
Reinforcement Learning-Based Sensitive Semantic Location Privacy Protection for VANETs
2021-07-26 06:54:40MinghuiMinWeihangWangLiangXiaoYilinXiaoZhuHan
China Communications 2021年6期
Minghui Min,Weihang Wang,Liang Xiao,*,Yilin Xiao,Zhu Han
1 Department of Information and Communication Engineering,Xiamen University,Xiamen 361005,China
2 School of Information and Control Engineering,China University of Mining and Technology,Xuzhou 221116,China
3 The Affiliated Hospital of China University of Mining and Technology,Xuzhou 221116,China
4 Department of Electrical and Computer Engineering,University of Houston,Houston TX 77004,USA
5 Beijing Key Laboratory of Mobile Computing and Pervasive Device,No.6 Kexueyuan South Road,Beijing 100190,China
Abstract:Location-based services(LBS)in vehicular ad hoc networks(VANETs)must protect users’privacy and address the threat of the exposure of sensitive locations during LBS requests.Users release not only their geographical but also semantic information of the visited places(e.g.,hospital).This sensitive information enables the inference attacker to exploit the users’ preferences and life patterns.In this paper we propose a reinforcement learning(RL)based sensitive semantic location privacy protection scheme.This scheme uses the idea of differential privacy to randomize the released vehicle locations and adaptively selects the perturbation policy based on the sensitivity of the semantic location and the attack history.This scheme enables a vehicle to optimize the perturbation policy in terms of the privacy and the quality of service(QoS)loss without being aware of the current inference attack model in a dynamic privacy protection process.To solve the location protection problem with high-dimensional and continuous-valued perturbation policy variables,a deep deterministic policy gradientbased semantic location perturbation scheme(DSLP)is developed.The actor part is used to generate continuous privacy budget and perturbation angle,and the critic part is used to estimate the performance of the policy.Simulations demonstrate the DSLP-based scheme outperforms the benchmark schemes,which increases the privacy,reduces the QoS loss,and increases the utility of the vehicle.
Keywords:semantic location;sensitivity;locationbased services;VANET;differential privacy;reinforcement learning
I.INTRODUCTION
Location-based services(LBS)in vehicular ad hoc networks(VANETs)such as the real-time traffic information report and nearby points-of-interests(POI)recommendation(e.g.,hospitals,gas station and electric vehicles charging station)bring great convenience to our daily life[1–4].However,the location data that indicates the users’ life patterns,religious affiliation and healthcare conditions can be leaked from the LBS server or eavesdropped by adversaries during the information exchange process for monetary or malicious purposes.VANETs must protect users’location privacy against adversaries who can infer the users’location and private information from the obtained location data[4,5].
The contextual information attached to the location data exposes more of the private information of vehicles to the adversary.To represent the contextual information the location coordinates can reveal,we use semantic location to describe a region with the same attribute,e.g.,park,hospital and religious site[6].Different semantic locations may own different sensitivity levels and demand different privacy protection.For example,the hospital is much more sensitive than the park which needs more effort to hide this information from the adversary.However,the semantic location as an additional dimension of the location data has been overlooked by most location protection schemes.
For example,a user requests the service from a LBS server to obtain the nearest POI recommendation when he/she is in a specific hospital due to his/her chronic disease.However,the hospital is considered as a sensitive location by the user and does not want to be identified by the LBS server.The semantic locations have strong correlations that can provide extensive information for the adversary to make a more accurate inference.Then the adversary can use location semantics to strengthen its attacks on user’s locations and privacy information.For instance,the adversary can infer that the above user may have some illness and is treated in that hospital.Then the advertisement adversary may send semantic-related spams or scams frequently to the user based on his/her current semantic information,degrading the LBS experience of the user[7].
Besides,as the user moves dynamically and there are temporal correlations between different semantic locations,by observing such location information,the adversary can infer the users’life pattern(e.g.,people go to counseling after leaving school)[8].When semantic locations are disclosed,the users’privacy level drops considerably.As a consequence,in spite of the convenience LBS can bring,most users will be unwilling to utilize LBS services when their location privacy is at risk,which will also impedes the success of the LBS.
To protect the user’s location privacy in LBS,a location perturbation scheme generalizes the well-known concept of differential privacy(DP)[9]with geoindistinguishability to enhance LBS applications,by using a planar Laplacian mechanism to generate an approximate location[10].However,this scheme considers the uniform privacy demands and ignores the semantic locations with different sensitivities,and therefore usually over-estimates/under-estimates the privacy of the user.For example,assuming a vehicle is parked at a hospital.If the scheme discloses the vehicle’s location that is very near to the actual location of a hospital,the attacker can still infer that the user is in the same hospital with high probability.If there are a park and a bank located at the vehicle’s west and east,respectively,with the same distance,the bank is more sensitive for the user compared with the park.A traditional location perturbation scheme might release a location in the bank to protect the current location privacy,but the proposed perturbation mechanism in this paper with the awareness of the location semantic’s sensitivity tends to release a perturbed location with less sensitivity in the park.
Location protection against semantic attack based onk-anonymity andl-diversity is studied in[11];however,this scheme usually needs a trusted third-party and costs high computation resources to generate the cloak area.A dynamic differential location privacy with personalized demands of user is studied in[12].The two-phase location perturbation that combines the geo-indistinguishability and expected inference error[13]is constructed to protect the location privacy based on user’s demands,by adding more noise to highly sensitive locations.Instead of just adding larger noise to protect highly sensitive semantic locations which will degrade QoS a lot[12],the proposed scheme tends to release a less sensitive one instead of a highly sensitive one to improve both privacy and QoS.In this way,both the current semantic location and the potential semantic location can be protected in a better way with the released less sensitive semantic location.In the long term view,this perturbation scheme can also protect the vehicle’s trajectory and avoid the semantic correlated inference of the adversary.Thus the semantic location protection scheme should not only consider the perturbed distance but also the sensitivity of the semantic location.
Most recent location privacy protection researches rely on a trusted third party,pay little attention to the semantic sensitivity and depend on a specific attack model.However,adversaries may dynamically change their attack policy based on the network and service state aiming to infer the user’s semantic location in a dynamic VANET.Besides,it is difficult to pre-determine the privacy requirement for dynamically changing semantic locations with different sensitivities and LBS requests of the vehicle.Moreover,it is noted that the future system state of the vehicle only depends on the current state and location perturbation policy,and does not depends on previous perturbation history.Thus,the location perturbation process of the vehicle can be modeled by a Markov decision process(MDP).Besides,the user’s environment is dynamically changing,and the inference attack model is hard to obtain accurately.Reinforcement learning(RL)techniques are applied to explore the optimal policy by trial and error with sufficient interactions without knowing the environment parameters.Consequently,we can apply RL techniques,such as Q-learning,to derive the optimal perturbation policy without aware of the inference attack model.
In this paper,we propose a reinforcement learningbased semantic location perturbation scheme(RSLP)for VANETs with differential privacy technique against inference adversaries.This scheme dynamically chooses the privacy budget to randomize the released locations to protect the sensitive semantic locations.Notice that releasing the perturbed locations reduces the quality of service(QoS)in location-based service.We use RL[14,15]to choose the perturbation policy based on the current state consisting of the current semantic location,the location sensitivity,and the attack history[16]to dynamically balance the QoS loss and privacy.
However,the RSLP-based scheme can only solve the location protection problems by discretizing the continuous perturbation policies into a finite set of discrete levels.This method introduces the quantization of the privacy budget and perturbation angle that destroys the completeness of the continuous space and removes some important information.If the quantization of the perturbation policy is not suitable,the scheme may derive the policy which is not the actual optimal.Besides,the RSLP faces the curse of dimensionality,which means that the large action-state space will decrease the learning speed and degrade the semantic location privacy protection performance.The deep deterministic policy gradient algorithm(DDPG)developed in[17]is effective for problems with the continuous-valued location privacy protection policy,which can be used by the vehicle to explore the optimal perturbation policy in a continuous space.
Thus,a DDPG-based sematic location perturbation scheme(DSLP)is developed to solve the location privacy protection problem with continuous-valued perturbation policy.In this scheme,the actor part generates continuous policy of privacy budget and perturbation angle,and the critic part estimates the location privacy protection performance of the perturbation policy.Based on the analysis of the paper[15],the IoT platforms such as Nvidia Tegra K1 and Qualcomm Snapdragon 800 which support deep learning can run the proposed DSLP-based scheme[18].This indicates that the proposed learning-based semantic location protection schemes can be implemented into the real VANETs environment.Simulation results validate that the proposed reinforcement learning-based semantic location perturbation scheme can increase both the vehicle’s privacy and the QoS,and thus improve the utility of the vehicle compared with that of the benchmark schemes as presented in[10]and[19].
Our main contributions can be summarized as follows:
1.We formulate a location privacy-preserving framework that considers not only the geographical location but also the semantic dimension of the location against the honest-but-curious adversaries in LBS.The vehicle can protect its highly sensitive semantic locations locally without a trusted third-party and avoid the semantic correlated inference of the adversary.
2.We propose a RL-based semantic location perturbation scheme and use the idea of the geoindistinguishability to adaptively select an appropriate privacy budget and perturbation angle to reduce the exposure of highly sensitive locations.
3.A DDPG-based semantic location perturbation scheme that can automatically balance the tradeoff between the privacy and QoS loss with high efficiency is proposed to select the perturbation policy from a continuous-valued perturbation policy set without knowledge of the inference attack model.
The remainder of this paper is organized as follows.Section II reviews the related works.Section III presents the system models.We propose an RSLP and a DSLP-based semantic location perturbation schemes in Section IV and Section V,respectively.The evaluation results are provided in Section VI,and this work is concluded in Section VII.
II.RELATED WORK
Nowadays,location privacy in VANET has been a hot research area[5].There are different kinds of mechanisms to protect location privacy in literature[20],such as anonymity,adaptive dummy trajectories generation[21],mix-zones method[22],and pseudonyms[23].
A semantic-aware location protection scheme is investigated in[8]to protect geographical location privacy together with semantic location privacy.This scheme needs accurate classification tree of semantic locations and protects semantic locations by generalizing their semantic tags(i.e.,releasing their parent categories).A methodology as provided in[24]studies the protection scheme of the users’purpose behind different check-ins,and this scheme tries to decrease the users’LBS quality loss by adjusting geographical and semantic perturbation level.But this scheme does not consider any given attack model.Trajectory protection against semantic attack based onk-anonymity andldiversity is studied in[25,11];however,this scheme usually needs a trusted third-party and requires high cost computation resources to generate the cloak area.
Differential privacy[9]is first developed to protect an individual’s privacy in a database,providing a rigorous privacy definition in a mathematically provable way.Recently,more and more related works use DP to make sure that the privacy is well protected.A utility-aware privacy-preserving synthesis of complete location traces is studied in[26]to defend the attack and protect the trace privacy with the differential privacy guarantee.As the standard definition of DP relies on neighboring databases with the insight of hiding a single individual data among a database,it becomes impractical in some contexts of privacy protection scenarios without a database,such as real-time location privacy protection.The definition of neighboring databases in the standard case is extended in[27]from the Hamming distance to a distinguishability level function,making the definition to be meaningful for privacy in more general cases.Especially for the location-based system,geo-indistinguishability proposed in[10]is a notion of location privacy corresponding to the generalized differential privacy,and the planar Laplace mechanism is presented to provide geo-indistinguishability by generating noise.Furthermore,linear optimization is used in[28]to balance the geo-indistinguishability and the QoS.
A DP framework is proposed in[29]to select the proxy gateway to prevent adversaries analyzing the traffic flow of a specific smart home.The temporal correlations of the user’s locations is considered in[30].This work applies DP to protect the location privacy by hiding the true location in a possible location set.A user-centric obfuscation mechanism is studied in[31]to defend against the optimal attack by jointly guaranteeing the differential and distortion privacy.
A minimax learning algorithm in[16]is studied to defend against advanced adversaries to protect the context privacy of the sensor-equipped smartphones.An improved Q-learning algorithm is investigated in[32]to help the user make better decisions concerning location disclosure and make a tradeoff between the users’ privacy and recommendation quality.To protect both the usage pattern and location privacy of the healthcare IoT device,the Dyna-architecture and post decision state are used in the privacy-aware offloading scheme developed in[33].
Our previous work[19]applies Q-learning to reduce the QoS loss while perturbing the location data to protect the semantic location privacy against the inference adversary.The vehicle perturbs the location data to mislead the adversary that the adversary cannot infer the current semantic location.In this work,we improve the scheme by incorporating the sematic locations’ sensitivity into the location perturbation scheme,to induce the adversary’s inference results to less sensitive semantic locations.The Qlearning based scheme in[19]can only handle the discrete perturbation action space.We use an actor-critic based method in this work to explore the optimal policy in a continuous perturbation action space and thus improve the performance of privacy optimization.
III.SYSTEM MODEL
We consider a vehicle equipped with a Global Positioning System(GPS)which has localization capabilities.As shown in Figure 1,the vehicle moves in a geographical area and requests the LBS from the server via a roadside unit(RSU)[34,35].To get LBS such as the POI recommendations and live traffic information,the vehicle sends its request to the LBS server together with the perturbed locations,tagged with semantic information.The server is honest-but-curious and it tries to infer the vehicle’s true geographical locations and the corresponding semantic types by observing the obtained location data.Then the server may send semantic information related spams or scams to users to gain commercial profit.

Figure 1.Illustration of the sensitive semantic location privacy protection scheme,in which the vehicle chooses the perturbation policy a(k ) at time slot k to perturb the location and sends its perturbed location(?d(k ),?c(k ))to the LBS server against an adversary that aims to infer the sensitive semantic location.
The GPS-equipped vehicle moves in a given geographical areaDat time slotkwhich is divided intoNnon-overlapping cellsd(k),which represents the coordinates of different locations,i.e.,geo-location.The semantic location visited by the vehicle is denoted byc(k)∈[Ci]0≤i≤N,in which the tags represent the semantic of different regions,e.g.,C1represents bank andC2represents hospital,as shown in Figure 1.Particularly,we denote cells without meaningful semantics byC0,e.g.,wastelands[8].Different semantic locations in this geographical area may own different sizes.The semantic location with a larger size consists of more cells.Since semantic locations have correlations(e.g.,both McDonald’s and Chinese restaurant belong to restaurant),we denote the set of all different instances of one semantic categoryCibyS(Ci)={Si,1,Si,2,...,Si,n}.For instance,letCirepresent ‘restaurant’,and there are 3 restaurants on the map,e.g.,S(‘restaurant’)={Burger King,McDonald’s,Panda Express}.It is a big question that how to divide these semantic locations into categories,and the division granularity is application dependent and up to the map size,which is beyond the scope of this paper[6].
The sensitivity of the corresponding semantic location at time slotkis represented byl(k)∈[Li]0≤i≤3.The sensitivity level of a semantic location represents the importance of the semantic location for user privacy,i.e.,the higher sensitivity level a semantic location has,the stronger demand of hiding the true semantic location of the user is.It is reasonable to assume that different instances of one semantic categoryCiown the same sensitivity level.
3.1 User Model
The vehicle’s transition between various semantic locations is captured by a Markov model according to[36],which states that
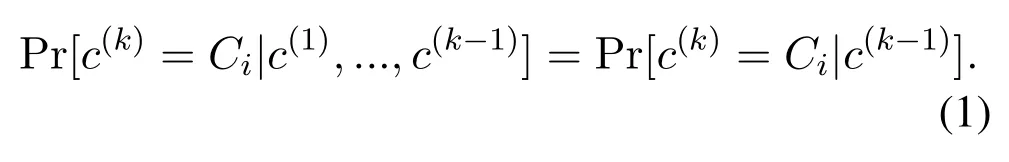
Discrete time slots over a limited timek∈{1,2,...}are considered.
The vehicle sends its location to the LBS server to request services.Due to privacy concerns,the real location has to be perturbed before it is sent out.The idea of the generalization version of DP,geoindistinguishability,is adopted to perturb the vehicle’s location[10].The perturbation policya(k)consists of the privacy budgetx(k)and the perturbation angle?(k)considering the semantic constraint,i.e.,a(k)=[x(k),?(k)]∈A,in which A is the possible perturbation policy set.The perturbation policy is selected to decrease the perturbation distance as much as possible with a less sensitive semantic location,to increase the privacy and reduce the QoS loss.On one hand,as shown in Figure 1,with the same perturbation distancer(k),the vehicle tends to release a location in the park with less sensitivity rather than the bank.On the other hand,if there are several less sensitive locations surrounding the current actual location,the vehicle tends to release a less sensitive location nearer its actual location.In this way,the vehicle can improve its privacy by reducing the exposure of highly sensitive locations and reduce the QoS loss.The vehicle generates a perturbed location ?d(k)based on the selected perturbation policy,meanwhile the perturbed semantic location ?c(k)can be obtained according to the map.
Similar to[8],at a given time slot,the vehicle’s perturbed location is independent of the other time slots.The vehicle has different privacy demands while visiting different semantic locations with different sensitivities,and the vehicle’s tolerance for the QoS loss is different when it asks for different kinds of LBSs.Thus the vehicle has to adjust its perturbation policy adaptively as the sensitivity of visited semantic location and its QoS loss tolerance change.The vehicle can estimate its privacy by the spams/scams it received and evaluate the QoS loss based on its service experience.
3.2 Adversary Model
The adversary is considered as an honest-but-curious LBS server or an external attacker who can observe the output of the location protection scheme.Its main purpose is to locate the vehicle at a given time or identify the semantic location type that the vehicle visits.We consider the adversary owns some prior knowledge about the vehicle and uses the observed locations to make an inference of the vehicle’s location[30].Even if the vehicle perturbs its location independently in each time slot,the adversary assumes that there are correlations between the locations of a vehicle,and therefore models the vehicle’s mobility to infer the users’life pattern.The adversary is assumed to know the road map that indicates the semantic locations corresponding to their geo-locations and its cover areas,and it infers the semantic of the current locationbased on.
The actual location of the vehicle is known only by itself,while the adversary can infer the preference or other private information of the user according to the information reflected by the users’geographical locations and the corresponding semantic locations.Then the adversary sends scams or spams to the user based on the inference results of the vehicle’s private information.
3.3 Problem Statement
The vehicle can evaluate the privacyp(k)by observing the received scams or spams similar to[16,8]to estimate the difference between the sensitivity of the inferred location by the adversaryand that of the actual locationl(k).The QoS lossq(k)is evaluated based on the Euclidean distance between its perturbed geo-locationand actual geo-locationd(k)according to[30]which can reflect the quality of user’s experience.The vehicle improves its location privacy by randomizing its released location to confuse the adversary.This also leads to the QoS loss because the vehicle uses the fake location to request the LBS.Thus,our work focuses on balancing the tradeoff between the privacy and QoS loss by adjusting the location perturbation policy.For ease of reference,our commonly used notions are summarized in Table 1.
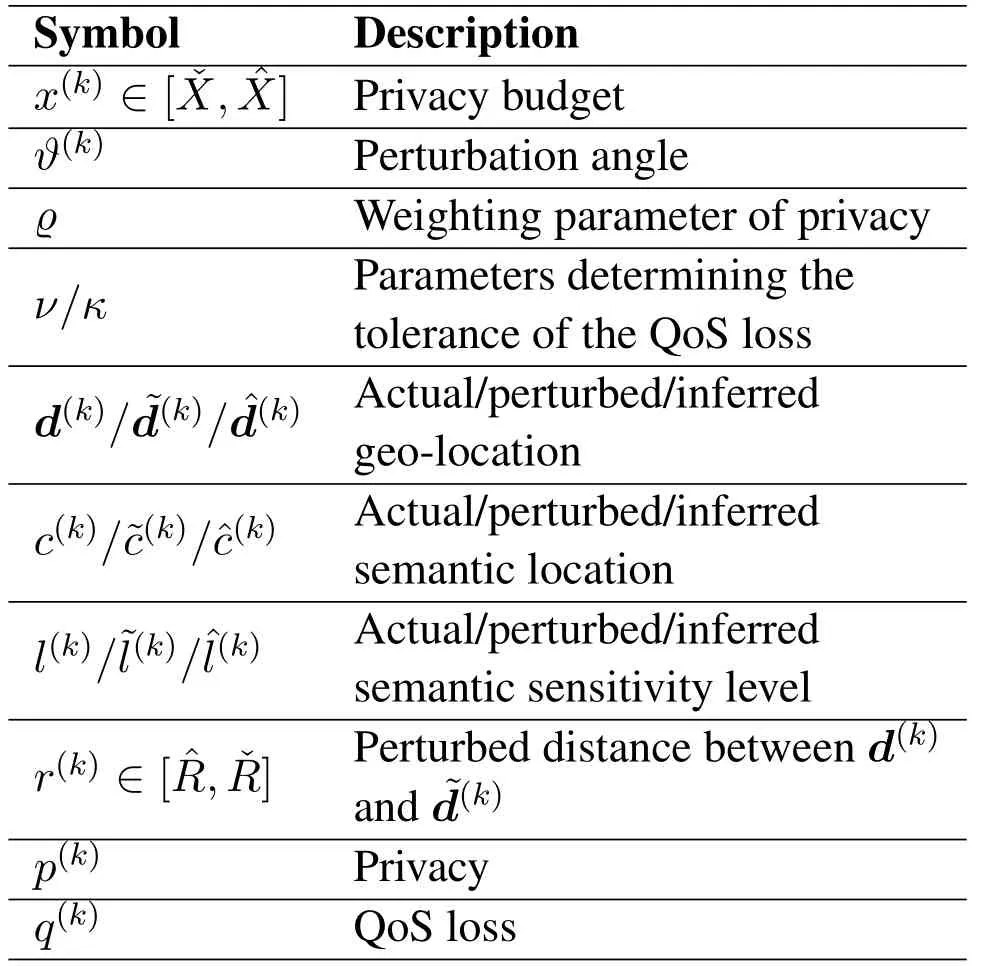
Table 1.List of Notations.
IV.RL-BASED SEMANTIC LOCATION PERTURBATION
The vehicle’s next state is only dependent on the current state and perturbation policy.It has nothing to do with the past location protection history.Thus,the vehicle’s location privacy protection process can be viewed as a MDP.In this section,we propose a RLbased semantic location perturbation scheme(RSLP)that enables a vehicle to act as a learning agent to optimize its perturbation policy in the dynamic location privacy protection process against adversaries without knowledge of the inference attack model.This scheme derives the optimal perturbation policy via trial-anderror based on the current states(k)consisting of the location of the vehicle,the sensitivity level of the semantic location,and the estimated attack strength history.
At time slotk,the vehicle observes its geo-locationd(k),the corresponding semantic locationc(k)and its sensitivity levell(k).The vehicle estimates its previous semantic location leakage withbased on the degree of correlation between the received scams or spams and the previous semantic locations similar to[16],which formulate the current states(k)=.

Algorithm 1.RL-based semantic location perturbation.1:Initialize the map,A,α,δ,ε and ?(0)2:Set Q ←Q based on the transfer learning method[37]3:for k=1,2,3,...do 4:Observe d(k)and c(k)according to the map 5:Evaluate the sensitivity level of current location l(k)6:s(k)=[d(k),c(k),l(k),?(k?1)]7:Select a(k)=[x(k),?(k)]according to:Pr(a(k)=a)=images/BZ_260_332_946_369_992.png1 ?ε, a=arg maxa′Q(s(k),a′)ε|A|?1, o.w 8:Sample r(k) ~Γ(2,1/x(k))9:Calculate ?d(k)via(2)10:Map the ?d(k)to ?c(k)11:Send(?d(k),?c(k))to the LBS server 12:Receive the response from the LBS server 13:Evaluate the privacy p(k)14:Evaluate the QoS loss q(k)15:Calculate the utility u(k)via(5)16:Q(s(k),a(k)) ←(1 ?α)Q(s(k),a(k))+α(u(k)+δ max a(k)∈A Q(s(k+1),a(k)))17:end for
Let parameterxdenote the privacy budget,andd1andd2are any two locations in possible regionsD.We use the idea of thex-geo-indistinguishability[10]to determine the perturbed distance in the sensitive semantic location protection.More specifically,the perturbation mechanism transforms any two actual locations to fake locations with a similar probability distribution.The similarity of the probability distributions is determined by the privacy budgetxand the selected circular with radiusR(R≥||d1?d2||2,?d1,d2∈D),with‖·‖2represents the Euclidean norm.This means that all the locations within the circle with radiusRare indistinguishable from the eyes of the adversary.The smaller privacy budgetxwill make the two distributions that transform any two actual locations to the fake location closer,which yields a higher privacy level.
In the RSLP scheme,the vehicle selects its action,i.e.,perturbation policywhich is made up of the privacy budgetwhereis the minimum privacy budget andis the largest privacy budget,and the perturbation an-under the constraint of semantic locations,as shown in Algorithm 1.More specifically,based on the selectedx(k),the vehicle firstly uses a gamma distribution to sample ar(k),i.e.,r(k)~Γ(2,1/x(k)),which represents the distance betweend(k)and.Then with?(k)determining the perturbation angle,the vehicle calculates the perturbed locationby
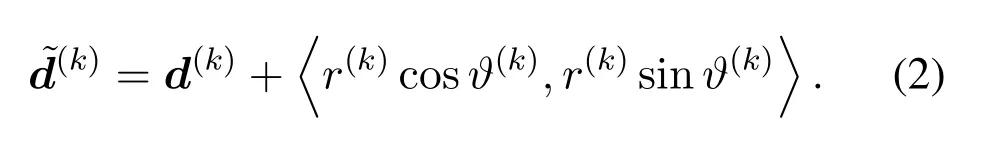
Theε-greedy policy is used to choose an action based ons(k)as a tradeoff between exploration and exploitation.
In the perturbation policy,the privacy budgetx(k)is used to trade off between the privacy and the QoS loss,and the angle?(k)is used to optimize privacy by controlling the perturbed semantic location’s sensitivity to be as low as possible.With the map and,the perturbed semantic locationcan be easily obtained.After that,the vehicle sends a service request together with its perturbed locationto the LBS server.Then the server sends the POI recommendations,maybe together with some scams or spams as feedback to the vehicle.
The vehicle then evaluates its privacyp(k)based on the received spams or scams similar to[8]and[16],that is to say,if they have certain relation with the current semantic location,the location privacy is leaked.The degree of privacy leakage can be represented by the difference between the inferred semantic location’s sensitivityand the actual semantic location’s sensitivity.Besides,the higher sensitive semantic location is located by the vehicle,the more effort should be made to hide its semantic location to gain higher privacy.Thus,we have
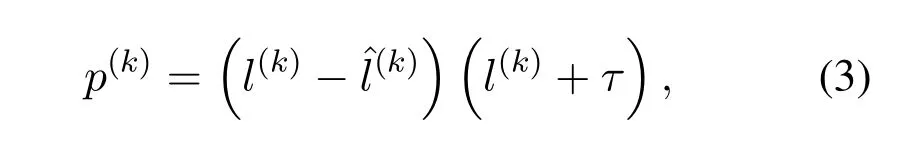
where the weighting parameterτis a constant andτ/=0.
The QoS loss is influenced by the perturbed distance and the type of LBS applications.According to[13],the QoS loss can be measured by the distance between the actual geo-location and the perturbed geo-location,which can reflect the quality of the user’s experience.As we all know that if the perturbed distance is larger,the POI recommendations or feedback results will be less accurate.Besides,we consider the QoS loss of different kinds of LBS applications has different sensitivity to the perturbed distance.For instance,the application of weather forecasts is less sensitive to the perturbed distance.As long as the perturbed location is within the area of a given city,the result will be the same.However,the QoS loss of the LBS application of traffic prediction is much more sensitive to the perturbed distance.This feature can be captured by parametersκandν.According to[38],if the perturbed distance becomes larger than the thresholdκ/ν,the QoS loss will drop faster.And the drop speed is determined by the parameterν.Thus,the QoS loss is given by
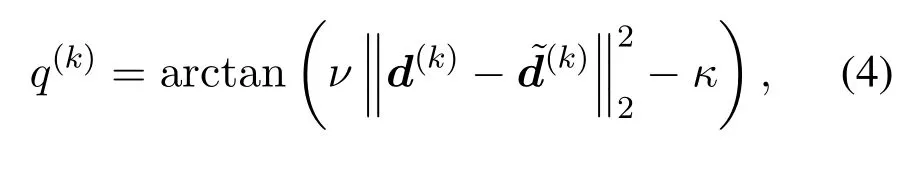
whereνandκdetermine the sensitivity of the QoS loss to the perturbed distance for a given LBS application.
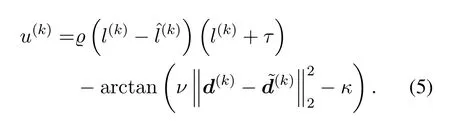
When the actual location is far away from nonsensitive ones,based on current LBS applications and current semantic location,if the vehicle treats the privacy more important than the QoS(i.e.,is large),then the vehicle tends to select a perturbed location located at a less sensitive area,even if it is far away.If the vehicle treats the QoS more important than the privacy(i.e.,is small),then the vehicle tends to select a perturbed location which is not very far away from the actual one,with a less sensitive location as much as possible.
The Q-functionQ(s,a)is the expected discount long-term reward of a vehicle that uses the perturbation policya(k)at states(k),which is updated according to the iterative Bellman equation as shown in Algorithm 1.We use the transfer learning method in[37]to initialize the Q-values aswith location perturbation experiences in similar VANET environments such as a number of typical attack strength of adversary and map type.
V.DEEPDETERMINISTICPOLICY GRADIENT-BASED SEMANTIC LOCATION PERTURBATION
The RSLP-based semantic location perturbation scheme is inefficient for vehicles in a big map with a large amount of states,and the naive discretization of perturbation policy spaces may cause the vehicle’s failure to find the globally optimal perturbation policy to protect the vehicle’s sensitive semantic locations.To meet the demand of the vehicle’s privacy protection with practical complicated VANET system and highdimensional continuous perturbation policy space,we propose a DDPG-based semantic location perturbation scheme(DSLP)to explore the policy spaces efficiently and improve the sensitive semantic location protection performance.
As shown in Figure 2,the DSLP architecture consists of the critic network and actor network.They are parameterized by the functionsQ(s,a|θ)andu(s|ω)with parametersθandω,respectively.The vehicle uses the actor network to select a perturbation policy from a continuous action space and uses the critic network to evaluate the performance and criticize the perturbation policy selected by the actor part.The vehicle also maintains the target critic and actor networks to calculate the target values for the critic network updating,in which these two target networks output functionsQ′(s,a|θ′)andμ′(s|ω′)with parametersθ′andω′.
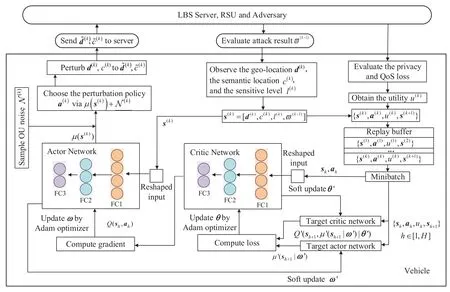
Figure 2.Illustration of the deep deterministic policy gradient-based semantic location perturbation scheme for the vehicle.
More specifically,Algorithm 2 illustrates the detail of DSLP.The vehicle first initializes the system parameters and then observes the current states(k)similar to Algorithm 1.Then the vehicle reshapes the state and inputs it into the deep neural network(DNN)of the actor network with three fully connected(FC)layers.The DNN can capture the attack model features and location perturbation details.
At time slotk,the vehicle chooses the perturbation policya(k)=[x(k),?(k)]in a continuous action space,in whichis the privacy budget and?(k)∈[0,2π)is the perturbation direction.a(k)is selected by the actor network by mapping every state to a determined action with functionμ(s(k)|ω(k)).To improve the exploration efficiency,a noisesampled from an Ornstein-Uhlenbeck(OU)process[39]is added toμ(s(k)|ω(k))to generate temporally correlated exploration in the learning process,i.e,.After that,the perturbed locationis generated as in Algorithm 1.The vehicle then sendsto the LBS server to protect its true location.
After the perturbed location is released to the LBS,the vehicle evaluates its privacyp(k)and QoS lossq(k)to obtain its utilityu(k).The next state is formulated ass(k+1)=[d(k+1),c(k+1),l(k+1),?(k)].In order to learn in minibatch to make efficient perturbation policy optimizations,the experience consisting of the current states(k),the selected perturbation policya(k),the obtained utilityu(k),and the next states(k+1),i.e.,e(k)={s(k),a(k),u(k),s(k+1)}are sampled from the dynamic VANET environment based on the exploration policy and stored in a replay buffer.Thus,the vehicle can make full use of a set of uncorrelated transitions to explore the optimal perturbation policy.Since the storage space of the replay buffer is finite,the oldest experiences need to be discarded on a rolling basis.
During the updating process of the critic and actor networks,the vehicle randomly choosesHexperiences from the replay buffer and formulate the minibatch,with theh-th experienceeh={sh,ah,uh,sh+1},h∈[1,H].We use Adam optimizer to update the critic network’s weightsθwith the aim of minimizing the following loss function,
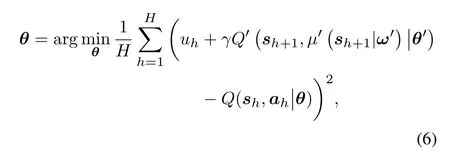
whereγ∈[0,1]is the discount factor indicating the vehicle’s uncertainty of the future reward.
The actor network’s weightωis also updated based on Adam optimizer with respect to the direction of the Q-value gradient as follow,

Algorithm 2.DDPG-based semantic location perturbation.1:Initialize the map,A,?(0),ω,θ and N(0)2:for k=1,2,3,...do 3:Observe d(k)and c(k)according to the map 4:Evaluate the sensitivity level of current location l(k)5:Formulate the current state s(k)=[d(k),c(k),l(k),?(k?1)]6:Input the current state to the DNN of the actor network 7:Select a(k)=[x(k),?(k)]according to:a(k)=μ(s(k)|ω)+N(k)8:Perform the location perturbation and evaluate the performance as Steps 8-15 in Algorithm 1 9:Store {s(k),a(k),u(k),s(k+1)} in the replay buffer 10:Sample minibatch{sh,ah,uh,sh+1},h∈[1,H]from the replay buffer 11:Update the online networks ω and θ via(6)and(7)12:Soft update the target networks ω′and θ′via(8)13:end for
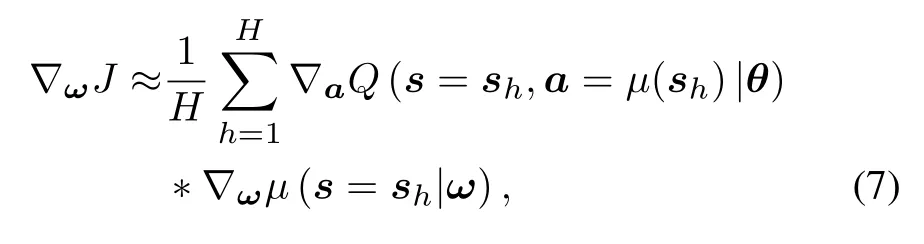
where?aQ(s,a|θ)is the Q-function’s policy gradient with respect to actiona.Similarly,?ωμ(s|ω)is the actor function’s policy gradient with respect toω.Instead of directly copying the weights of the critic and actor networks,the vehicle uses the soft update to keep the output of the target critic and actor networks with parametersQ′(s,a|θ′)andμ′(s|ω′)changing slowly while updating.Thus,the learning stability can be improved.More specifically,with a learning rateζ ?1,the critic and actor networks’learned weights are tracked slowly based on the soft update,updating by
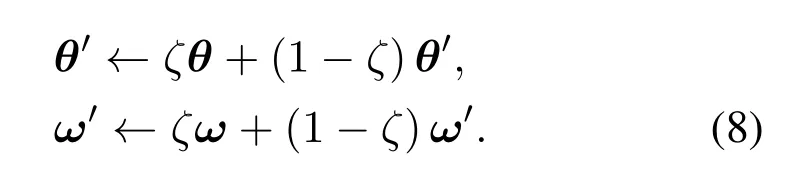
The vehicle can apply the same neural network to select the location perturbation policy even if the environment such as the attack model and the map change.That’s because the proposed learning-based location perturbation scheme is a model-free and reinforcement mechanism,the vehicle can dynamically observe the current VANET environment and vehicle’s state and input them into the DNN.The DNN can capture the feature of the variant environment and uses the stored location perturbation experiences to update the network parameters dynamically.In this way,the proposed learning-based location protection scheme can adapt to various attack models and the dynamic VANET environments.
Now,we illustrate how to apply our proposed scheme in a real platform.The vehicle can use the proposed learning-based semantic location protection scheme to protect its highly sensitive semantic locations locally without a trusted third-party.The scheme can be implemented into a real vehicle with the following five steps.
First,we need a GPS-capable IoT platform installed in the vehicle that can support deep learning.
Second,we develop an API based on the“Location Guard”via JavaScript.According to the paper[10],the Location Guard API implements a location perturbation technique by adding noise from a planar Laplace distribution.To develop an API to support our proposed scheme,we modify the Location Guard API and consider the factor of the semantic location’s sensitivity during the perturbation process to control the perturbation range.When the user requests the LBS,the vehicle does not send the actual GPS location directly.Instead,based on the user’s demands,the vehicle applies the modified Location Guard to add random noise to the actual GPS location,creating a perturbed location.The vehicle only sends this perturbed location to the LBS server.
Third,we need to pre-process the map.Since the state of the learning scheme has to be limited,the map visited by the vehicle must have a bound.That means that the vehicle moves around in a given limited area.We divide the limited map into grids.We can make the grid fine-grained if the area is bustling and crowded,and we make the grid coarse-grained if the area is wide and empty.With the grids on the map,the semantic and sensitivity level of each grid can be marked.
Fourth,based on the current semantic location,the previous attack result,and the current LBS application type,the vehicle uses the proposed location protection scheme to select the perturbation policy,including the privacy budget and perturbation angle.Then,the vehicle inputs the selected privacy budget and perturbation angle to the modified Location Guard API to generate perturbed locations.The vehicle sends the perturbed location to the LBS server.After that,the LBS server sends the POI recommendations,maybe together with some scams or spams as feedback to the user[8].
Finally,the user evaluates the privacy by observing the received scams or spams similar to[16,8].The QoS loss is evaluated based on the Euclidean distance between its perturbed geo-location and actual geo-location according to[30].The user then adjusts its perturbation policy based on the evaluation results.In this way,the vehicle user can adaptively protect semantic locations locally.
VI.SIMULATION RESULTS
This section evaluates the performance of the proposed learning-based semantic location perturbation schemes for VANET.Simulations have been performed for a vehicle in a square map with equal width and length of 6 km,which is divided into a 10×10 grid with different semantic locations such as hospital,bank,and school.The semantic locations in the map belong to 4 different sensitivity levels from level 0 to level 3.These values are selected to show the difference in the sensitivity of semantic location in the simulation.They can represent different actual values in the real world.The simulation topology is shown as Figure 3.
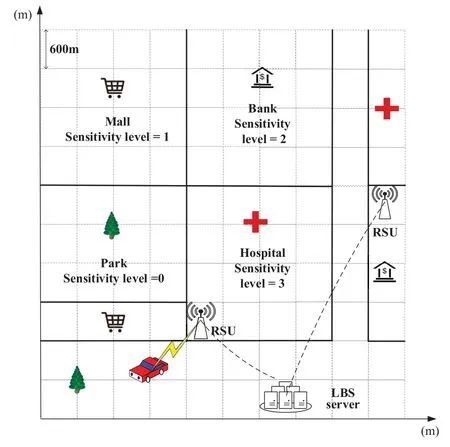
Figure 3.Simulation topology with a map divided into 10×10 grids,in which different semantic locations have different sensitivity levels and has different privacy demand from the user’s point of view.
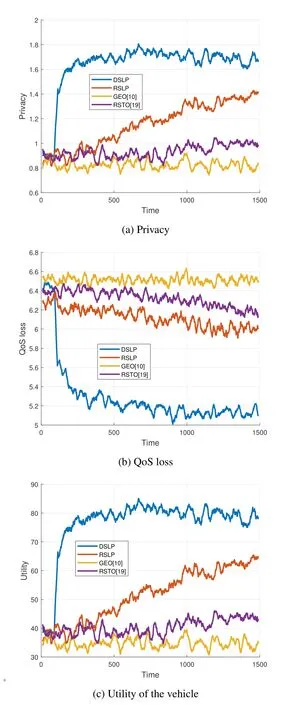
Figure 4.Performance of the learning-based semantic location perturbation scheme for a vehicle in a map with 10×10 grids,in which the user tends to protect the highly sensitive semantic location.
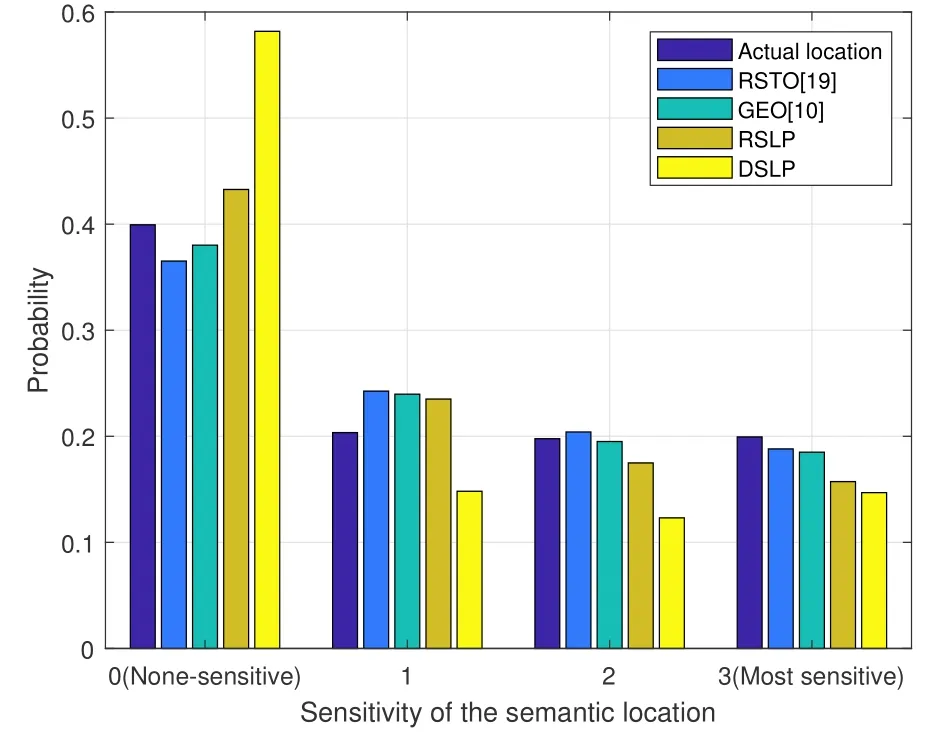
Figure 5.Comparison of the location sensitivity probability distribution of actual locations and inferred locations with different perturbation schemes.Numbers 0,1,2,3 represent the sensitivity level of semantic locations,in which 3 denotes the location with the highest sensitivity level and 0 denotes the lowest sensitivity level.
We consider the following typical case:Mike leaves his apartment at 8:00 am requesting a traffic congestion prediction service to find the quickest way to the hospital.He parks here for 1.5 hours to meet his doctor.After that,he requests a nearby supermarket with good reviews and decides to drive to a mall where he stops for 40 minutes.Next,he drives to a bank and parks for an hour.In the simulations,one time slot is a time interval of two adjacent LBS queries.The vehicle’s speed is set to be no more than 36 km/h,and thus it can move to an adjacent grid at most during one time slot.The transition of the vehicle in the grid map is modeled as a Markov chain.According to[40],the privacy budgetx∈(0,1.4],the privacy weight over the QoS loss is set to be 5.
In the simulations of the learning algorithm,the learning rate is set to be 0.7 and the discount factor is set to be 0.5.Theε-greedy parameter is annealed from 1.0 to 0.1 during the first 500 time slots in the process of learning,after thatεis fixed to 0.1 for stability.As the benchmark schemes,the geo-indistinguishability scheme(GEO)in[10]and the reinforcement learningbased location obfuscation scheme(RSTO)in[19]neglecting semantic locations with different sensitivities are evaluated.The change of the number of semantic locations,the value of sensitivity levels,or the user’s mobility profile can observe a similar trend as the current typical case.Even though the convergence time and convergence value might be different from the current case,they will not impact the advantage of the proposed schemes compared with the benchmarks.
The performance of the proposed RSLP and DSLPbased schemes are reported in Figure 4.The proposed RSLP and DSLP-based schemes both outperform the benchmark RSTO and GEO-based schemes.That is because the RSTO-based scheme and Geobased scheme just consider selecting a perturbed location outside of the actual semantic location or just consider the perturbed distance,which neglect the protection of highly sensitive semantic locations.This will cause an overestimate or underestimate of the location privacy.The RSLP and DSLP-based schemes significantly improve the QoS of the LBS applications,increase the semantic location privacy,and increase the vehicle’ utility.Moreover,with the continuous perturbation policy space,the DSLP-based scheme can learn a better perturbation policy and further improve the scheme’s performance compared with the RSLPbased scheme.The DSLP-based scheme reduces the discretization error compared with the RSLP-based scheme and can avoid converging to the local optimal.For instance,at about 1500th time slot,the RSLP-based scheme increases the privacy by about 77.51% and 43.43%,reduces the QoS loss by about 7.69%and 2.44%,and improves the utility by 88.24%and 51.16%compared to the GEO-based scheme and RSTO-based scheme,respectively.The DSLP-based scheme further improves sensitive semantic location privacy protection performance.For instance,at the 1000th time slot,it improves the privacy by 30.77%,reduces the QoS loss by 15.69%,and increases the utility by 33.33%,compared with that of the RSLPbased scheme.
Figure 5 illustrates that the proposed sensitive semantic location privacy protection schemes tend to protect the semantic locations with higher sensitivity by inducing the adversary’s inference results to less sensitive semantic locations.For instance,even though the actual semantic location with the lowest sensitivity level 0 is 40.00%,the inferred semantic location with the lowest sensitivity level 0 of the DSLPbased scheme is 59.05%.While the actual semantic location with the highest sensitivity 3 is 20.00%,the inferred semantic location with the highest sensitive 3 of the DSLP-based scheme is only 14.50%,which is 27.50% lower than the actual one.We can see that the inferred probability distribution of locations with different sensitivities of the RSTO and GEO-based schemes are close to that of the actual distribution,which means that the RSTO and GEO-based schemes fail to protect locations with high sensitivity.
Figure 6 illustrates the relationship between the location privacy protection performance and the prior knowledge accuracy level of the adversary.The results show that the average privacy and utility decreases with the prior knowledge accuracy level of the adversary changes from 0.02 to 0.14.That’s because the larger prior knowledge of the adversary improves the accuracy of the inference.The change of the prior knowledge accuracy level has little influence on the QoS loss.For instance,if the prior knowledge accuracy level of the adversary is 0.14 instead of 0.02,the privacy is reduced 10.85%,and the utility decreases about 11.86% of the DSLP-based scheme.Note that the DSLP-based scheme can achieve better privacy and utility performance even with a high prior knowledge accuracy level of the adversary.For example,when the prior knowledge accuracy level of the adversary is 0.14,the DSLP-based scheme has 89.71%higher privacy,and 1.07 times higher utility compared with that of the GEO-based scheme.
Figure 7 shows the relationship between the location privacy protection performance and the map size.The results show that the average QoS loss increases with the map size changes from 10*10 to 50*50,and the average privacy and utility of the vehicle slightly decrease with the map size.That’s because the larger map size consists of many more system states which need more time to derive the optimal perturbation policy for the vehicle.For instance,if the vehicle visits the map size of 50*50 instead that of 10*10,the privacy reduces 6.45%,the QoS loss increases 56.94%,and the utility decreases about 12.86%.However,we can also see that the DSLP-based scheme can achieve better privacy and QoS performance even with large map size.The DSLP-based scheme uses DNN as a nonlinear approximator of the Q-value for each perturbation policy to accelerate the learning speed.For example,when the map size is 50*50,the DSLP-based scheme has 15.36%higher privacy,21.62%lower QoS loss,and 16.02%higher utility compared with that of GEO-based scheme.

Figure 6.Average performance of the learning-based semantic location perturbation scheme averaged over 1500 time slots,with the prior knowledge accuracy level of the adversary changes from 0.02 to 0.14.
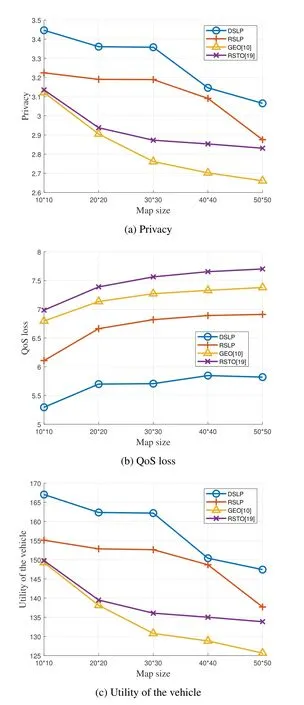
Figure 7.Average performance of the learning-based semantic location perturbation scheme averaged over 1500 time slots,with the map size changes from 10*10 to 50*50.
VII.CONCLUSION
In this paper,we have proposed the RL-based semantic location perturbation scheme for vehicles,which protects the sensitive semantic location data while reducing the QoS loss.The vehicle uses the idea of differential privacy technique to perturb the semantic location and it applies the RL-based scheme to derive the optimal location perturbation policy without knowledge of the interference adversary model in the dynamic VANET.
A DSLP-based scheme is also proposed to select the privacy budget and perturbation angle from a continuous-valued perturbation policy set to further improve the sensitive location privacy protection performance.Simulation results demonstrate that the proposed schemes can increase the privacy,decrease the QoS loss,and thus improve the utility of the vehicle compared with the benchmark GEO-based scheme which does not consider the sensitivity of semantic locations.For example,the DSLP-based scheme decreases the QoS loss by 7.69%,while increasing the privacy by 77.51%,and improving the utility by 88.24% compared with the benchmark GEO-based scheme.Although this scheme has been proposed to protect sensitive semantic locations of vehicles,we believe that the scheme can also be used to protect the semantic trajectory data in location data publishing[41].Besides,we have analyzed the feasibility of the proposed schemes,and we consider implementing them to the real VANETs in our future work.
ACKNOWLEDGEMENT
This work was supported in part by National Natural Science Foundation of China under Grant 61971366 and 61771474,and in part by the Fundamental Research Funds for the central universities No.20720200077,and in part by Major Science and Technology Innovation Projects of Shandong Province 2019JZZY020505 and Key R&D Projects of Xuzhou City KC18171,and in part by NSF EARS-1839818,CNS1717454,CNS-1731424,and CNS-1702850.

- China Communications的其它文章
- LED Adaptive Deployment Optimization in Indoor VLC Networks
- Boosting Unsupervised Monocular Depth Estimation with Auxiliary Semantic Information
- Bit-Level Composite Signal Design for Simultaneous Ranging and Communication
- Joint 3D Trajectory and Resource Optimization for A UAV Relay-Assisted Cognitive Radio Network
- A Blockchain-Based Credible and Secure Education Experience Data Management Scheme Supporting for Searchable Encryption
- Sparsity-Aware Channel Estimation for mmWave Massive MIMO:A Deep CNN-Based Approach