic information of the scene,can it better estimate the depth?”Some previous works show that the introduced depth information can effectively solve some advanced visual tasks such as semantic segmentation[9,10].At the same time,semantic information can also help the network to better perform depth estimation.For example,the depth values of objects belonging to the same semantic label are smoother,while the depth values of a semantic label such as ”sky”are larger than the depth values of”car”.Humans often understand the semantics of scenes when we perceive depth information.Similarly,we can better infer depth after obtaining prior knowledge of semantic information;this has inspired us to explore the fusion of these two tasks.Some pre-deep learning approaches have already studied how to use the semantics labels to guide depth image inpainting[11]and 3D reconstruction[12],and it makes sense to combine these two tasks.However,some previous learning-based works performed these two tasks by parallel processing[13,14],which means training each task through different sub-networks.There was little further fusion training under the same framework to achieve mutual promotion of multiple tasks through knowledge sharing.
In this paper,depth estimation and semantic segmentation are jointed for model training.The main purpose is to use the semantic segmentation task to promote the performance of depth estimation,and the experimental results show that visual tasks can benefit each other through this training method.The entire network uses an end-to-end architecture,with two tasks sharing the whole encoder and partial decoder to fuse multi-task information.In addition to the pixellevel loss function used by the tasks,a novel multitask loss function is introduced to optimize the model as well as the accuracy of depth predictions.Furthermore,some previous multi-task methods based on semantic segmentation and depth estimation were executed on indoor datasets[13]and small-scale datasets[15].We used auxiliary semantic information to conduct training on depth estimation benchmark datasets such as KITTI and Cityscapes,and compared our method’s performance with those of existing state-ofthe-art methods.It is proved that multi-task training with auxiliary semantic information can effectively address the scarcity of cross-domain datasets,and the final performance indicators of both tasks are improved.The overall results of our method are shown in Figure 1.
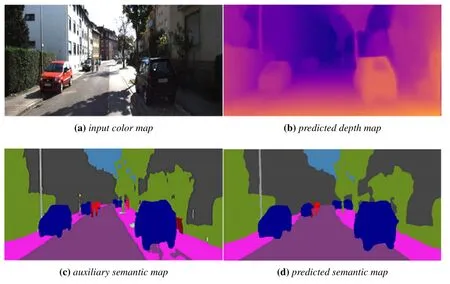
Figure 1.Overview of the proposed method.
Our contributions are as follows:
? We propose a new method for constructing and training a multi-task model of monocular depth estimation and semantic segmentation.The unsupervised depth estimation task and supervised semantic segmentation task benefit each other during the end-toend training process.
?Considering the lack of cross-domain datasets suitable for multi-task models comprising of semantic segmentation and depth estimation,we use an existing algorithm to generate auxiliary semantic information as the“ground truth”of the segmentation task.The experimental results show that even without real semantic labels,training with a soft target can still improve both tasks.
?In order to better extract the multi-task fusion features,our model shares the network parameters of the entire encoder and first few layers of the decoder.We also propose a novel multi-task loss function combining semantic and depth information to guide selfsupervised training.
?Previous multi-task algorithms were trained on the small-scale or indoor datasets.Our model trains and evaluates on these datasets,and we compare its performance with a large number of existing algorithms.
II.RELATED WORKS
In this part we cover related works,which are mainly divided into unsupervised depth estimation and multitask models with joint depth estimation.
2.1 Unsupervised Depth Estimation
Zhou et al.[16]used an image re-projection loss function as the supervised signal for unsupervised depth estimation.Their core idea was to estimate the depth of each frame based on the principle of photometric consistency.Concretely,the brightness of projections on two different frames for the same object should be consistent.This re-projection loss function is considered to be an effective method to resolve unsupervised problems,and has been applied to the depth estimation of image sequences,especially in joint depth estimation and tasks involving a visual odometer[17,18].Additionally,there is another type of depth estimation method based on multi-view matching,whose input can be a single image[19,20]or multi-view images[21,22],e.g.,when a left-view image is used as an input,a perspective transformation network[20]is generally used to obtain the right-view image for stereo matching.The principle of stereo matching is to find the positions in images of different perspectives for the same point in the scene,and then to perform depth estimation based on the disparities and corresponding camera parameters.In recent years,some domain adaptation methods have been proposed;they can use CG to synthesize large-scale color images and highquality depth maps as training datasets for depth estimation.Several works[23–25]have achieved considerable results for monocular depth prediction by transferring the model trained on synthetic data to real data,thereby effectively guiding the depth regression of real scene data.
In addition to the research on network architecture and loss functions,there are many recent works related to unsupervised depth estimation.Besides directly estimating the depth value at the pixel level,Deng et al.[26]obtained the depth order by training with a small amount of data,thereby helping to optimize the depth map.Meanwhile,Zhao et al.[27]studied high-resolution depth estimation,and figured out how to predict accurate depth maps with clear details.As for transfer learning,in their study[28],Alhashim et al.reused the high-performance pre-trained network originally designed for image classification as a deep feature encoder.A major advantage of this transfer learning-based approach is that it is easy to transfer a modular architecture to depth estimation problems.
Unsupervised depth estimation based on image reconstruction is used to predict and optimize the depth map,and the reconstructed image is generally obtained by applying the warping operation to the depth map and the original image.Some existing works treat the unsupervised monocular estimation task as a reconstruction problem,thereby reducing dependence on a large amount of ground truth depth data[29,30].In addition,the reconstruction idea has also been applied to the GAN framework[7].Most importantly,an existing unsupervised depth estimation algorithm[6]showed stable and good performance.Our model is designed based on this algorithm,and applies the multi-task approach to promote both depth estimation and semantic segmentation.
2.2 Multi-task-based Depth Estimation Algorithms
The current multi-task models mainly involve joint learning of the visual odometer[31],object detection[32],and semantic information[13]with depth estimation.Furthermore,in their study[33],Gordon et al.proposed a method for simultaneous learning of depth,egomotion,object motion,and intrinsic camera parameters from monocular videos,using only supervision signals from neighboring video frames.
In terms of multi-task models that combine semantic segmentation and depth estimation,there is a main concern that there are few cross-domain datasets suitable for both tasks,especially a lack of semantic segmentation datasets with ground truth labels.Aiming at solving this problem,in their study[34],Chennupat et al.used domain adaptation technology,in which semantic segmentation was the main task and depth estimation was the auxiliary task.In their study[14],Kendall et al.pointed out that the optimal weight of each task depends on the measurement scale,e.g.meters,centimeters,or millimeters,and the level of task noise.They combined multiple loss functions at the same time to learn the loss function weight of each task.In their study[35],Mustafa et al.proposed a method to jointly train semantic 4D scene streams,multi-view joint segmentation,and reconstruction of complex dynamic scenes.By using semantic labels,appearance,shape,and motion information,similar frames were identified by semantic trajectories,which resulted in temporal and semantic consistency over long frames.Several works[36,37]designed a lightweight network to ensure real-time performance in the multi-task process based on depth estimation and semantic segmentation.For example,in their study[38],Wu et al.performed stereo matching and semantic segmentation at the same time.In their study[39],Ye et al.used the knowledge distillation method to perform pixel-level scene analysis and depth estimation.In most cases,the difference between the semantic segmentation and the depth estimation is that the former is a classification task and the latter is a regression task.However,in their study[40],Liu et al.regarded the depth estimation as a classification problem in multi-task learning.
In their study[15],Ramirez et al.combined unsupervised monocular depth estimation and supervised semantic segmentation based on the idea of reconstruction.In contrast,in the present paper,two subtasks share features by sharing the encoder,and a selfsupervised loss function considering depth and semantics is used to jointly train the two tasks.However,in their study[15],Ramirez et al.used only the left color image to predict the disparity maps of two perspectives,which caused mismatching between the right color image and the predicted right depth image.To cope with this issue,the input employed by Chen et al.[41]used stereo image pairs to predict the disparity maps of each perspective respectively,and reused the parameters of the first several decoder layers,which has been shown to be able to improve performance on two tasks at the same time.In their study[15],Ramirez et al.mainly trained and inferred samples on small datasets while Chen et al.[41]used different datasets for depth estimation and semantic segmentation.On the contrary,our network architecture effectively solves the problem of a lack of cross-domain datasets and catastrophic forgetting[42]when training for multiple tasks.Specifically,we use auxiliary semantic information to establish a multi-task benchmark dataset,which can be more reasonable to compare with single task,such as depth estimation.In addition,we use a novel fusion loss function to train the network,and fuse multi-task features to improve both tasks to a greater degree.
III.METHODOLOGY
In this section,we will introduce the details of the proposed multi-task model and the loss function that motivates the model to accomplish the specific task.The architecture of our model is shown in Figure 2.We use the encoder–decoder architecture,which can effectively extract compact features and perform image generation at the decoder and with the original image size.As shown in Figure 2,the monocular color map(taking the left viewIas an example)is sent into the model for multi-task training,and finally the depth prediction and semantic segmentation prediction corresponding to the two visual tasks(depth estimation and semantic segmentation)are obtained.Inspired by the model design of the paper[6],our model also uses Resnet50 as the encoder,and the decoder uses the linear interpolation to transform the compact features to the depth map and semantic segmentation map.
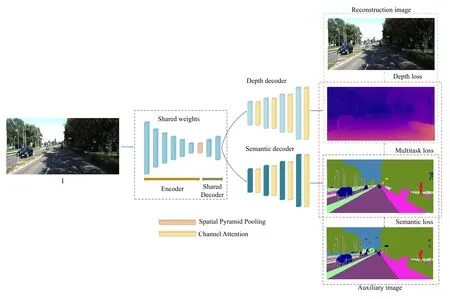
Figure 2.Multi-task model for depth estimation and semantic segmentation.The model consists of two parts:unsupervised depth estimation and semantic segmentation using auxiliary semantic information.The loss function consists of three parts:depth loss,semantic loss,multi-task loss.
Semantic segmentation and depth estimation are sub-tasks of scene understanding,stereo perception,etc.During feature extraction,some features useful for one task are also useful for the other.Effective fusion of features can not only deepen the mining of feature expressions,but also can effectively prevent the model from overfitting on a specific task.Therefore,we share the feature weights in the encoder module in order to explore common features suitable for these two subtasks.In addition,we add a spatial pyramid pooling layer which was introduced in[43]at the end of the encoder for multi-scale feature fusion.Specifically,the last convoluted features are processed through the global maximum pooling layer with convolution kernel size of 5×5,7×7 and 9×9,respectively.Finally,the original feature map and these three forms of features are concatenated together.
Most works regard depth estimation as a regression task[3],and semantic segmentation as a classification task[44],and our work follows this.In the decoder,although different tasks have their own specific goals,in the early stage of image prediction,some features that are generally suitable for scene understanding can be properly fused.Therefore,we also attempt to share the front layers of the decoder,and ablation results show that sharing the early part of the decoder can further optimize each task.The black dotted box in Figure 2 indicates the model architecture for feature sharing.In the decoder network,we add the channel attention module after the convolution layers to screen out the significant features for specific tasks.The feature map is expressed asFH×W×C,whereHandWare the height and width of the feature map,andCis the number of channels.After the attention module,the feature of each channel is multiplied by the corresponding channel weight,as shown in Equation 1.Inspired by the work of Wu et al.[45],we use the global average pooling layer to get a vector of 1×1×C,and then learn the channel weight parameters through onedimensional convolution with convolution kernel size of 3.The specific parameters of decoder’s network layers are shown in Table 1.
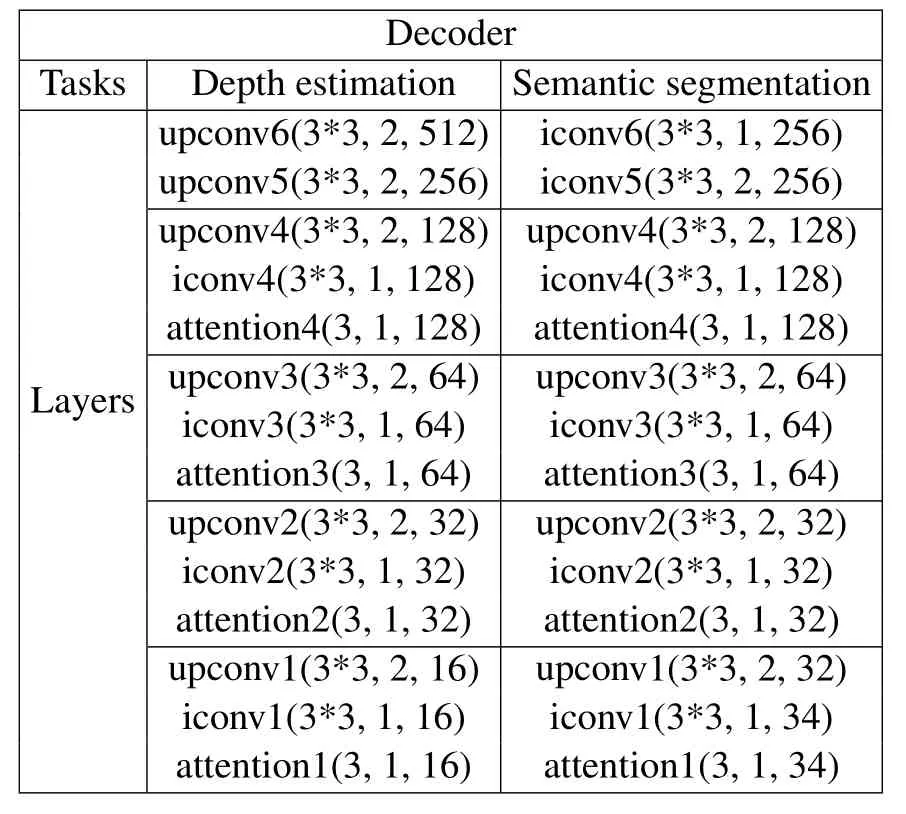
Table 1.Decoder configurations.Take upconv6(3*3,2,512)as an example:upconcv6 is the layer,3*3 is the convolution kernel size,2 represents the convolution step,512 is the number of channels of output layer.
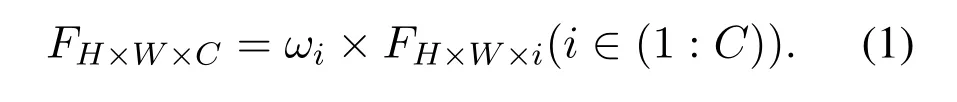
We use unsupervised training for depth estimation,implicitly supervise the predicted depth based on the reconstruction of the new perspective image,as introduced by Godard et al.[6],and use a pixel-level depth loss function(see the blue dotted box in the upper rightof Figure 2).We use self-supervision based on auxiliary semantic segmentation information to perform the semantic segmentation task,and the network is trained by multi-label pixel-level classification loss,which is shown in the dark blue dotted box at the bottom right of Figure 2.The two tasks not only share information at the feature level,but are also constrained by the proposed new multi-task loss function.A detailed introduction to the generation of auxiliary semantic information and all loss functions will be presented in the following subsections.
3.1 Depth Loss
We follow the method based on image reconstruction for unsupervised depth estimation training.Due to its stable performance,we use the loss function construction method proposed by Gordal et al.[6]to design our overall depth loss function,which is expressed as Equation 2.After color images are sent into the network,the left depth map and the right depth map are predicted.Each loss function has two forms:one for the left image and one for the right image.In addition,the depth estimation decoder network uses multi-scale output disparity maps,and therefore each loss function calculates the corresponding image losses on four scales(1,1/2,1/4,1/8),and finally aggregates the results of each scale.αds,αdi,αdlrepresent the weights of the corresponding loss.
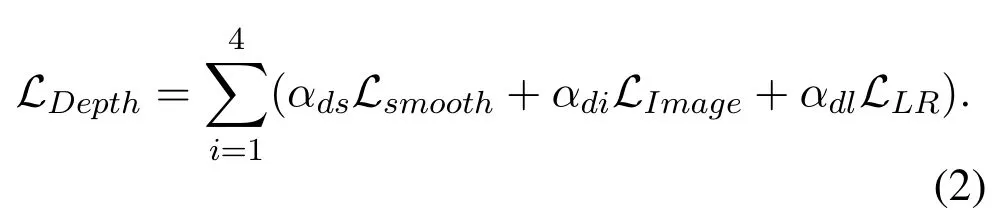
For stereo matching,when the same point in space is projected onto the image planes of two viewpoints,the two position coordinates can be transformed to each other by corresponding parallax values.That is,for a pointpin the left picture,the corresponding left disparity value isdL;then,the corresponding point ofpin the right picture should be(p ?dL).Similarly,the points on the left-view image corresponding to the original points on the right-view image can be obtained by the right image depth map(reversed disparity).By applying this to depth estimation,the left view can be reconstructed by shifting the distance of the corresponding disparity,as shown in Equation 3.We useto represent the reconstructed left image.
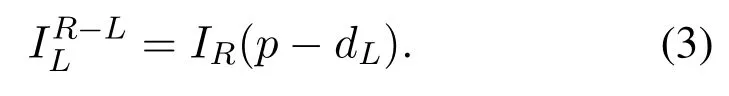
We follow the same protocol as the study[6]of Godard et al.,that is,both left and right images are used in the training stage but only one of them is used at inference.Specifically,we take the left imageILas the input of the entire network.After passing through the encoder,shared decoder,and depth decoder,the output is two disparity mapsdLanddRcorresponding to the left and right images of the binocular camera.dLthen is processed with the real right imageIRto generate the left image.The loss function comparing the generated left image with the real left image is updated to optimize the network.
When the position of the corresponding point is found by translating the distance of disparity,sometimes its coordinates are not integers.Therefore,we use the widely utilized warping operation[6]to get the corresponding integer coordinates.Generally,the warping operation is implemented by means of a grid sample function based on spatial transformer networks(STNs)[46],which perform a bilinear interpolation of two pixels in the same row.
Generally,the reconstructed image may have great distortion if only the mean squared error(MSE)metric is considered to compare the reconstructed image with the original image.Similar to the works[6,15],we introduce SSIM[47]to comprehensively calculate the photometric error of the reconstructed image and the original image.Structural dissimilarity(DSSIM)is a distance metric derived from SSIM,i.e.,.The form of the reconstruction loss function is shown in Equation 4,and DSSIM is used here to ensure the consistency between the viewpoint map constructed based on the depth map and the real one.Through this,we can optimize the intermediate depth and achieve unsupervised training.
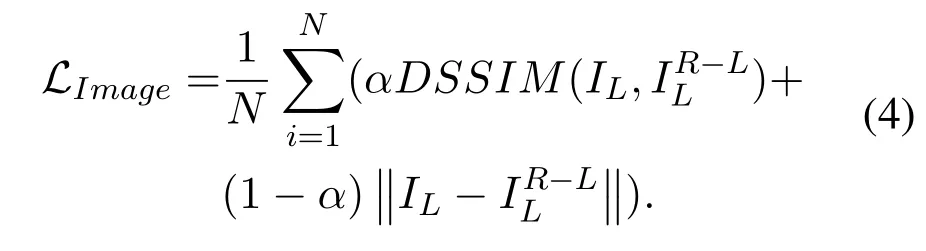
In general,the form of SSIM is shown in Equation 5.It uses the combination of meanμand varianceσto describe the structural similarity between x and y.Specifically,σxyrepresents the covariance between x and y,andμxrepresents the mean value of x.We adopt 3*3 filtering for the SSIM metric,and setαas 0.85,c1=0.012,c2=0.032.In our approach,x and y meanILand,respectively.N is the number of pixels used to compute the loss function,as well as Equation 5 and Equation 6.
We use the left–right consistency loss function proposed in the paper[6]to optimize the depth map(reversed disparity);this is similar to the left–right consistency check in stereo matching.The loss function is shown in Equation 6.
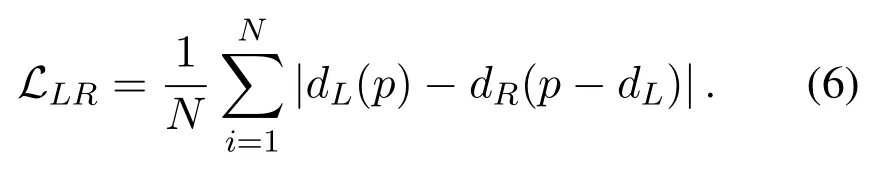
Finally,the edge smoothing loss function is added,following the construction method used in the study[6].This function smooths the depth value unless the image brightness of the local area changes suddenly,i.e.,usually at the edge of an object.The function is shown in Equation 7.
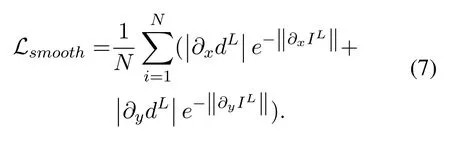
It should be noted that since the model in this paper actually predicts two depth maps(dLanddR)from a monocular image,we omit the loss function associated with the right view in the above equations.
3.2 Semantic Loss
As two important tasks of computer vision,semantic segmentation and depth estimation have always been the focus of many researchers.There are commonly used semantic segmentation datasets such as Cityscapes[48]and depth estimation datasets such as KITTI[49],but scarcely any cross-domain datasets are suitable for both tasks.In their study[15],Ramirez et al.trained on data with both depth and semantic labels on the Cityscpaes and KITTI datasets,with 2975 and 200 samples,respectively.The model trained on a small-scale dataset cannot compare reasonably with other algorithms trained on the depth estimation benchmark dataset.However,the catastrophic forgetting problem will appear when multi-task training is performed in succession,that is,the mode distribution of the task that is trained firstly will be destroyed by the task trained later;this obviously means that it cannot promote each task.To cope with these issues,we introduce auxiliary semantic information.A large number of existing studies on semantic segmentation have shown excellent model accuracy and efficiency.We use these algorithms to generate auxiliary semantic segmentation annotations on the benchmark dataset,and this progress can be shown asSAux=M(IL),whereMrepresents these methods.Although the obtained semantic maps are not as accurate as the ground truth,the performances of these algorithms show that this auxiliary information and real semantic labels are consistent in most semantic categories.Experimental results show that the participation of auxiliary information can not only be used as a supervision signal to accomplish the semantic segmentation task,but can also be used to promote the depth estimation task.We use the state-of-the-art method[44]proposed by Zhu et al.to obtain auxiliary semantic information.Specifically,since depth estimation is our main task,we use their model to generate auxiliary semantic images on the KITTI dataset.
For the semantic segmentation task,we use the cross-entropy loss function,and we consider 19 categories commonly used in semantic segmentation tasks.As shown in Equation 8,the symbolHrepresents cross-entropy,whereSAuxrepresents the auxiliary semantic segmentation maps,SLrepresents the predicted ones,andαsis the weight of the semantic loss.In general,as shown in Equation 9,andSidenote the ground-truth label and prediction for theithcategory,respectively.Some examples of the generated auxiliary semantic images are shown in Figure 3.

Figure 3.Example of auxiliary semantic information.We use the generated semantic segmentation maps instead of ground truth to train the model,and call this auxiliary semantic information.
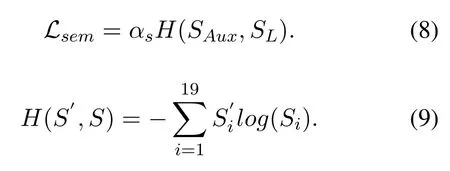
3.3 Multi-task Loss
Semantic segmentation tasks use auxiliary semantic images for supervised training.Although auxiliary semantic images participate in classification as an alternative to ground truth,there are inherent difficulties that are faced by semantic segmentation tasks,such as inaccurate prediction around edges[44].Therefore,the motivation of the multi-task loss function is to use the same semantic label for depth smoothing to optimize the depth accuracy.The difference between the work[15]of Ramirez et al.and ours is that the former uses the semantic ground truth to design the loss function while we use proxy semantic labels sourced from a pre-trained network for semantic segmentation.Hence,we construct a multi-task loss function in the form of edge smoothing loss,using the first derivative of prediction depth and auxiliary semantics,as shown in Equation 10,whereSemLis the left semantic map,dLis the predicted left map,αmis the weight of multi-task loss,andδis the Kronecker delta.We compute the first derivative of the predicted depth inx(?xdL)andy(?ydL)directions.The purpose of this is to smooth depth values only when the corresponding pixels belong to the same semantic label.This emphasizes smoothness within the same class rather than excessive edges between different classes,which was the case in the work[15]of Ramirez et al.In addition,in the training stage,we found that the semantic segmentation task converged faster than the depth estimation task.If we add this item at the beginning,the overall effect of the model will shift to semantic segmentation.Therefore,our training method is different from that of the work[15]proposed by Ramirez et al.,and we add the multi-task item when the semantic segmentation task converges.
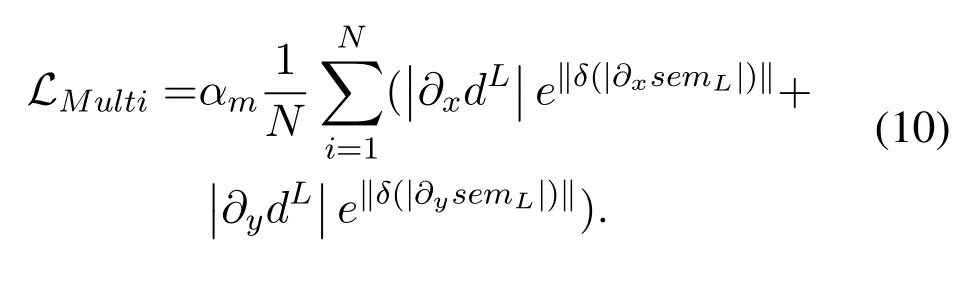
IV.EXPERIMENTS
In this section,we will introduce the used datasets,and details of the model’s implementation,and then present substantial experimental and visualization results.Because we take depth estimation as the main task,the datasets we use for training are mainly benchmarks used in depth estimation.The corresponding auxiliary semantic segmentation maps are generated based on them.
Cityscapes:This dataset[48]mainly contains massive stereo image sequences of street scenes,which are widely used in depth estimation,image segmentation,and other scene understanding tasks.For depth estimation,it includes 22973 color pairs for training,and we use them for model pre-training.
Eigen split:The dataset contains 22600 pairs of images for training and 697 for testing.The corresponding depth ground truths scanned by light detection and ranging(LIDAR)are also included.Eigen split is a subset of the KITTI[49]dataset and first appeared in the work of Eigen[3].After that,extensive depth estimation algorithms have been evaluated with this benchmark.In order to fairly compare our algorithm with previous algorithms on the depth estimation task,we mainly train on Eigen split[3].At the same time,22600 auxiliary semantic maps corresponding to the left color maps are predicted as the study[44]of Zhu et al.mentioned in section 3 of their work.The auxiliary semantic segmentation maps combined with corresponding color maps in Eigen split constitute our cross-domain dataset.
KITTI split:This dataset is a subset of the KITTI dataset[6],and contains 29,000 image pairs for training and 200 pairs for testing.It is worth noting that the test set not only contains annotations for depth,but also includes 200 corresponding pixel-level annotations as semantic ground truth,with 19 categories for segmentation.Although we use auxiliary semantic information for training,we use this dataset for testing on semantic segmentation.We also generated 29,000 auxiliary left semantic segmentation maps on this dataset.
4.1 Experiment Setup
Implementation details:Our model framework is implemented on TensorFlow.Our model has about 60 million parameters,and we set the training batch size to 8 and the total number of epochs to 50.The initial learning rate is set to 10?4,and the learning rate is halved at 60 and 80 percent of the total number of training steps,finally becoming 2.5?10?5.In addition,we use the Adam[50]optimizer with parametersβ1=0.9,β2=0.999,and?=10?8.
We resize images to 256*512 before using them as model input.In terms of data augmentation,a probability of 0.5 is adopted to flip left and right at the same time.Furthermore,in order to prevent overfitting,we randomly adopted gamma[0.8,1.2],brightness[0.5,2.0],and color[0.8,1.2]parameters.We set the weight of each loss function toαds=0.1,αdi=1.0,αdl=1.0,αs=0.1,αm=1.0.
We used the method[44]presented by Zhu et al.to generate left semantic segmentation datasets on the KITTI split[6]and Eigen split[3]datasets.This took about 0.416 s for each image on a single 2080ti GPU.Due to the addition of auxiliary semantic information,we simultaneously performed depth estimation and training of semantic tasks.We only added the multi-task loss functionLMultiwhen the data fitting of the two tasks started to converge.Our multi-task model was trained on one 2080ti GPU,and the entire process took about 22 hours.
4.2 Experimental Result s
4.2.1 Comparative Experiments
We compare the performance of current representative depth estimation algorithms on the Eigen split benchmark,as shown in Table 2.ES represents the Eigen split[3]dataset,and CS represents the Cityscapes[48]dataset;the performances are compared in the range of 80 m.
We use 7 statistical indicators widely used in depth estimation to evaluate the model.The first four indicators reflect the different proportions of errors|d ?dGT|in the true valuedGT,which is smaller when the model performance is better.The latter three indicators reflect the ratio of the predicted value d to the true valuedGT,and hence a larger value indicates better model performance.The specific forms of these indicators are shown in Equations 11,12,13 and 14.The best indicators are marked in bold in Table 2.
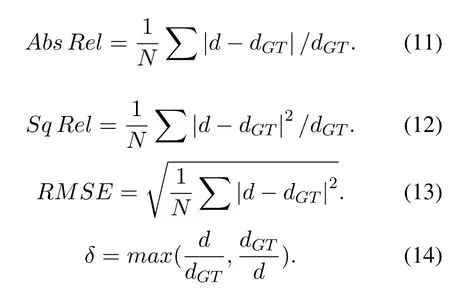
As can be seen from Table 2,the performance of our algorithm is state-of-the-art.Our depth estimation results are competitive compared with other methods,and further improved with the addition of the semantic segmentation task.It is emphasized that other multitask models[15]are trained on small-scale datasetssuitable for both tasks,i.e.,only 160 images for training.Since we generate proxy semantic labels on the KITTI dataset as supervision information,our multitask model can be compared fairly with depth estimation algorithms trained on the same large-scale benchmark dataset for the first time.In addition,our method can be seen as adding the semantic segmentation task to the depth estimation model[6].At the bottom of the table,we can see that after introducing the semantic segmentation task,the performance of our depth estimation significantly improved compared with the algorithm[6]presented by Godard et al.This further shows that using auxiliary semantic information to improve depth estimation can improve the existing depth estimation algorithms.
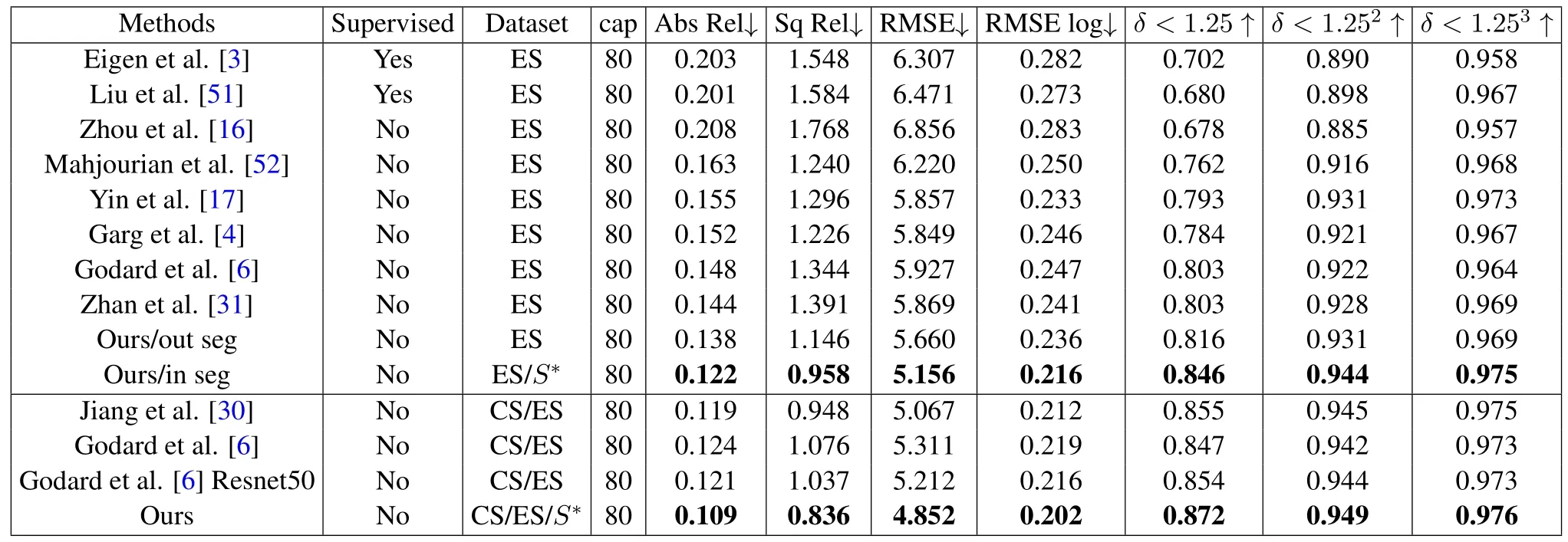
Table 2.A comparison of our proposed algorithm with state-of-the-art algorithms on the Eigen split and Cityscapes datasets.Following previous works,we evaluate our method in distances of 80 meters.↑indicates that higher is better,wheras ↓indicates that lower is better.The specific forms of these indicators are shown in Equations 11,12,13 and 14.ES indicates the Eigen split dataset,CS indicates the Cityscapes dataset,and S? indicates the auxiliary semantic labels.We evaluate our method both with(in seg)and without(out seg)the semantic segmentation task.
4.2.2 Ablation Study
In order to prove the effectiveness of our proposed innovations,we perform ablation experiments of depth estimation on the Eigen split[3]dataset.Our baseline is the multi-task model[15]proposed by Ramirez et al.For the depth estimation task,we use the same model architecture and corresponding loss function as the work[15]of Ramirez et al.It should be noted that the work[15]trained on a small dataset(160 images)by using the semantic ground truth.In order to make a fair comparison,we use the auxiliary semantic labels to train again on the KITTI dataset(22600 images)by using the method[15]as the performance of baseline.This is shown in Table 3.
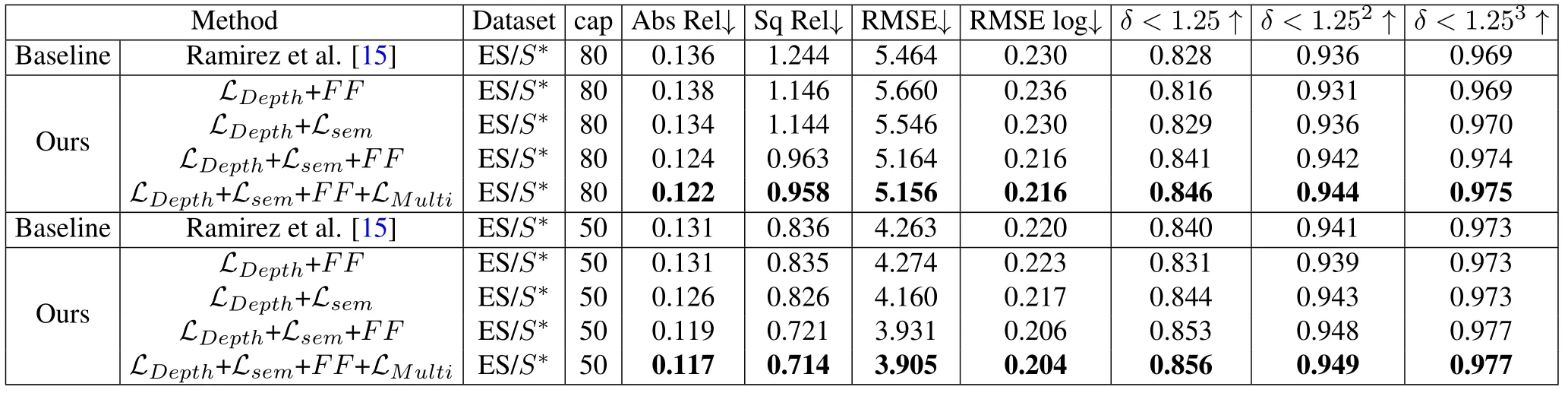
Table 3.Ablation experiments on the Eigen split(ES)dataset combined with the auxiliary semantic labels(S? ).↑indicates that higher is better,whereas ↓indicates that lower is better.The specific forms of these indicators are shown in Equations 11,12,13 and 14.We evaluate in distances of 80 and 50 meters,and mark the best indicators in bold.

Table 4.Ablation experiments on the Kitti split data set for semantic segmentation.The higher mIoU presents the better performance,and we mark the best indicator in bold.
Then we expand the depth framework to a multi-task model,and take turns adding the proposed ideas.First of all,we only train the depth estimation task of the proposed architecture,that is,only the loss function of the depth termLDepthis used.The multi-task architecture here is represented byFF,which represents the feature fusion technique mentioned in section 2,i.e.,two sub-tasks share features by sharing some layers,as well as reusing the parameters of decoder layers with attention modules.After that,we add the semantic segmentation task(Lsem)with and without the fusion frameworkFF.Finally,a multi-task lossLMultiis added to our proposed multi-task model.The ablation experimental index shows that the performance of the model is improved successively,which verifies the effectiveness of the three main contributions of this paper.This indicates that building a cross-domain dataset with auxiliary semantic information and using it to train a joint model for semantic segmentation and depth estimation can effectively improve the accuracy of depth estimation.Such a training method provides a general and effective idea for multi-task training.In addition,sharing partial network weights and adopting the multi-task loss function can further optimize the network training,which also indicates that such a feature fusion pattern is suitable for multi-task models.Furthermore,we present a visual comparison to prove semantic segmentation’s promotion of depth es-timation.As shown in Figure 4,the previous fuzzy road signs annotated by the red box become clearer due to the introduction of the semantic segmentation task.We find that such improvements typically occur in areas of small,semantic objects such as road signs.
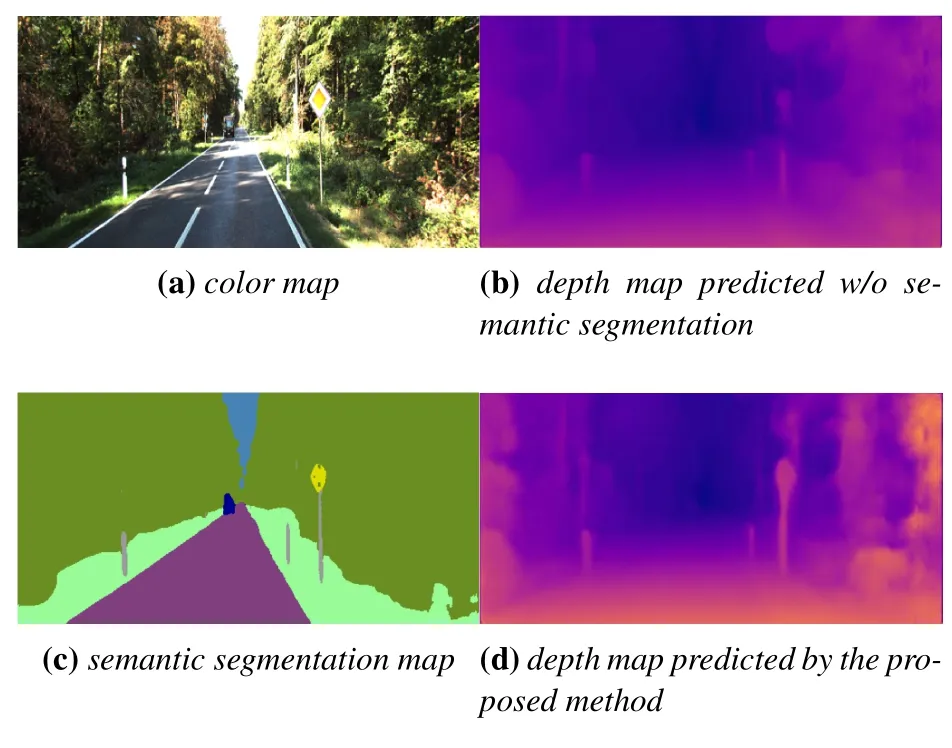
Figure 4.Example of semantic segmentation promoting depth estimation.
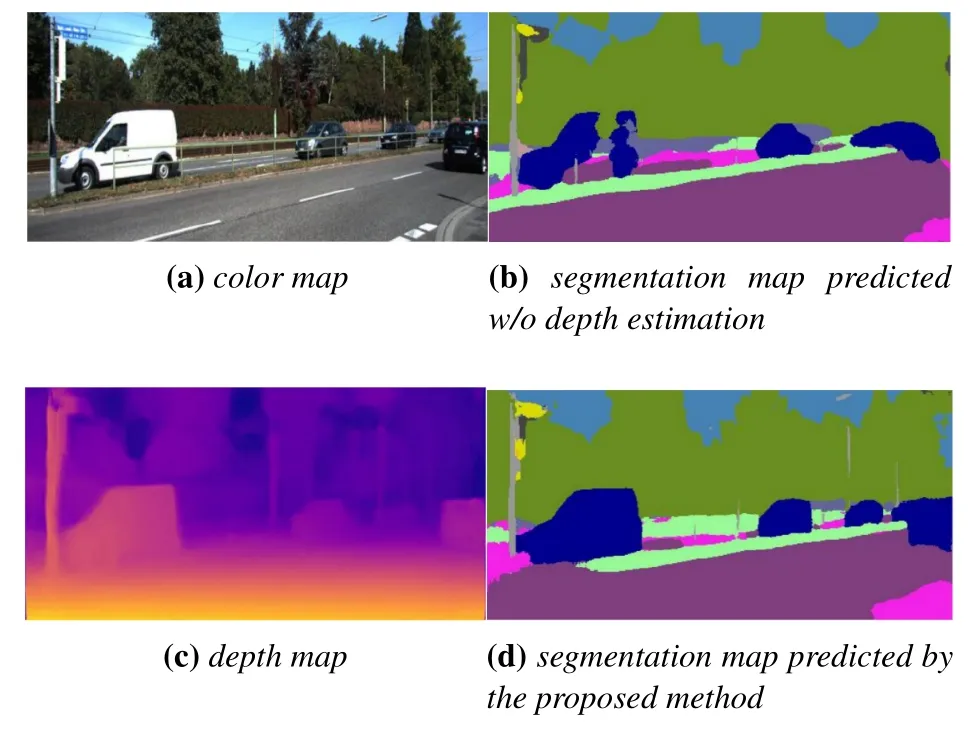
Figure 5.Example of depth estimation promoting semantic segmentation.
We also performed an ablation experiment on the semantic segmentation task on the KITTI split dataset[6],which contains semantic annotations.Here we first only perform the semantic segmentation task of our model,that is,only the semantic itemLsemis used.After that,similar to the above experiment,we addLDepth,FF,andLMultione by one.It should be noted that in the semantic segmentation ablation experiment,we adjust the weight of semantic segmentation lossαsfrom 0.1 to 1.Experimental results show that although semantic segmentation is only an auxiliary task,it is also more accurate than the base model trained alone,and the auxiliary semantic information can effectively approximate the unavailable semantic ground truth for training,as shown in Table 4.We also present a visualization about the promotion of semantic segmentation by depth estimation,as shown in Figure 5.Some missing objects during the inference stage of the segmentation task,such as cars,are predicted more precisely with the help of the depth estimation task.
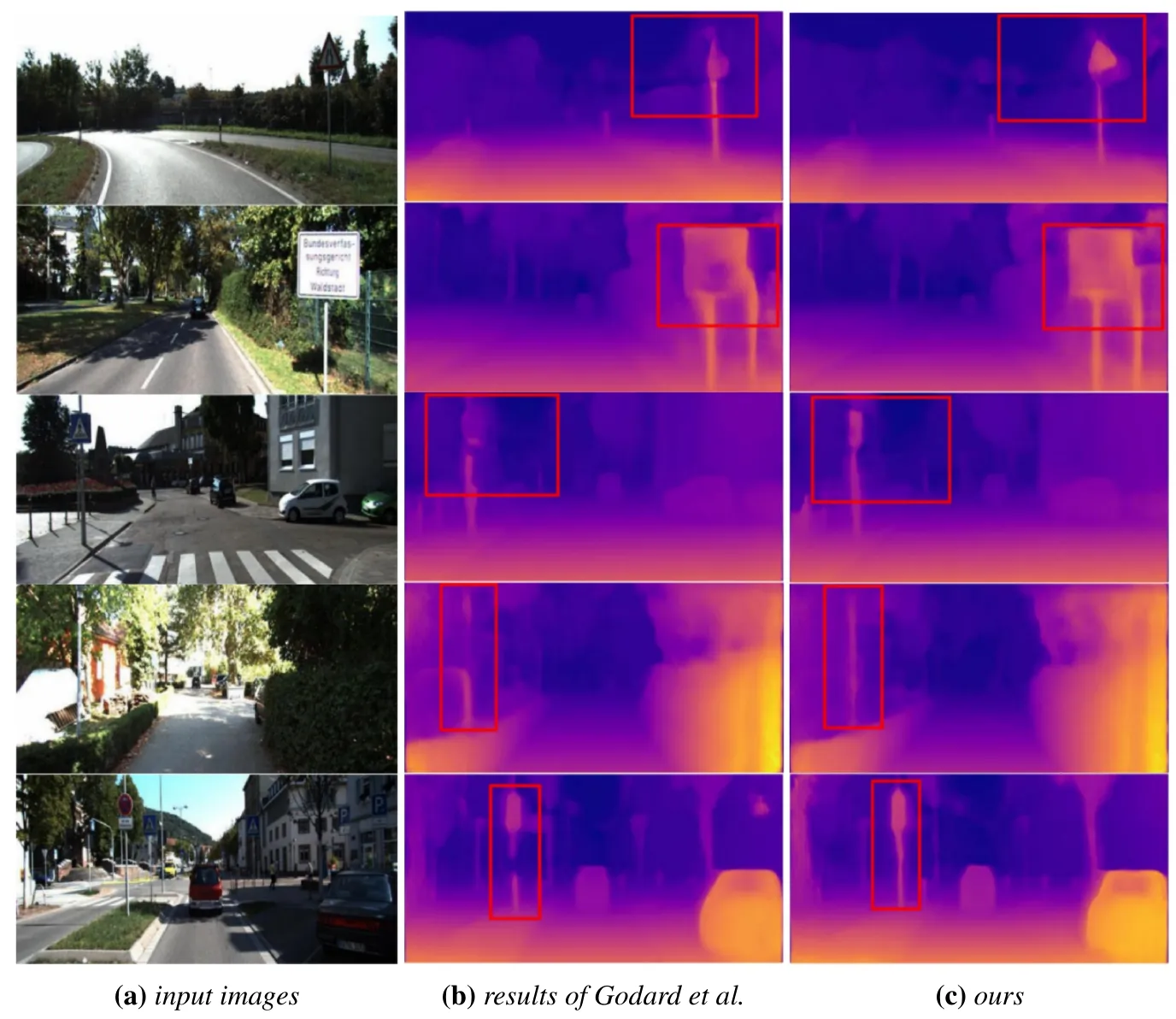
Figure 6.Some examples of depth predictions of our proposed multi-task model and baseline model.The input images are from the Eigen split dataset.The details that need to be noted are marked with red boxes.

Figure 7.Some examples of semantic predictions of our proposed multi-task model and single-task model.
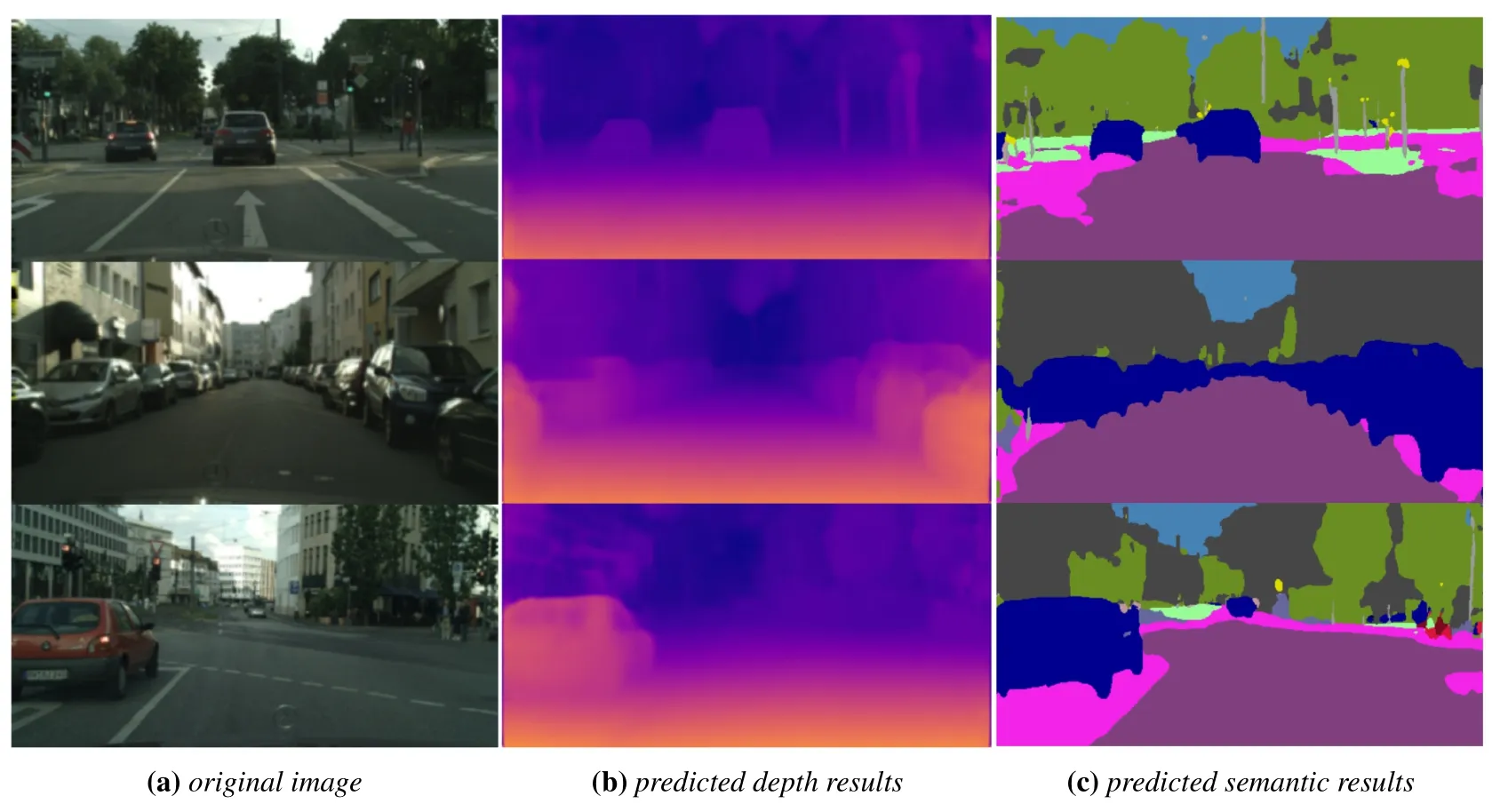
Figure 8.Experimental results of model generalization.
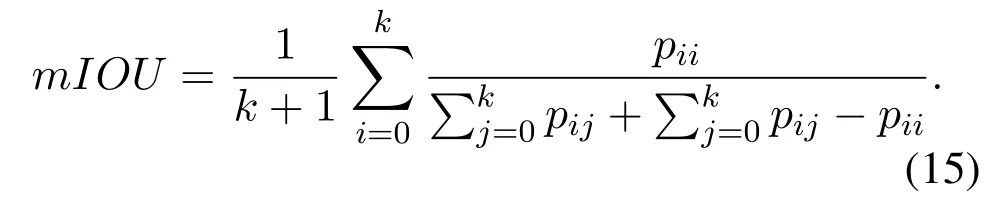
For segmentation tasks,the intersection over union(IoU)is used to represent the ratio of,where the number of true positives(TPs),false positives(FPs),and false negatives(FNs)are calculated based on pixels.We use the mean intersection over union(mIOU)to evaluate the results of semantic segmentation,as shown in Equation 15.Equation 15 describes the proportion of different combinations between real valueiand predicted valuejunderkclassification.Specifically,pijrepresents the amount of pixels with a ground truth label of categoryibut with a predicted category ofj.Therefore,pii,pij,andpjidenote TP,FN,and FP,respectively.
4.2.3 Visualization
Figure 6 shows examples of depth maps trained by a single-task model[6]and our multi-task model.The multi-task model with inter-related sub-tasks has superiority over the single-task model.Moreover,the dataset construction and feature fusion strategies proposed in this paper effectively solve some common problems in solving multiple tasks at the same time.
Figure 7 shows some examples of semantic predictions of our proposed multi-task model and singletask model.On the basis of the proposed multitask network,we only perform semantic segmentation task to get single-task results.Compared with single-task semantic segmentation,multi-task method can distinguish semantic information better,such as cars,fences,road signs and pedestrians mixed with background.
In order to verify the generalization ability of our algorithm,we use the model trained on Kitti[6]dataset to test on Cityscapes[48]dataset,and the results are shown in Figure 8.Although the model is not trained on the corresponding dataset,our algorithm can still infer the reasonable depth results and semantic labels.
Some examples of test results are shown in Figure 9.These examples are from the KITTI split dataset[6].The figure contains the ground truth of semantic segmentation and depth estimation provided in the test dataset,as well as the results predicted by our method.The visualization results show that our model can predict high-quality depth maps as well as semantic segmentation maps,which indicates that it can effectively train two sub-tasks with a shared model and can improve applications containing multiple visual tasks such as scene understanding.
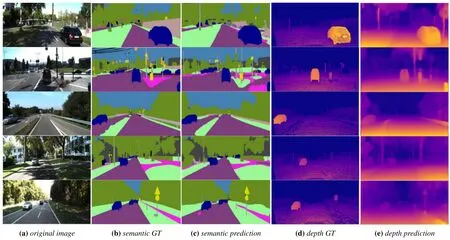
Figure 9.Examples of our experimental results on KITTI split.
V.CONCLUSION
This paper proposed a novel model of depth estimation combined with semantic segmentation,using auxiliary semantic information to effectively construct crossdomain datasets.In order to dig deeper into the connection between the two tasks,we shared the feature extractor and partial decoder of the two tasks,allowing the tasks to complement and promote each other.In addition,we introduced a multi-task loss function to smooth the depth values belonging to the same semantic label.Semantic segmentation as an auxiliary task further develops its characteristics to improve the accuracy of depth estimation;meanwhile,the addition of depth estimation enhanced the performance of semantic segmentation.The model was trained in an end-toend way,and we conducted extensive comparative experiments and ablation experiments on the benchmark datasets.The results showed that the proposed method effectively solves depth estimation as well as semantic segmentation.Compared with other depth estimation algorithms,our method had the best performance on all objective indicators.In the future,we will further study the selection of the weight of each task in the loss function.
ACKNOWLEDGEMENT
This work was supported by the national key research development plan(Project No.YS2018YFB1403703)and research project of the communication university of china(Project No.CUC200D058).

- China Communications的其它文章
- LED Adaptive Deployment Optimization in Indoor VLC Networks
- Reinforcement Learning-Based Sensitive Semantic Location Privacy Protection for VANETs
- Bit-Level Composite Signal Design for Simultaneous Ranging and Communication
- Joint 3D Trajectory and Resource Optimization for A UAV Relay-Assisted Cognitive Radio Network
- A Blockchain-Based Credible and Secure Education Experience Data Management Scheme Supporting for Searchable Encryption
- Sparsity-Aware Channel Estimation for mmWave Massive MIMO:A Deep CNN-Based Approach