
Correlation-Aware Replica Prefetching Strategy to Decrease Access Latency in Edge Cloud
2021-10-15 09:19:04YangLiangZhigangHuXinyuZhangHuiXiao
China Communications 2021年9期
Yang Liang,Zhigang Hu,Xinyu Zhang,Hui Xiao
1 School of Computer Science and Engineering,Central South University,Changsha 410083,China
2 School of Informatics,Hunan University of Chinese Medicine,Changsha 410208,China
3 TCM Big Data Analysis Laboratory of Hunan,Hunan University of Chinese Medicine,Changsha 410208,China
Abstract: With the number of connected devices increasing rapidly,the access latency issue increases drastically in the edge cloud environment.Massive low time-constrained and data-intensive mobile applications require efficient replication strategies to decrease retrieval time.However,the determination of replicas is not reasonable in many previous works,which incurs high response delay.To this end,a correlation-aware replica prefetching (CRP) strategy based on the file correlation principle is proposed,which can prefetch the files with high access probability.The key is to determine and obtain the implicit high-value files effectively,which has a significant impact on the performance of CRP.To achieve the goal of accelerating the acquisition of implicit highvalue files,an access rule management method based on consistent hashing is proposed,and then the storage and query mechanisms for access rules based on adjacency list storage structure are further presented.The theoretical analysis and simulation results corroborate that CRP shortens average response time over 4.8%,improves average hit ratio over 4.2%,reduces transmitting data amount over 8.3%,and maintains replication frequency at a reasonable level when compared to other schemes.
Keywords: edge cloud; access latency; replica prefetching;correlation-aware;access rule
I.INTRODUCTION
With the rapid development of Internet of Things(IoT)in various fields,the number of terminal devices continues to grow steadily,including various machines,sensors,cameras,and other IoT components[1].According to a research report released by International Data Corporation (IDC),there will be 41.6 billion IoT devices by 2025,generating 79.4 Zettabytes(ZB)data.Considering that QoS is usually adopted as the criterion in mobile scenarios,IoT applications have higher requirements in terms of real-time data processing[2].The cloud computing paradigm is responsible for managing the overall allocation of resources that can provide adequate resources,such as unlimited storage and processing capacity; however,it can cause unbearable and unpredictable access latency as the data is typically stored in the remote cloud data centers[3].Therefore,the dawning of Internet of Everything (IoE) era has pushed the horizon of a new computing paradigm,edge computing,which calls for processing the data at the edge of the network.In general,the edge cloud environment includes three main components as follows:center cloud,edge clouds,and edge devices.As edge clouds are distributed in different geographical locations and serve users nearby,they can achieve lower response latency than traditional cloud computing services.Moreover,the edge cloud system has a significant potential for saving network bandwidth,alleviating central cloud pressure,and improving data availability[4-6].
Due to the limited storage capabilities,however,most edge nodes can only store partial data resource,while the data requested by the users may be located on a remote edge cloud node.Thus,data access latency is still one of the critical issues in the edge cloud environment.The long transmission distance may lead to high access latency,data access timeout,or even data loss.
To the best of our knowledge,the replication technique is one of the effective methods to reduce data access delay in data-intensive application scenarios[7].Creating the replicas of the relevant data on a specific node in advance can ensure the smooth and efficient execution of the user-submitted jobs.However,given the limitation of edge node storage resources,the replicas cannot be created arbitrarily.A suitable replica management mechanism has become an important challenge for the efficient operation of the edge cloud system[8].
Generally,the typical replica management process consists of replica placement,replica selection,and replica replacement phases[9-12].Replica placement determines the best possible location for replications while replica selection chooses the appropriate replica location to access the data file for job execution.Replica replacement,playing a leading role in the edge cloud environment,determines which replica to be replaced or deleted.In recent years,many works address replica strategies based on local data access history,but few of them focus on the intrinsic correlation between these data[13-15].In fact,some files may be accessed multiple times in the future even though they have not been accessed by local nodes so far.Relevant studies have shown that users who are geographically close to each other tend to access the same or more relevant files.For example,after an edge node receives a file access request,it is likely that additional aggregate requests related to that file will still appear on that node for a period of time.Hence,if files highly related to historically accessed files are excavated and duplicated to nearby edge nodes beforehand,they can be obtained as soon as possible when needed in the future.However,the biggest challenge is that these highly relevant files may not yet have access records at local edge nodes,making it difficult to determine them through traditional queries and statistics.In addition,the traditional replica strategies based on historical access records have a certain degree of blindness and lag in creating and updating replicas,causing a lot of unnecessary resources overhead.
In order to solve the above issues,we propose a correlation-aware replica prefetching (CRP) strategy to decrease access latency in the edge cloud.The CRP strategy gives sufficient consideration to the possibility of the files being accessed,by mining and prefetching replicas of the file that are highly correlated to the accessed file.Besides,considering the impact of file dynamic popularity on prefetching performance,the CRP strategy constructed a set of prefetch rules based on dynamic support.In CRP strategy,the locality principles of file access are considered when prefetching the replicas,so that the determination of creating replicas is more reasonable in the edge cloud environment.CRP strategy can ensure real-time response and storage space utilization rate,thereby improving the QoS.In summary,our major contributions in this work are listed below:
(1) The files with access requirements are divided into explicit high-value files and implicit high-value files.A replica collaborative prefetching architecture in the edge cloud environment is proposed,and a prefetching module is set at each edge cloud node to provide collaborative prefetching services for edge cloud nodes in need.
(2) The abstract definition of access rules is given,the consistent hashing technique is introduced to construct the storage and query mechanism based on access rules.A sequential and chain hybrid storage structure is proposed.
(3)The process of replica collaborative prefetching in the edge cloud environment is designed,and the related core algorithms are proposed,mainly including access rules storage algorithm and access rules query algorithm.
(4) Extensive simulations have been conducted to evaluate the performance of the proposed strategy.The experimental results demonstrate that the CRP strategy can effectively reduce file access latency and provide users with satisfactory QoS.
The remainder of this paper is organized as follows:Section II reviews related works.In Section III,a replica collaborative prefetching architecture is constructed.Section IV focuses on the proposed strategy with detailed procedures.Section V presents the experimental results along with a performance evaluation of our strategy in comparison with other methods.Finally,Section VI concludes the paper.
II.RELATED WORK
One of the most popular issues in edge computing is access latency.This issue has attracted international attention from researchers in the last few years.In this section,a review of some relevant prior investigations will be discussed.
As data-intensive tasks that require large amounts of data storage and powerful computing resources are becoming more common,reducing data processing latency has become a cumbersome challenge given the limited resources of many lightweight edge servers.To address this problem,Jin et al.proposed an edgecloud collaborative storage framework called Edgecloud Correlation-aware Storage(ECS)in[16],focusing on how to effectively place data on ECS and reduce the possibility of shifting tasks to cloud data centers.
To effectively solve the problem of bandwidth bottleneck,communication overhead,and location blindness experienced by mobile users when accessing remote clouds caused by high access latency in mobile scenarios,Vales et al.[17]proposed and implemented a solution that pooled the storage resources of mobile devices and fog nodes for deploying an edge cloud.
In order to shorten the transmission delay between the user equipment and the edge node,Chang et al.[18]proposed an adaptive replica mechanism to obtain better benefits by reducing the average response time of tasks and improving the efficiency of data grouping.
As user mobility may increase the migration requirements of applications between edge servers,problems such as access delays and increased costs may be caused.To solve these limitations,Frangoudis et al.proposed a relationship analysis model of service copy cost and service migration cost based on the Markov chain in[19].
In[20],Monga et al.provided a novel distributed storage service for artificial edge resources,which adopted a unique differential replica mechanism.The proposed method avoids unnecessary movements of the short-term stored IoT data among remote data centers and reduces the cost of network transmission.
To improve the performance of the mobile edge cloud,Wu et al.[21]proposed the Algorithm of Collaborative Mobile Edge Storage (ACMES) that was able to minimize the delay of task execution and total costs for overall operation.By providing a method that the mobile edge cloud can make a storage scheduling decision at the edge environment directly and execute at the same time,ACMES is capable of providing more immediate services than conventional methods.
In[22],Teranishi et al.proposed a dynamic data flow platform for IoT applications in the edge computing environment,which not only enables IoT applications to achieve small delays but also avoids IoT applications from overloading the network and computing resources.
To reduce the response time of applications,provide high availability,and make system load balancing,Mansouri et al.proposed a new data replication strategy called hybrid replication strategy (HRS) in[23].HRS can be adapted according to changes in a distributed environment,which not only reduces access latency but also keeps the whole storage system stable.
As the problem of network congestion is becoming more and more serious due to the massive data generated by intelligent terminal devices,Xing et al.[24]proposed a distributed multi-level storage system (DMLS) model for edge computing based on a multiple-factors LFU (mLFU) replacement algorithm to solve the problems of limited storage space and data access timeout.
To tackle the problem of latency-aware and costefficient placement of data replicas at the edge of the network,Aral et al.[25]present a distributed data dissemination approach that relies on dynamic creation/replacement/removal of replicas guided by continuous monitoring of data requests coming from edge nodes of the underlying network.
In order to address the problem of trunk network traffic and access latency increasing significantly while a large number of users can access the same resource simultaneously,Tang et al.[26]present a novel replica placement strategy for mobile media streaming in edge computing (RPME) to provide an acceptable QoS.
To solve the problem of data replica management and task scheduling for delay-sensitive IoT workflow in edge computing,a novel data replica management system is proposed in[27],consisting of the replica creator and workflow data job scheduler.
In[28],a multi-robot system based on edge cloud is proposed to overcome the limitations of the remote cloud-based framework in performing continuous sensitive tasks,and the multi-objective evolutionary algorithm NSGA-II is redesigned to solve the optimization problem.
An adaptive discrete particle swarm optimization algorithm based on a genetic operator is proposed in[29],which can rationally arrange the data location of scientific workflow and optimize the data transmission time.
In[30],Mansouri et al.proposed a new dynamic data replication strategy called Prefetchingaware Data Replication (PDR),which determines the dependencies between files in accordance with the file access history and prefetches the most popular files.
With the network delay becoming a major constraint in remote file system access,Li et al.presented a scheduling-aware data prefetching scheme to enhance non-local map task’s data locality in a centralized hybrid cloud (CHCDLOS-Prefetch) in[31].Furthermore,to minimize the overhead of the storage system and reduce the access latency as well as to maintain load balancing across the system and avoid the long delay or network congestion,Li et al.proposed a dynamic multi-objective optimized replica placement and migration strategies for SaaS applications in[32],solved by the fast non-dominated sorting genetic algorithm.
In the above works,the bottleneck of the system performance caused by high access latency was improved to some extent.However,they were lagging and blind for use in the edge cloud environment in terms of average response time and hit ratio when requesting services.So it is necessary to fully consider the characteristics of edge cloud storage and file access,and explore an appropriate file prefetch mechanism to further reduce the latency of data access.
III.PRELIMINARIES
In this section,we firstly illuminate and analyze file access characteristics.Then,some related definitions are given for evaluating file access value.Finally,we design a correlation-aware replica prefetching architecture.
3.1 File Access Characteristics
To minimize access delay and maximize data availability,we focus on the selection of files to be duplicated,replication trigger conditions,and replica storage locations.Due to the limited storage resources of edge nodes,it has become a consensus to prioritize the replica creation of higher-value files.It has been proved that it is an effective way to improve the efficiency of replication to fully consider the correlation between files in replication.
Many studies have shown that users with similar interests tend to access the same or more relevant files.Jobs submitted by geographically close users are more likely to have access to the same or more relevant files.When facing the same type of application,there is indeed an aggregation request for related files.The correlation between files can not only be reflected in the similarity of file contents but also can be reflected by specific file access methods.For instance,files accessed consecutively are of great relevance.Generally,there are three types of file access locality characteristics as follows:(1) Time locality; (2) Geographical locality;(3)File locality.
Time locality means that a recently accessed file may be accessed again,which has been used in many replica management strategies.
Geographical locality,also known as user locality,refers to the possibility that a file that was recently accessed by a user may be accessed again by a user who is nearby.Whether the two users are“adjacent”to each other is not determined by the physical distance between them,but by whether they have similar interests.That is,files accessed by one user are more likely to be accessed by other nearby users on other nodes.
File locality,also known as spatial locality,reveals that files“adjacent”to the file that has just been accessed are likely to be accessed.“Proximity”between files does not refer to physical proximity,but a greater correlation between files.
According to the law of file locality,we deduced that the highly relevant files tend to be accessed continuously by the user,while the continuously accessed files must be close to each other in the file access sequence.
3.2 Definitions
Considering the file local access characteristics,some relevant definitions are given for the sake of description and discussion.
Definition 1.(file value)File value represents the possibility that will be accessed over a period of time.
In this work,the file value is used to quantify the access probability of various files,which serves as an important basis for whether to create a replica for the file.
Definition 2.(explicit high-value file)The explicit high-value file indicates that the file that already has more access records on the local node.
Obviously,obtaining explicit high-value files needs to be based on file access history.The preference for creating replicas of explicit high-value files is consistent with the time-local access characteristics.Then the evaluation of the explicit-high value file can be expressed as
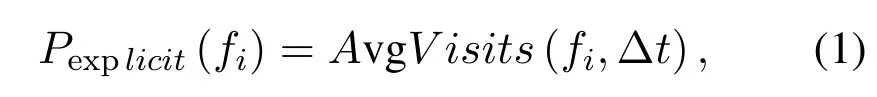
wherePexplicit(fi)denotes the explicit value of filefion the local node,whose value is equivalent to average access times of filefiwithin a given time interval Δt.IfPexplicit(fi) is greater than the given threshold value and the filefiis not stored locally,the local node needs to obtain a replica offifrom the remote node wherefiresides.
Definition 3.(implicit high-value file)The implicit high-value file indicates that the file has never been accessed by the local node so far,but is likely to be accessed multiple times in the future.
After obtaining the replica of an explicit high-value file,we attempt to introduce replicas of files that are highly relevant to the explicit high-value files to further reduce local data access latency.If these highly relevant files are not stored locally,they are called implicitly high-value files.However,the implicit highvalue file has never been accessed on the local node,so it is difficult to predict and confirm the file from the local file access records.
To solve the above problem,we explored a collaborative prefetch process to obtain replicas of implicit high-value files.Based on geographic locality and file locality,the process enables the local node to obtain the required replica file from the corresponding remote node.
3.3 Design of CRP System Architecture
In order to illustrate the validity of the collaborative prefetch process for creating the appropriate replicas in the edge cloud environment,we design a correlation-aware replica prefetching overall architecture,as depicted in Figure 1.

Figure 1. CRP architecture.
As shown in Figure 1,the whole system is roughly composed of three different layers:central cloud layer,edge cloud layer,and user layer.
The central cloud layer is on the top of the system,consisting of a large number of high-performance servers with huge storage capacity and computing capability.Its main responsibility is to implement the final data analysis and application and collaborate with the edge layer to provide users with the required services.As the pillar of network computing,storage,and connection,it ensures the stable and orderly operation of the whole network.
The edge cloud layer is located at the edge of the network,consisting of a variety of heterogeneous underlying edge servers.It is in charge of providing users with the network,computing,storage,and other resources nearby,which can better meet the needs of users for real-time business.Being closer to the enduser,it enables more efficient tracking,processing,and storage of data,and improves the quality of service.However,with the exponential growth of IoT data,service delay caused by untimely data acquisition has become one of the main bottlenecks of system performance.To further solve the above problem,the edge cloud will decrease data access latency by adopting prefetch technology at the edge of the network to support data replica prefetching.In the architecture of Figure 1,we added a prefetch module(PM)on each edge cloud platform.PM consists of three submodules,including the file access logs,access rule base,and prefetching engine.The file access logs are used to record all file access histories of local nodes.The access rule base has an obligation to preprocess the history records in the file access logs and extract frequent file access rules.The prefetching engine is responsible for issuing file prefetch requests to other nodes and receiving the returned prefetch file information,as well as receiving file prefetch requests from other nodes and returning relevant prefetch file information.When a node receives a file prefetch request from another node,the collaborative replica prefetch mechanism is started immediately.Each prefetch file message is sent as a quadruples (file identifier,file value,file location,file size) to one or more nodes making the prefetch requests.Then,the obtained replica is stored in the local prefetch pool,which is an independent storage space for storing the prefetched replica on the edge node.However,due to the limited storage space of the prefetch pool,LRU algorithm is adopted to manage the local prefetch pool,avoiding the size of the prefetched replica exceeding the available storage space of the edge node.
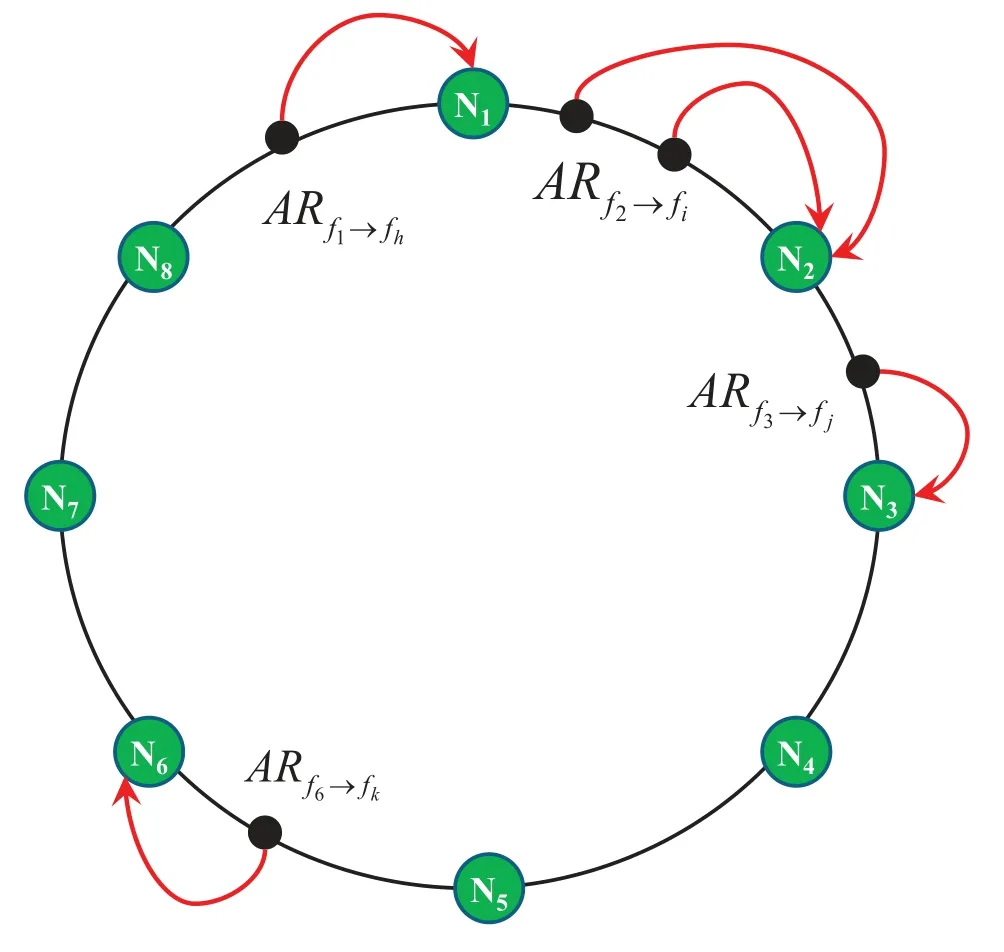
Figure 2. ARMCH schematic.
The user layer is mainly composed of numerous pervasive user devices,which are randomly distributed geographically.On the one hand,the user layer can generate a large amount of data through various terminals;on the other hand,it serves as the application interface for users to request services from higher-level networks and obtain the service from the upper nodes.To wit,the same equipment can act as different roles in different situations.Take the smartphone as an example,it is not only a data producer but also a data consumer.
In this work,the PMs in each edge cloud are not independent of each other but cooperate to provide file prefetching services for the edge cloud.The prefetching process can be described as follows:First,the PM of one node sends a file prefetching request to the PM of the other nodes; Second,the relevant node accepts the request and sends the prefetching file information back to the prefetching request node; Finally,the requesting node selects files with higher implicit value to prefetch based on the received prefetching file information.
IV.CORRELATION-AWAREREPLICA PREFETCHING SCHEME
In this section,we firstly design the overall process of correlation-aware replica prefetching based on file access rules;Secondly,an innovative storage mechanism for file access rules is proposed;Finally,we present a query mechanism for file access rules accordingly.
4.1 Correlation-aware Replica Prefetching Process
In a correlation-aware replica prefetching scenario,the local prefetch module receives file prefetching requests from other nodes.Then,the local access rule base is queried to determine which implicit high-value files need to be prefetched and information about these files is eventually returned to the prefetching request node.
With the continuous submission and execution of jobs on the local edge cloud,the access rule base needs to preprocess its file access logs synchronously.The sequential file request sequence,as one of the results of preprocessing,can reflect a certain correlation between files.
Definition 4.(sequential file request sequence)The sequential file request sequence(SFRS)is a sequence in which the request access time interval for adjacent files does not exceed a given threshold size.
Then,SFRSof different edge nodes can be defined as
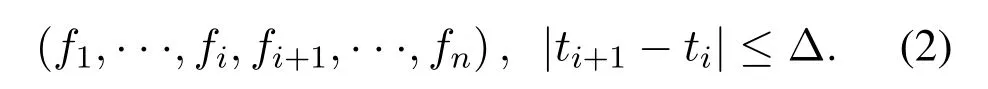
After the sequential file access sequences are extracted,we need to mine the appropriate file access rules.Without loss of generality,the file access probabilities of different edge nodes are considered randomly[17].An abstract representation of file access rule(AR)is first proposed as follows
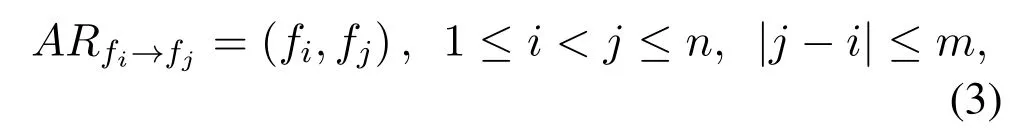
The correlation-aware replica prefetching process is accomplished through the collaboration of PM modules on each edge node.Once a node receives a file prefetching request from another node,it starts the local file prefetching mechanism immediately.Hence,the process of correlation-aware replica prefetching based on file access locality characteristics in an edge cloud scenario is described as follows:
(1) File access requesting.In the edge cloud environment,prefetching modules are deployed on each edge platform.Upon receiving an access request to a filefifrom a job,iffiis not on the local node and belongs to an explicit high-value file,the local node will obtain the address of the remote node holdingfithrough the file location service provided by the central cloud and create a replica offilocally.
(2)Local prefetching module starting.When the local node creates the replica offi,the PM will be triggered to prefetch the implicit high-value files associated withfi.Based on the access rule base mechanism,fiis used as the hash keyword to locate the remote node storing the target rule; and then the local node sends the access rule query request withfias the preorder identification.
(3) Remote prefetching module responding.When the target remote node receives the query request,its PM is also activated immediately.The prefetching engine is responsible for processing the received query task and returning the prefetching file information to the query request node.
(4) Determining the high-value file.Once the local node receives prefetch file messages that meet the prefetching requirements,the prefetching engine will sort all possible files in descending order based on the value of files accessed,and select the file whose value is greater than the specified threshold.
(5) Replicating the selected file in the requester node.The prefetching engine replicates the most related files on based the prefetch file information.If free storage of the prefetch pool is enough,then these new related files are stored;otherwise,some of the existing files are removed on the basis of LRU algorithm to get sufficient space for new replicas.
4.2 Access Rule Management Method Based on Consistent Hashing
Not only does a newly generated access rule need to be stored in the local access rule base,but it also needs to be stored in another appropriate non-local node to satisfy global query requests.To solve this problem,we propose an access rule management method based on consistent hashing(ARMCH).
The ARMCH uniformly distributesNedge cloud nodes in the edge network on a virtual ring,which is a hash ring composed of 232points based on the consistent hashing algorithm.Likewise,various access rules are also mapped to the same hash ring.To obtain a globally unique hash value,the underlying node has the IP address as the hash keyword,while the access rule has the preorder file identifier as the hash keyword.As illustrated in Figure 2,we assume that there are eight underlying edge nodes mapped to different locations of the hash ring by the consistent hashing function.
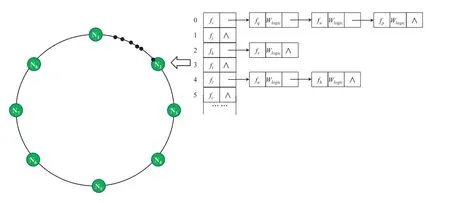
Figure 3. Access rule storage structure based on adjacency list.
For different access rules that have appeared,we use the same hash function to calculate their hash values to determine the positions on the hash ring.Then,we need to store each access rule on the hash ring to the appropriate maintenance node for the sake of management.The management rule is as follows:
Clockwise along the hash ring,each access rule is managed by a node that has the same or closest hash value as the access rule.For instance,the position of the access ruleon the hash ring is between the nodes N1and N8,then the first maintenance node that conforms to the management rule along the ring clockwise is N1.In addition,the maintenance nodes are responsible for periodically updating the managed access rules.
4.3 Access Rule Storage Mechanism
The access rule storage mechanism is not only an important part of the ARMCH method but also has an important impact on the query performance of access rules.Considering the universality and efficiency of the storage mechanism,we take the preorder file identifier of each access rule as the hash keyword and store it to the corresponding maintenance node.On the one hand,different access rules with the same preorder will reside on the same maintenance node;on the other hand,access rules with different preorders but satisfying the ARMCH method will also be stored on the maintenance node.
To cope with the storage and maintenance challenges brought by various access rules,an access rule storage mechanism based on the adjacency list storage structure is presented.Each maintenance node builds its own access rule adjacency table,where the head node is used to store the rule preorder and the table node is used to store different postorders under the same preorder.As depicted in Figure 3,some access rules are located on the hash ring between the nodes N1and N2,so they will be stored and maintained on the node N2according to the ARMCH method.
Different preorder file identities hashing to the same maintenance node are stored in a linear table,while all the postorder file identities associated with the same preorder are stored in a single linked list.The storage node data structure is shown in Figure 4.

Figure 4. The storage node data structure.
In Figure 4,file_IDindicates the stored file identifier,firstis used as the head pointer to store the first address of the linked list of access rules with the same preorder,Wavgrepresents the average support of the corresponding access rule,andnextis the pointer to the next postorder node.
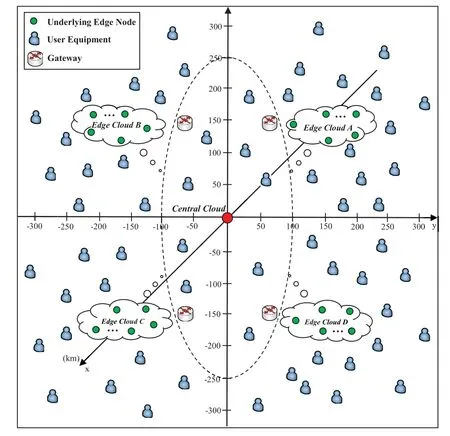
Figure 5. Network deployment scenario.
Typically,the access rule support is used to reflect how frequently it appears in the file access history,that is,the total number of the access rule extracted from all the existing file access sequences.In order to evaluate the implicit value of an access rule more accurately,we propose an approach to calculate the average support of an access rule,which can be expressed as
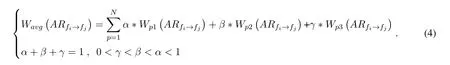
Here,represents the average support of access ruleover the entire edge network,records the number of times that the access ruleappears in thekthcycle before the current moment on the edge cloud nodep.α,β,γdenote different weight parameters respectively.
The average support is a better indicator of the dynamic popularity of files.For the access rules with the same preorder but different postorders,the table nodes are arranged in descending order in the single linked list according to the average support of the access rules.The greater the average support is,the higher the implicit value degree of the file gets.

Algorithm 1.Access rules storage algorithm.Input:the newly generated access rule(fi,fj)Output:result indicating whether the access rule has been successfully stored 1:if FreeStorageSpace ≥Spacethreshold then 2: p fj = CreateTableNode(fj)3: i = LocateHead(AdjList,fi)4:if i /= NULL then 5:p fj.next = AdjList.Head[i].first 6:AdjList.Head[i].first = p fj 7:result = SUCCESSFUL 8:else 9:p fi = CreateHeadNode(fi)10:p fi = AdjList.Head[i+1]11:p ID = fi 12:p fi.file fi.first 13:p fj.next = p fi.first = pfj 14:result = SUCCESSFUL 15:end if 16:else 17: result = FAILED 18:end if 19:return result
Considering the dynamic changes in file access requirements,the average support of relevant access rules needs to be updated periodically,leading to synchronization adjustments of the access rule base that stores the rule on the maintenance node.
In Algorithm 1,there is the pseudo-code for storing access rules algorithm for implicit high-value files.After receiving the access rule (fi,fj) to be stored,the maintenance node will first create a new table nodep_fjfor the postorder file information if there is enough free space.Then,the head nodes in the adjacency list are traversed sequentially.If there is a head node withfias the file identifier,p_fjis inserted into the corresponding single linked list; otherwise,a new header node withfias file identifier must be created in the sequence table of header nodes before the subsequent successor nodep_fjinserted.In the end,a prompt message is returned indicating whether the access rule was successfully stored.
4.4 Access Rule Query Mechanism
As another important component of the ARMCH method,the access rule query mechanism is responsible for querying the local access rule base to determine which files need to be prefetched and returning information about these files to the prefetched request node.The whole querying process is described as follows.First off,suppose nodepis trying to obtain the implicit high-value files associated with filefi.Second,after receiving the local prefetching request,the PM of nodeptakesfias the hash keyword to determine the identity of the global maintenance node and sends the prefetching request to the target node.Third,once the PM of the maintenance node receives the file prefetching request from nodep,it will immediately query its own access rule base for the presence of the corresponding items.In the adjacency list corresponding to the access rule base,if the single linked list of the header node identified byfiis not empty,the PM will first find access rules whose average support is not less than a given threshold,and then send the topranked postorder file identifiers from them to nodep.Lastly,the PM of nodepsuccessfully obtained the file identifiers to be prefetched and start the file location service to create the corresponding replicas locally.
Suppose that the maintenance node storing the requested access rules has been determined according to the ARMCH method.The process of querying access rules on the corresponding maintenance node can be depicted by Algorithm 2.For each newly arrived query request,it is necessary to find all the postorder file identifiers whose preorder isfiin adjacency listAdjList.If the corresponding access rules already exist,the implicit high-value file identifiers of the topKitems that meet the threshold requirement will be returned.Conversely,the return value isNULLif the above criteria are not met.
An example of the access rule query scenario is shown as follows:Suppose node N1is trying to get the implicit high-value files associated with filef2.To begin with,the prefetching engine of node N1will perform a hash retrieval withf2as the keyword to get the identity of the maintenance node of filef2,which is denoted by N2.Secondly,node N1sends a query message to node N2 to check whether there is a single linked list withf2as the head node on node N2,which is actually a set of all access rules withf2as the preorder.Thirdly,all table head nodes will be traversed by the prefetching engine when node N2receives a query message from node N1.If there is a head node identified byf2,the top two ranked postorder file identifiers whose average support meeting the threshold requirement will be returned.Otherwise,a null value will be returned.

Algorithm 2.Access rules query algorithm.Input:the preorder file identifier fi,the access rule adjacency list AdjList Output:the collection of file identifiers to be prefetched PListi[·]1: Array =Search(AdjList,fi)2:if Array /=NULL then 3:for i=1 to lengthArray do 4:if Array[i].Wavg ≥Wthreshold then 5:ArrayNew[i]=Array[i]6:end if 7:end for 8:if ArrayNew /=NULL then 9:PListi[·]=TopK(ArrayNew)10:else 11:PListi[·]=NULL 12:end if 13:else 14: PListi[·]=NULL 15:end if 16:return PListi[·]
As can be seen in Algorithm 2,the response time of querying an access rule is mainly composed of two parts:location time and lookup time.The location time is the time to locate the maintenance node where the access rule resides.It actually represents the routing time of the query message on the hash ring,which is mainly determined by the total number of all edge nodesN.The time complexity of locating process can be denoted asO(logN).The lookup time refers to the time to find the corresponding access rule on the maintenance node,which is mainly related to the number of table head nodesmand table nodesn.The time complexity of the lookup process can be denoted asO(m)+O(n).Thus,the time complexity of the access rules query algorithm can be expressed as
O(logN)+O(m)+O(n).
V.PERFORMANCE EVALUATION
In this section,the setting of the experiment environment is firstly introduced.Then,we validate the effectiveness of the CRP strategy compared with other replica optimization strategies from the aspects of average response time,hit ratio,effective network usage,and replication frequency.
5.1 Experimental Setup
In order to conduct extensive simulations to evaluate the performance of the proposed CRP scheme,we assume that the basic scene for the experiment in this paper consists of one central cloud and four edge cloud platforms.The central cloud rent an Alibaba server while each edge cloud platform has 10 local servers.The network topology for the given scenario is shown in Figure 5,where the central cloud is in the center while four edge cloud platforms are evenly deployed in four different directions.
In this effort,Hadoop is adopted as the experimental platform and deployed in each edge cloud.The evaluations are performed with 3 benchmarks released on PUMA[33],includingtera-sort,word-count,andgrep.The three benchmarks are typical jobs for measuring the performance of Hadoop distributed cluster.tera-sortis used for sorting massive data efficiently;word-countcounts the occurrences of each word in a large collection of documents;whilegrepsearches for a pattern in a large file and is a generic search tool used in many data analyses.Among which,tera-sortis data-intensive workload;word-countis computeintensive workload; whilegrepbelongs to transactional web workload.Each of these benchmarks runs a certain number of jobs on a regular basis,employing Hadoop log files as the input data.For the convenience of analysis and comparison,in addition,we give the following assumptions:for a variety of applications(most of them are data-intensive)in an edge cloud environment,the requested input files are equal in size.Each edge cloud platform contains an equal number of user devices,which are randomly distributed in the edge environment.The detailed experimental settings are presented in Table 1.

Table 1. Experimental settings.
In order to verify the effectiveness of CRP strategy,we compare the proposed approach with existing methods.We implement the following four policies that have different optimization objectives and use different techniques to achieve their goals.
·ACMES[21]:To improve the performance of the mobile edge cloud,the Algorithm of Collaborative Mobile Edge Storage(ACMES)has the ability to achieve a fine trade-off among system reliability,power usage,and the risk of node withdrawal by effectively utilizing local information of nodes.It designs a collaborative storage algorithm that comprehensively considers resource allocation,task scheduling,and heterogeneous information of nodes at the same time for mobile edge cloud.By providing a method that the mobile edge cloud can make a storage scheduling decision at the edge environment directly and execute at the same time,ACMES is able to provide immediate service,unlike conventional methods.
·RPME[26]:In the case of multilaterally high concurrency,a replica placement strategy for mobile media streaming in edge computing(RPME)is presented to solve the problem of trunk network traffic and access latency increasing significantly.A multilevel replica placement model is introduced in RPME.An optimal solution is presented to deal with the replicas based on the block-level storage and define a linear sequence to fetch data from the nearest server.RPME can dynamically place the replicas to improve the performance in edge computing.
·PDR[30]:A new dynamic data replication strategy called Prefetching-aware Data Replication(PDR) is proposed to determine the correlation of data files using the file access history and prefetches the most popular files.First,PDR strategy stores the dependencies between all files in the dependency matrix.Second,PDR strategy determines the most popular group files according to the total average of file accesses.Lastly,due to the restricted storage space of each node,unnecessary replicas are replaced with more popular replicas based on the fuzzy inference system.Furthermore,PDR provides quick access to files on the first request,which is superior to the requestdriven strategies.
·CHCDLOS-Prefetch[31]:A scheduling-aware data prefetching scheme to enhance non-local map task’s data locality in a centralized hybrid cloud (CHCDLOS-Prefetch) is presented to hide network latency and reduce job completion time in Hadoop-based hybrid cloud data access.Considering job level scheduling,data files with high popularity are proactively synchronized beforehand among sub-clouds to strengthen intra subcloud data locality in distributed hybrid cloud.Moreover,input data for non-local map tasks are fetched ahead of time to target compute nodes by making use of idle network bandwidth.Hence,CHCDLOS-Prefetch can improve hybrid cloud performance significantly in data locality and job completion time.
5.2 Average Response Time
Average response time(ART)is defined as the average duration from the job submitting data request to the job completion,which can be expressed as
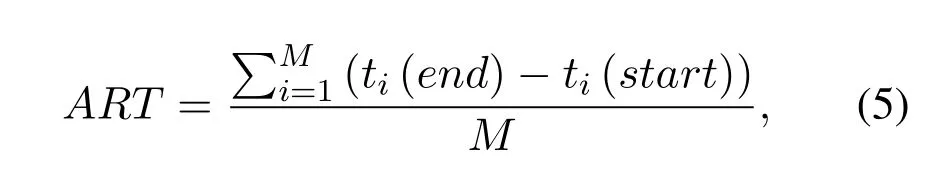
whereti(end) andti(start) represent the end time and start time of jobirespectively.Mdenotes the total number of jobs requesting file access.
Figure 6 gives a comparison for the five replica deployment strategies in terms ofARTwhen performing different types of jobs.It is observed that our CRP strategy shows significantly lessARTthan other methods for most test sets.For thetera-sortjob,the CRP strategy can saveARTby up to 14.5%and 11.4%respectively compared with ACMES and RPME methods,while decreaseARTaround 4.8%and 8.3%than PDR and CHCDLOS-Prefetch strategies separately.The main reason is that thetera-sortjobs spend most of their time on data I/O,our CRP strategy can deep excavate the correlation between files and prefetch corresponding replications to the local edge cloud.Then jobs can access part or all of the input data nearby and thus accelerate theARTsignificantly.For theword-countjob,our CRP strategy can only decrease theARTaround 4.4% at most compared with the baseline algorithms,and its latency is even higher than that of PDR.This is because the CPU computing phase in theword-countjob accounts for a large proportion causing similar performance trends and little performance differences to different replicas strategies.For thegrepjob,CRP can finish jobs 10.5%faster than ACMES and 9.3%faster than RPME,and save about 1.9%and 4.5%job completion time respectively compared with PDR and CHCDLOS-Prefetch.Figure 6 indicates that CRP can provide a certain degree of reduction in response time compared to the baseline methods,although not as significant as for thetera-sortjob.Because the replication mechanism has limited performance gains for the CPU computing phases of jobs,our CRP strategy is more suitable for the data-intensive scenarios.Taking more account of the users’ preferences,CRP has the ability to discover more implicit high-value files for replication;this hence reduces average response time and latency significantly for data-intensive workloads.Accordingly,we choosetera-sortbenchmark in other tests to further assess the performance of CRP.
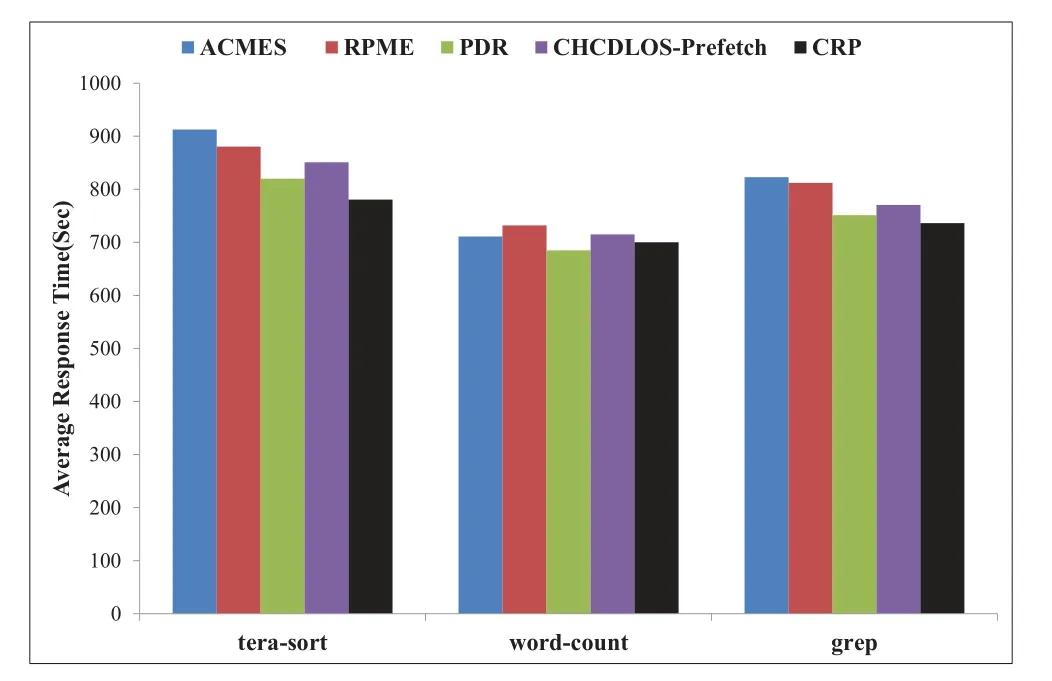
Figure 6. Average response time comparison for various replica deployment strategies under different benchmarks.
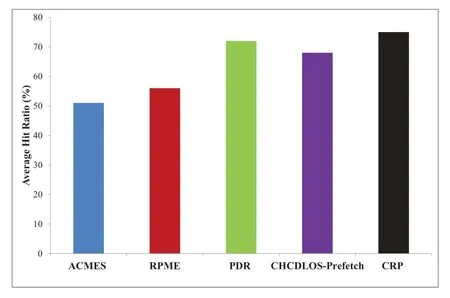
Figure 7. The comparison of average hit ratio for various replica deployment strategies.
5.3 Average Hit Ratio
Average hit ratio(AHR)indicates the proportion of the local file accesses to all file accesses,which is adopted as a metric to measure the locality level of replica deployment strategies.AHRcan be defined as
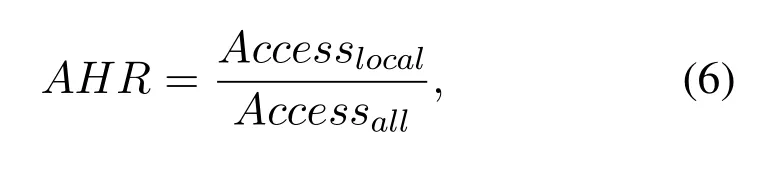
whereAccesslocaldenotes the number of times that file accesses occur in the local edge cloud whileAccessalldenotes the total number of file access requests in the entire edge cloud environment.
Figure 7 shows the average hit ratio comparison of proposed against other existing approaches.We can see that ACMES has the lowestAHR.The main reason is that ACMES is not combined with any prediction mechanism,leading to a certain degree of blindness.The CRP strategy achieves the maximumAHRcompared to other strategies.The reason is that in the initial stage,it can more thoroughly discover the files with the highest access probability and prefetch them.Consequently,theAHRof CRP increases as the number of local accesses increases.As a result,predicting future access requests based on the correlation-aware replica prefetching scheme contributes a lot for raising the replication accuracy of CRP.

Figure 8. The comparison of effective network utilization for various replica deployment strategies.
5.4 Effective Network Usage
Effective network usage (ENU) reveals the ratio of transferred files to all requested files,which can be denoted by

whereNumremotedenotes the number of remote file accesses,Numlocalis the number of local file accesses,andNumrepliadenotes the number of replications.
The value ofENUranges from 0 to 1.The higher theENUvalue is,the lower the utilization of network bandwidth gets.Compared to ACMES and RPME,theENUof PDR respectively reduced around 20.2%and 13.3%on average.Since PDR preplans some replicas to meet the needs of future job requirements,hence the local availability of necessary files is improved.The results in Figure 8 reveal that theENUof CHCDLOSPrefetch is lower by 10.4% compared to PDR only when the number of jobs is 500.Since the preliminary replica placement using idle network bandwidth will improve the utilization of network bandwidth more obviously in the case of load balancing.As observed from Figure 8,theENUof CRP is lower than other strategies,and the main reason is that the high-demand files are prefetched and available on the local node in most cases,which significantly decreases the network transfer volume of remote files.
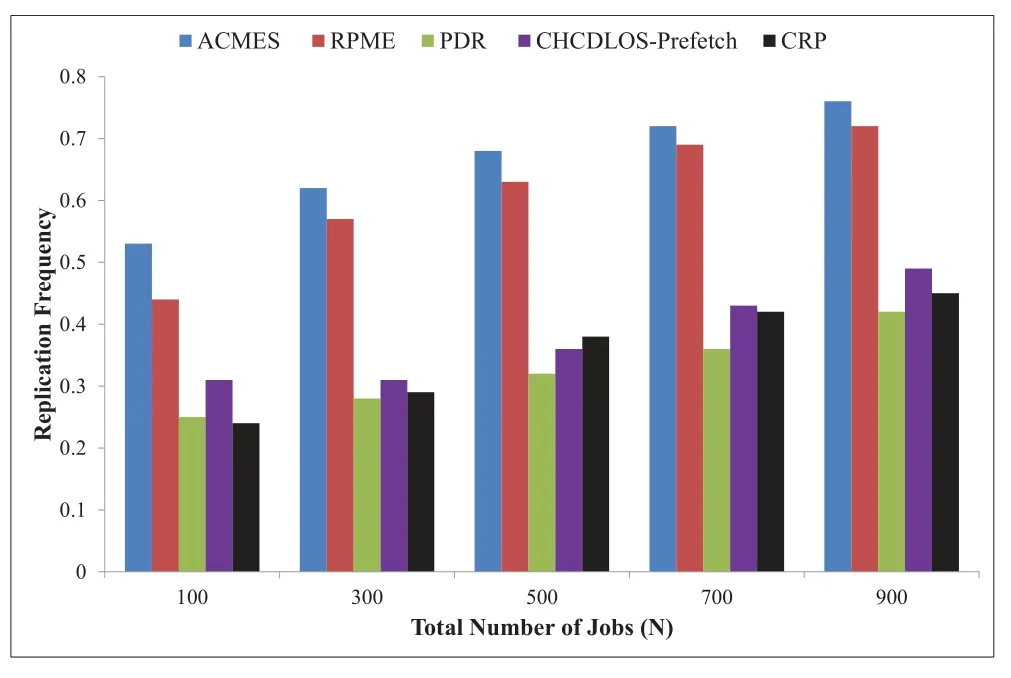
Figure 9. The comparison of replication frequency for various replica deployment strategies.
5.5 Replication Frequency
Replication frequency (RF) depicts how many replication operations are triggered per unit time.As the replica creation process will incur additional network overhead and consume a certain amount of storage resources,a higherRFvalue usually represents more network and storage resource consumption.RFin replication schema can be expressed as

whereNumrepliarepresents the total number of replicas produced during that period,tendandtstartdenote job end time and job start time respectively.
Figure 9 indicates theRFfor different strategies.TheRFof ACMES is always higher than 0.53,which means that at least 0.53 replicas are created for each file access.Both ACMES and RMEP strategies ignore the effect of file popularity on replica selection,leading to frequent replica replacement.As the number of jobs goes from small to large,theRFof PDR never exceeds 0.42 and theRFof CHCDLOS-Prefetch is no more than 0.5,even slightly lower than theRFof CRP in some scenarios.There are two main reasons for this phenomenon.For one thing,the dynamic update of access rules usually leads to fluctuations in the replication frequency of CRP; for another,CRP strategy creates replicas of implicit high-value file additionally,which sacrifices some network overhead and local storage resources in exchange for further reduced access latency.However,triggering the replication process needs to satisfy the specified conditions given by CRP,and the replication is not triggered every time a file access request occurs.Hence,theRFof CRP can still be maintained at a reasonable level.
In conclusion,the comparative analysis of the above experiments shows that CRP strategy can achieve lower access latency than other common replication algorithms within tolerable resource overhead.The main reasons can be summarized as follows:
(1)CRP strategy leverages the principle of file correlation such as time locality,geographical locality,and file locality.It predicts file access requirements of local nodes in the future and prefetches files with high file value to local so that the number of local file accesses can be maximized.Thus,theAHRis improved and theENUgoes down.This methodology significantly decreases average response time and access latency because of the comprehensiveness and rationality of the prefetching mechanism.
(2)CRP strategy adopts an access rule management method based on consistent hashing to efficiently store and query file correlation information.To be more dynamic and more adaptable to user behavior,the average support for access rules is presented as a measure of the recent file access popularity.Therefore,the proposed approach can achieve the goal of accelerating access to implicit high-value files and reduce unnecessary replications.
VI.CONCLUSION
In this work,according to the principle of file correlation,we propose a correlation-aware replica prefetching (CRP) strategy to decrease access latency in the edge cloud.Firstly,based on the in-depth study of file access characteristics,we classify the files with high access probability into two types:explicit high-value files and implicit high-value files.Second,we design a correlation-aware replica prefetching overall architecture and explore a collaborative prefetch process to detail how the file prefetch mechanism works.Third,to speed up the acquisition of implicit high-value files,an access rule management method based on consistent hashing is proposed,and then an access rule storage mechanism and a query mechanism based on adjacency list storage structure are further presented.Finally,simulation results indicate that the CRP strategy outperforms the others in most of the investigated performance metrics,and effectively reduces the access latency,and improves the QoS in the edge cloud.Considering that disk-based data access speed is becoming a bottleneck restricting the execution time of jobs,we will focus on edge caching technology to provide best-effort latency improvement and cost reduction in future work.
ACKNOWLEDGEMENT
This work was supported in part by the National Natural Science Foundation of China (No.61602525,No.61572525),in part by the Research Foundation of Education Bureau of Hunan Province of China(No.19C1391),and in part by the Natural Science Foundation of Hunan Province of China(No.2020JJ5775).

- China Communications的其它文章
- Secure Transmission in Downlink Non-Orthogonal Multiple Access Based on Polar Codes
- M2LC-Net:A Multi-Modal Multi-Disease Long-Tailed Classification Network for Real Clinical Scenes
- DEEPNOISE:Learning Sensor and Process Noise to Detect Data Integrity Attacks in CPS
- Beamforming Optimization for RIS-Aided SWIPT in Cell-Free MIMO Networks
- Security Risk Prevention and Control Deployment for 5G Private Industrial Networks
- Cost-Minimized Virtual Elastic Optical Network Provisioning with Guaranteed QoS